

[AINews] Truth in the time of Artifice
A quiet day lets us question the nature of reality
“If the news is fake — imagine history.” — AmuseChimp via Naval
The first news item prompting this editorial is the unofficial but credible reporting that Cursor is now at $2B ARR, and raising at $50B, contra a couple weeks of headlines that Cursor churn is ramping up. In this case, a filter bubble cropped up on X, where novelty and scandal is rewarded and truth was hard to glean.
The second news item is the Ars-Technica-Scott-Shambaugh saga, which, there is no polite way to say this, is a veritable clusterfuck of open source abuse, AI Clawbots, and the journalist covering it publishing made up AI quotes, eventually getting fired. As a bonus, human commentors also hallucinated more untruths.
The third is a recent episode of a top podcast featuring the idea that the best way to launch products is to make 20 different fake TikTok videos of an app and only building it after the videos go viral, instead of building first and then marketing. (We first covered this idea in the Hyperstitions of Moloch, and it obviously works.)
Left unchecked, the net result of all this is a declining trust in all media, which shatters consensus reality and therefore civil society — I do not have to care what you think is true if I can simply assert my truth louder.
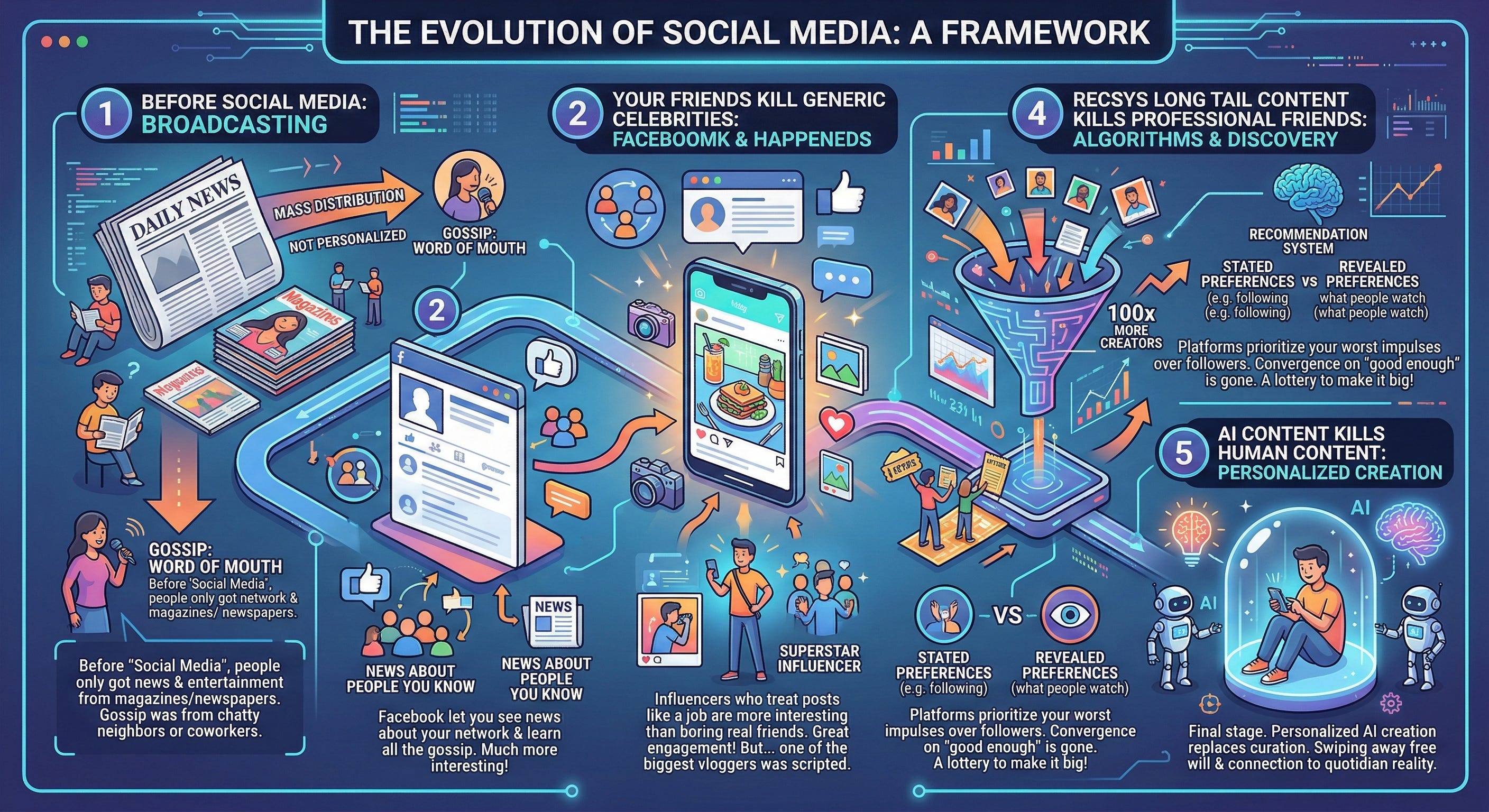
It would be different if we voted with our thumbs. Dead Internet Theory is not solely caused by AI, but is accelerated by it. I am reminded of an old social media evolution framework that goes like this:
Before “social media”, people only got their news entertainment from magazines and newspapers — designed for mass distribution, so not at all personalized. Gossip was only by literal word of mouth, from a chatty neighbor or coworker.
