

AI News for 2/10/2026-2/11/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (256 channels, and 7988 messages) for you. Estimated reading time saved (at 200wpm): 655 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
As we mentioned yesterday, China open model week is in full swing. Today was Z.ai’s turn to launch their big update before the Big Whale. Per the GLM-5 blogpost:
Opus-class, but not a 1T super model like Kimi or Qwen. Compared to GLM-4.5, GLM-5 scales from 355B parameters (32B active) to 744B parameters (40B active), and increases pre-training data from 23T to 28.5T tokens.
GLM-5 also integrates DeepSeek Sparse Attention (DSA), significantly reducing deployment cost while preserving long-context capacity. (prompting comments on the DeepSeek total victory in open model land)
Decent scores on internal coding evals and the standard set of frontier evals, notably claiming SOTA (among peers) on BrowseComp and top open model on Vending Bench 2.
Similar to Kimi K2.5, they are also focusing on Office work (PDF/Word/Excel), just being much less flashy about it, but
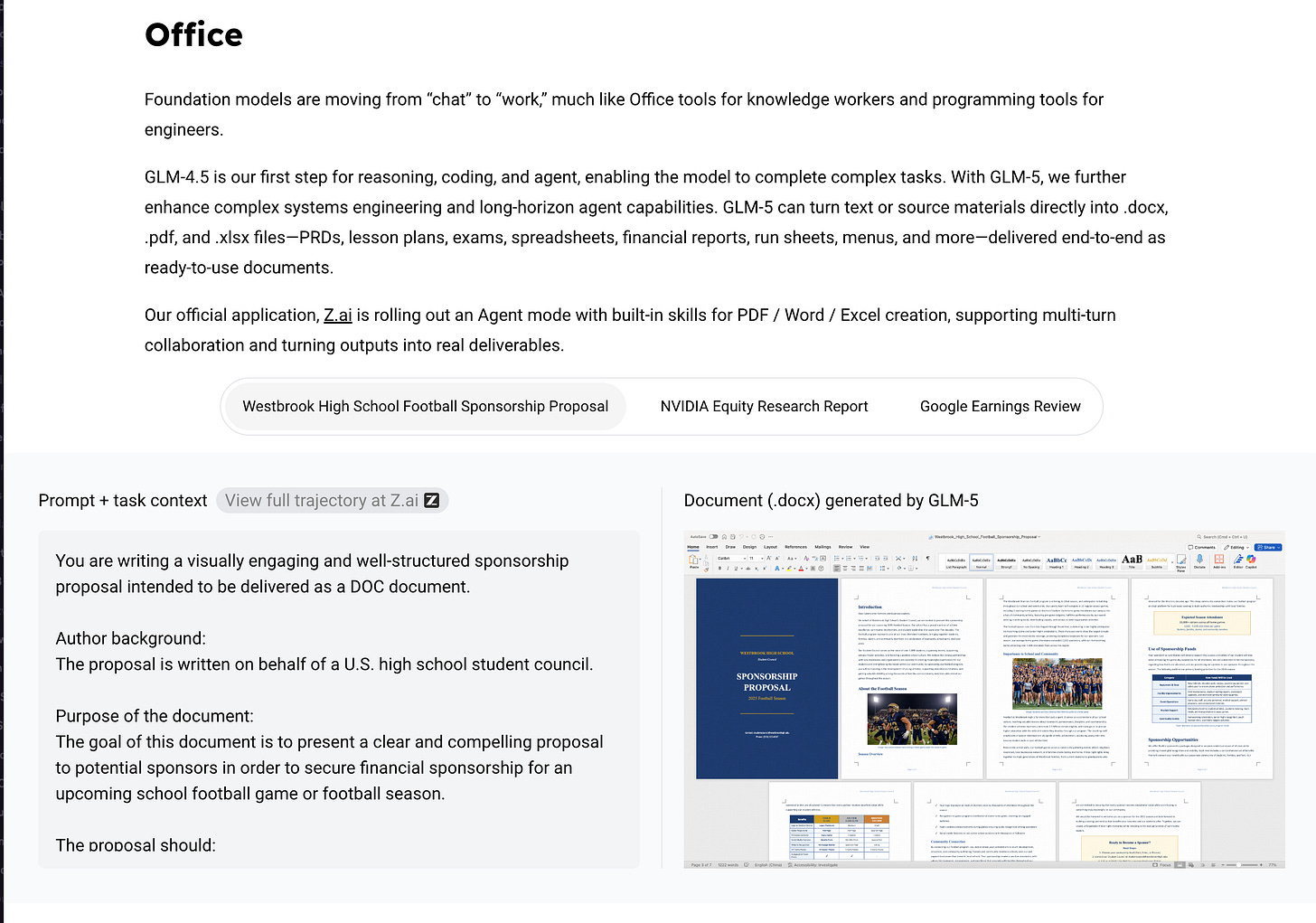
However it is still pretty good, as GDPVal-AA, the defacto “white collar work” benchmark, does rank it above Kimi K2.5:
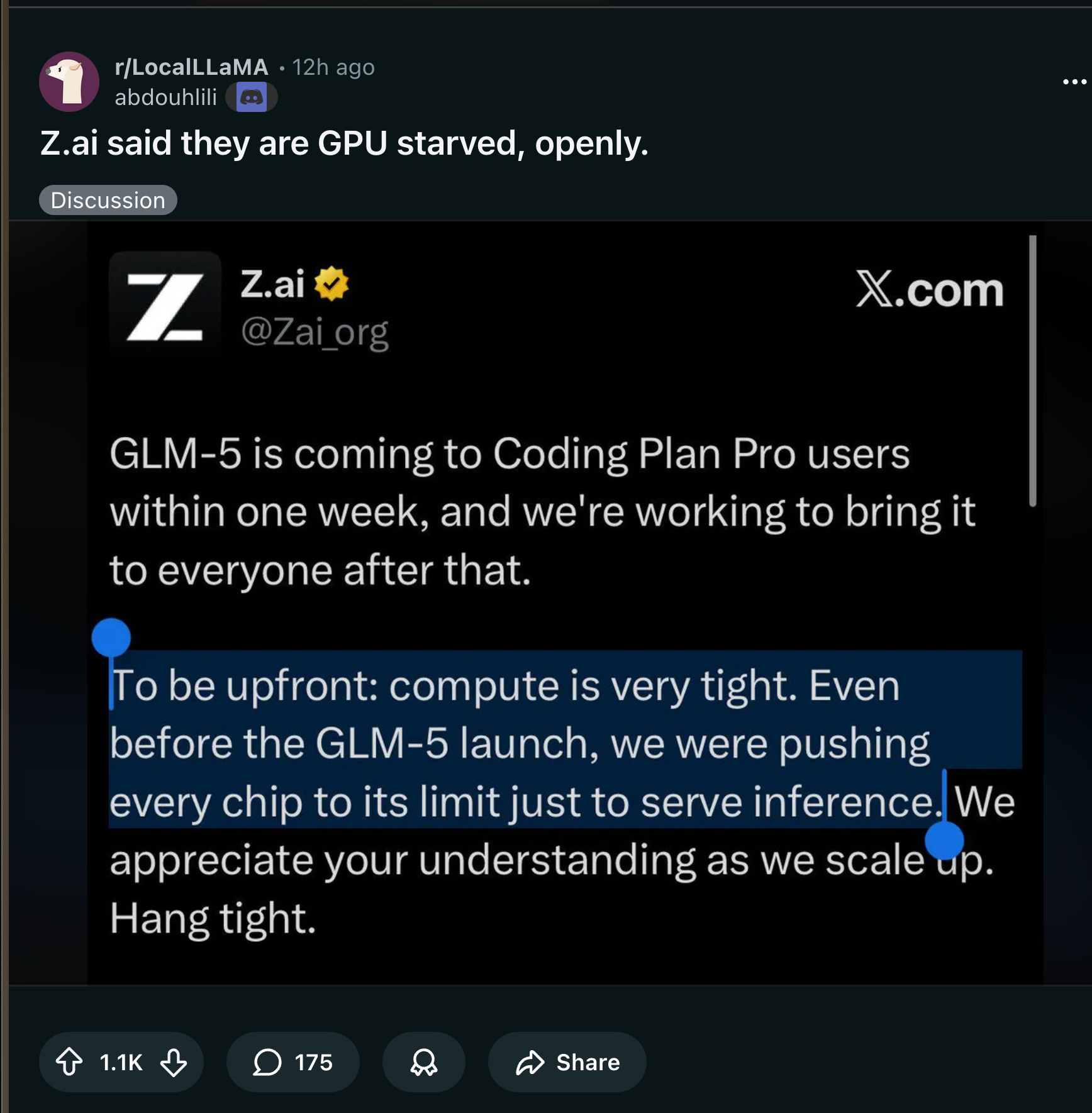
A big part of the Reddit conversations centered around how they are running into compute constraints on their inference service:
AI Twitter Recap
Zhipu AI’s GLM-5 release (Pony Alpha reveal) and the new open-weight frontier
GLM-5 launch details (and what changed vs GLM-4.5): Zhipu AI revealed that the previously “stealth” model Pony Alpha is GLM-5, positioned for “agentic engineering” and long-horizon tasks (Zai_org; OpenRouterAI). Reported scaling: from 355B MoE / 32B active (GLM-4.5) to 744B / 40B active, and pretraining from 23T → 28.5T tokens (Zai_org). Key system claim: integration of DeepSeek Sparse Attention to make long-context serving cheaper (scaling01; lmsysorg). Context/IO limits cited in the stream of posts: 200K context, 128K max output (scaling01).