Your Friends kill Generic Celebrities: Then Facebook happened, and suddenly you could see news about people you know/might meet and learn all the gossip about them. So much more interesting!
Professional Friends kill Real Friends: Your real friends are pretty boring. My Instagram posts about what I had for lunch aren’t as interesting as someone who treats their posts like a job; every photo filtered, every story boarded. The influencers best at this become superstars. Great engagement for everyone! But also - is it a surprise that one of the biggest vloggers turned out to be… scripted?
Recsys Long Tail Content kills Professional Friends: The problem with professional friends is that they had the same problem as the generic celebrities of old — they converge on “merely good enough” for most. They also bring new problems: even when being paid millions they still don’t produce enough content , and, yet, they are also divas who wield too much power over the platforms. So: the platforms stop prioritizing your follow graph (stated preferences) and start feeding your worst impulses (revealed preferences). Another huge jump in engagement, and 100x more creators are given the lottery ticket to Make It Big!
AI Content kills Human Content: The final stage — personalized creation replacing curation. Everyone lives in a Truman Show cage of their own making, happily swiping away their free will and connection to quotidian reality.
We’re surely stepping closer and closer to this every day — as newswriters attempting to Scale Without Slop, this is a problem we’re trying to navigate and create new solutions for.
At the same time it has never been easier to signal taste and human effort — a lesser newsletter might leave you with a slop image like this:
But for now it still takes a human to make a truly useful graphic:

AI News for 2/27/2026-3/2/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 31899 messages) for you. Estimated reading time saved (at 200wpm): 2895 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Qwen 3.5 “small” open models: long-context + multimodal on-device is getting real
Qwen3.5-0.8B / 2B / 4B / 9B released (Base + Instruct): Alibaba launched a compact series positioned as “more intelligence, less compute,” with native multimodal and scaled RL, explicitly targeting edge + lightweight agent deployments (Alibaba_Qwen). Community amplification highlights 262K native context (extendable to 1M) and competitive scores reported in tweet summaries (e.g., “82.5 MMLU-Pro,” “78.4 MMMU,” “97.2 CountBench”)—treat these as vendor/secondary claims until you read the model cards (kimmonismus).
Architecture notes emerging via commentary: Multiple tweets converge on Qwen’s move toward hybrid / non-orthodox attention, with “hybrid models” coming back in 3.5 vs the earlier “Thinking vs Instruct” split in Qwen3 updates (nrehiew_). A more detailed (but still unofficial) breakdown claims a Gated DeltaNet hybrid pattern: “3 layers linear attention : 1 layer full attention” to keep memory flat while preserving quality (LiorOnAI).
Practical deployment caught up fast:
Ollama:
ollama run qwen3.5:9b|4b|2b|0.8b, with tool calling + thinking + multimodal surfaced in the packaging (ollama, ollama).LM Studio: Qwen3.5-9B touted as ~7GB local footprint (Alibaba_Qwen).
iPhone on-device demo: Qwen3.5 2B 6-bit running with MLX on “iPhone 17 Pro” is getting framed as an “edge breakthrough” (adrgrondin, kimmonismus).
Gotcha for evaluators: “Reasoning disabled by default” on the small models; enable via chat-template kwargs (example given for llama-server / Unsloth docs) (danielhanchen).
Coding agents + reliability + “availability is the new frontier”
Codex 5.3 and coding eval chatter: Anecdotal reports of Codex 5.3 solving “promising” tasks and pushing benchmarks like WeirdML (79.3% claim, leading v. Opus 4.6 at 77.9%) while noting Gemini peak performance may still be higher (theo, htihle). Also speculation about nearing saturation on WeirdML v2 (teortaxesTex).
“We’re about to hit 1 9 of availability”: The emerging ops pain point is not only model quality but downtime and degraded UX; the theme repeats across memes and serious complaints about Claude outages and productivity impacts (ThePrimeagen, Yuchenj_UW, Yuchenj_UW).
Agent observability / evaluation becomes a first-class problem:
“Since we’re all agent managers now, what’s your favourite way to get observability?” (_lewtun).
Agent reliability is cross-functional (can’t “engineer” your way out of bad eval criteria; PMs/domain experts must own success definitions) (saen_dev).
Practical eval advice: define success before building; start with deterministic graders; use LLM judges for style; grade the produced artifact not the path (_philschmid).
AGENTS.md / SKILL.md as “guardrails,” not magic:
A reported Codex study across 10 repos / 124 PRs: AGENTS.md reduced median runtime ~28.6% and tokens ~16.6%, mostly by reducing worst-case thrashing rather than uniform gains (omarsar0).
Carnegie Mellon-style loop for SKILL.md improvement in production: “log → evaluate → monitor → improve” with an OSS example (PR review bot) (gneubig).
Anthropic-as-coding-org tension: A viral datapoint claims “80%+ of all code deployed is written by Claude Code,” paired with concern that speed may be coming with reliability regressions (GergelyOrosz). Separate threads discuss Claude Code adoption inside major companies and “supervision” replacing manual coding (_catwu, Yuchenj_UW).
Infra + local AI hardware: Apple Neural Engine cracks, Docker/vLLM on macOS, and “AI infrastructure year”
Reverse-engineering Apple’s Neural Engine for training: A highly engaged thread claims a researcher built a transformer training loop on the ANE using undocumented APIs, bypassing CoreML; heavy ops on ANE, some gradients still on CPU. Also contains efficiency claims like “M4 ANE 6.6 TFLOPS/W vs 0.08 for A100” and “38 TOPS is a lie—real throughput 19 TFLOPS FP16”—these specifics should be verified against the repo/paper, but the meta-point is: on-device training/fine-tuning might be opened up (AmbsdOP, plus ecosystem note AmbsdOP; additional technical summary LiorOnAI).
macOS local serving gets smoother: Docker Desktop “Model Runner” adds support to run MLX models with OpenAI-compatible API workflows; positioned as a practical unlock for Apple Silicon dev loops (Docker).
Inference hardware divergence: A GPU vs Taalas HC explainer contrasts software-executed models on GPUs (HBM streaming + kernel scheduling bottlenecks) vs “model-as-hardware” ASIC with weights in mask ROM; claims 16–17k tok/s per user for HC1 with tradeoff “one chip = one model” (TheTuringPost).
Open-source perf tooling: AMD open-sourced rocprof-trace-decoder (SQTT trace defs) enabling deeper instruction-level timing traces; framed as AMD tracing infra being “better than NVIDIA’s” (tinygrad).
AI infra as strategic theme: Zhipu’s “2026 is the year of AI infrastructure” is more slogan than spec, but fits the overall signal: reliability + cost + tooling now dominate marginal model improvements (Zai_org).
New research + benchmarks: transformer scaling theory, MuP edge cases, CUDA-kernel RL, and “bullshit detection”
Transformer scaling theory refresher: “Effective Theory of Wide and Deep Transformers” (Meta) re-circulated as a 60+ page analysis of forward/backward signal propagation, width scaling rules, hyperparameter scaling, NTK analysis, and optimizer behavior (SGD vs AdamW), with validation on vision/language transformers (TheTuringPost, arXiv link tweet).
Beyond MuP / Muon stability corner cases: Discussion of stability metrics for Embedding / LM head / RMSNorm layers and why embedding + LM head can “not play well with Muon” (Jianlin_S).