Availability + “compute is tight” reality: GLM-5 shipped broadly across aggregation/hosting quickly—OpenRouter (scaling01), Modal (free endpoint “limited time”) (modal), DeepInfra (day-0) (DeepInfra), Ollama Cloud (ollama), and various IDE/agent surfaces (e.g., Qoder, Vercel AI Gateway) (qoder_ai_ide; vercel_dev). Zhipu explicitly warned that serving capacity is constrained, delaying rollout beyond “Coding Plan Pro” and driving pricing changes (Zai_org; Zai_org; also “traffic increased tenfold” earlier: Zai_org).
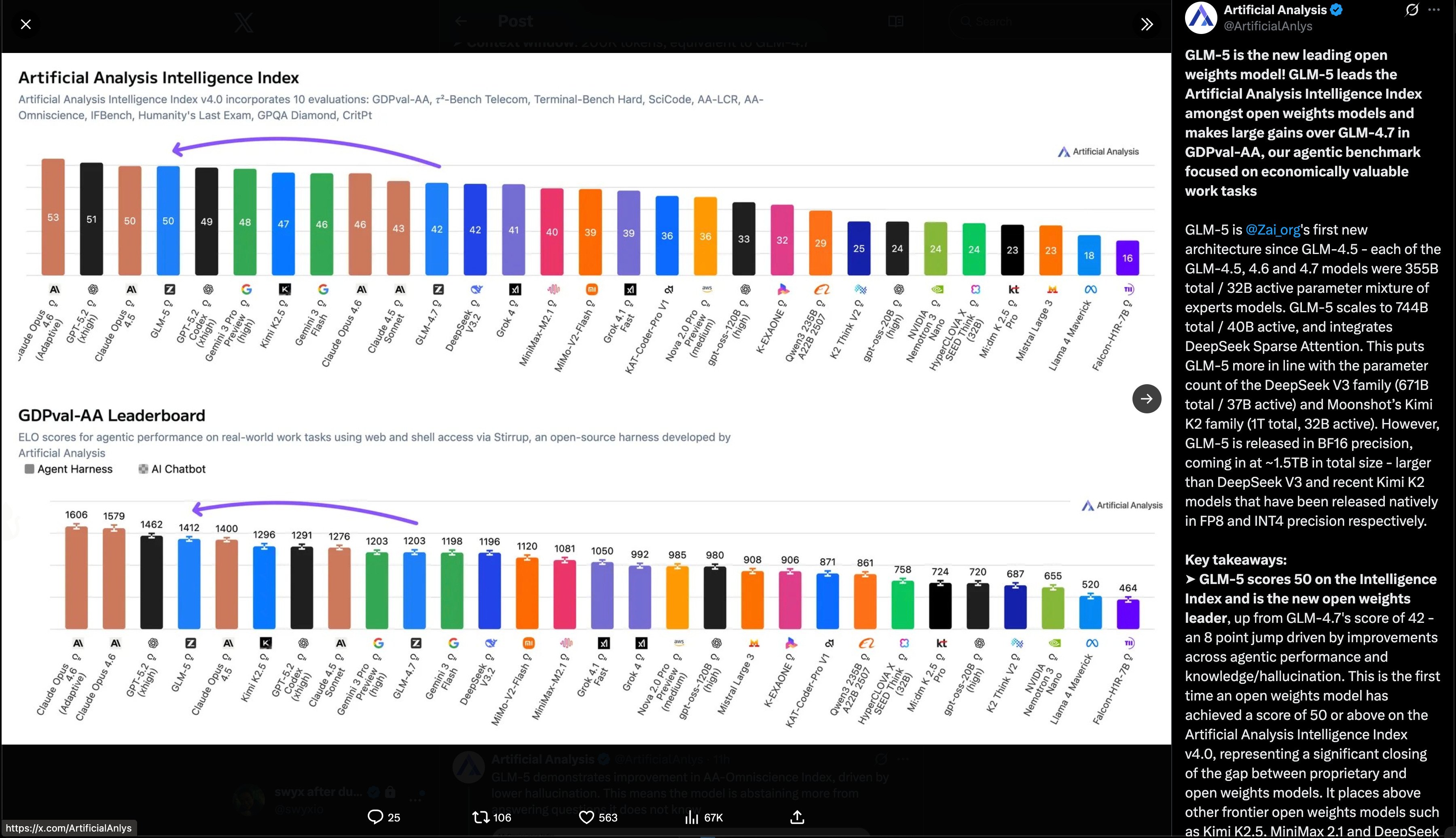
Benchmarks and third-party positioning (with caveats): There’s a dense cascade of benchmark claims (VendingBench, KingBench, AA indices, Arena). The most coherent third-party synthesis is from Artificial Analysis, which calls GLM‑5 the new leading open-weights model on its Intelligence Index (score 50, up from GLM‑4.7’s 42), with large gains on agentic/econ tasks (GDPval-AA ELO 1412, behind only Opus 4.6 and GPT‑5.2 xhigh in their setup), and a major hallucination reduction (AA‑Omniscience score -1, “lowest hallucination” among tested models) (ArtificialAnlys). They also note the operational reality: released in BF16 (~1.5TB), implying non-trivial self-hosting compared with models released natively in FP8/INT4 (ArtificialAnlys).
License + ecosystem integration: Multiple posts highlight permissive MIT licensing and immediate tooling support across inference stacks: vLLM day‑0 recipes, including DeepSeek Sparse Attention and speculative decoding hooks (vllm_project); SGLang day‑0 support and cookbook (lmsysorg); and broad community distribution on HF/ModelScope (Zai_org; mervenoyann). A nuanced take: GLM‑5’s MIT license is praised as “truly permissive,” while comparisons point out GLM‑5 lacks vision, and BF16-to-quantized comparisons may reshuffle rankings vs models released natively quantized (QuixiAI).
Open leaderboard momentum: GLM‑5 reached #1 among open models in Text Arena (and ~#11 overall in that snapshot) (arena). Multiple posters frame this release as another data point in an accelerating China-driven open ecosystem cycle (“bloodbath”: DeepSeek + MiniMax + GLM) (teortaxesTex; rasbt).