CUDA Agent (ByteDance): Widely shared as a meaningful step beyond “code that compiles” toward “code that’s fast,” using agentic RL with real profiling-based rewards. Claimed SOTA on KernelBench, big gains vs
torch.compile, and competitive vs frontier LLMs on hardest kernels (HuggingPapers, deep thread BoWang87).BullshitBench v2: Benchmark update adds 100 new questions split across coding/medical/legal/finance/physics, tests 70+ model variants, and claims reasoning often hurts; Anthropic models allegedly dominate and OpenAI/Google are “not improving” on this benchmark (petergostev, reaction scaling01).
Scheming eval realism: Advice that “contrived environments” can invalidate scheming results; emphasizes careful environment design (NeelNanda5).
Agents + product/toolchain releases: repo graphs, Stripe LLM billing proxy, LangChain refresh, Llama.cpp packaging
GitNexus (browser-only repo knowledge graph + “graph RAG” via Cypher): Parses repos into an interactive D3 graph, stores relations in embedded KuzuDB, and answers queries via graph traversal (Cypher) instead of embeddings; notable for doing it in-browser with Web Workers and MIT licensing (MillieMarconnni).
Stripe-style billing for LLMs: Launches “billing for tokens” where you pick models, set markup, route calls via Stripe’s LLM proxy, and record usage automatically—an indicator that “LLM ops” is moving into standard SaaS finance plumbing (miles_matthias).
LangChain rebrand / consolidation: “Meet our final form” relaunch of LangChain’s web presence (signal is primarily product/positioning, not a spec drop) (LangChain).
llama.cpp distro packaging: Request for feedback on official Debian/Ubuntu packages—small, but meaningful for mainstreaming local inference tooling (ggerganov).
MCP vs “Agent Skills” clarification + Weaviate skills repo: Clean distinction: MCP servers as deterministic API interfaces vs markdown “skills” as behavior guidance; Weaviate publishes skills-based integration patterns for common agent tools (weaviate_io).
US DoW–OpenAI–Anthropic “supply chain risk” saga: contract language, surveillance loopholes, and policy trust boundaries (high-level)
Stratechery frames a standoff: Anthropic vs DoW is positioned as a misalignment between legitimate concerns and government reality (stratechery).
Reporting disputes OpenAI’s “red lines” framing: The Verge claims DoD didn’t agree to the red lines the way OpenAI implied (haydenfield). Separate threads emphasize: without full contract text, it’s hard to validate any public claim about enforceability or “freezing” laws in time (jeremyphoward).
Sam Altman posts contract amendment language: Adds explicit prohibition on “intentional” domestic surveillance of US persons, including via commercially acquired identifiers, and says intelligence agencies (e.g., NSA) are excluded without follow-on modification; also acknowledges Friday announcement was rushed (sama, additional principles post sama).
Pushback: “intentional/deliberate” may preserve the classic “incidental collection” loophole: Multiple legal-minded threads argue the amendment may still allow broad collection if framed as incidental, and that “metadata/hashed identifiers” can evade “personal or identifiable” definitions. Repeated call: independent red-teaming by counsel, and ideally full contract review (j_asminewang, David_Kasten, justanotherlaw, _NathanCalvin).
Anthropic safeguards claims: Anthropic-adjacent staff dispute a narrative that Anthropic offered an unconstrained “helpful-only” natsec model; claim Claude Gov includes additional training + safeguards + classifier stack (sammcallister).
Policy meta: A recurring engineering-relevant point is that governance and contract semantics are becoming production constraints on model deployment—no longer “PR side quests.” See also the “AI politics fissure is taking advanced AI seriously vs not” framing (deanwball).
Top tweets (by engagement, technical-focused)
Qwen 3.5 Small Model Series launch (0.8B/2B/4B/9B, multimodal, scaled RL, Base models too) — @Alibaba_Qwen
Reverse-engineered Apple Neural Engine; training loop on ANE — @AmbsdOP
Qwen3.5 small models now in Ollama — @ollama
Sam Altman: DoW contract amendment language re domestic surveillance + intel agency scope — @sama
CUDA Agent: RL for high-performance CUDA kernel generation via profiler-based reward — @BoWang87
“80%+ of code deployed is written by Claude Code” + reliability concern — @GergelyOrosz
GitNexus: in-browser repo → knowledge graph + Cypher graph-RAG agent — @MillieMarconnni
AI Reddit Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.