DeepSeek “V4-lite” / 1M context rollout, attention as the differentiator, and inference stack fixes
What actually “dropped”: Several tweets report DeepSeek updating a chat experience to 1M context with a May 2025 cutoff; early observers suspected V4 but the model “doesn’t admit it” and rollout is uneven across app vs API (teortaxesTex; teortaxesTex). Later, a more specific claim appears: “V4 Lite now live… 1M context length… text-only… Muon + mHC confirmed; larger version still on the way.” (yifan_zhang_).
Attention upgrades seen as the real milestone: A recurring theme is that DeepSeek has “frontier-level attention,” with the model behaving proactively in long contexts (not just retrieval, but “inhabits a context”), and speculation that this resembles a mature sparse/NSA-like approach rather than vanilla block sparsity (teortaxesTex; teortaxesTex; teortaxesTex). Others corroborate “first truly capable 1M context model out of China” impressions via long-context tests (Hangsiin).
Serving throughput gotchas (MLA + TP): A concrete systems insight: for MLA models with one KV head, naïve tensor parallelism wastes KV cache memory (redundant replication). A proposed fix shipped in SGLang: DP Attention (DPA) “zero KV redundancy” + a Rust router (“SMG”) claiming +92% throughput and 275% cache hit rate (GenAI_is_real). This is one of the few tweets that directly ties model architecture quirks to cluster-level throughput losses and a specific mitigation.
DeepSeek’s influence on open MoE recipes: A widely shared summary claims DeepSeek innovations shaped “almost every frontier open LLM today”—fine-grained sparse MoE with shared experts, MLA, sparse attention in production, open reasoning (R1), GRPO as a foundation RL algorithm, plus infra like DeepEP (eliebakouch). Even if some “firsts” are debatable, it captures the sentiment: DeepSeek is viewed as an unusually high-leverage open contributor.
MiniMax M2.5 / StepFun / Qwen: fast coding models, cost pressure, and benchmark jockeying
MiniMax 2.5 “incoming” and agent distribution: MiniMax teased and then shipped M2.5, with availability through MiniMax Agent apps and partner surfaces (SkylerMiao7; MiniMaxAgent). The team explicitly frames training as a tradeoff between shipping and “the more compute we put in, the more it keeps rising” (SkylerMiao7).
StepFun-Flash-3.5: Claimed #1 on MathArena, with links to a tech report and OpenRouter listing (CyouSakura). Teortaxes’ commentary emphasizes unusually strong performance for “active parameter count” plus high speed, encouraging people to try it despite shortcomings (teortaxesTex).
Qwen Image bugfix + Qwen3-Coder-Next mention: Alibaba shipped a patch in Qwen-Image 2.0 for classical Chinese poem ordering and character consistency in editing (Alibaba_Qwen). Separately, a newsletter item points to Qwen3-Coder-Next (80B) claiming 70.6% SWE-Bench Verified and 10x throughput for repo-level workflows (dl_weekly). (This is thinly sourced in this dataset—only one tweet—so treat as a pointer, not a validated roundup.)
Cost/latency as the wedge: Multiple posters argue Chinese labs can deliver “~90%” capability at 1/5 to 1/10 the price, especially for coding, which would reshape market share if sustained (scaling01). This is reinforced by GLM‑5’s published API pricing comparisons and distribution on low-cost routers (scaling01; ArtificialAnlys).
Video generation shockwave: SeeDance v2, PixVerse R1, and “IP constraints” as a structural advantage
SeeDance v2.0 as the standout: A large chunk of the timeline is community astonishment at SeeDance v2.0 quality (“passed uncanny valley,” “touring-test for text2video”), plus discussion of opacity/PR issues and temporary downtime on BytePlus (maharshii; kimmonismus; swyx). One practical datapoint: a 15s gen quoted at $0.72 with token-based pricing assumptions (TomLikesRobots).
Video reasoning tests: One user compares SeeDance vs Veo on a “tic tac toe move coherence” task, claiming SeeDance sustains ~5 coherent moves where Veo sustains 1–2 (paul_cal). This is anecdotal but notable: it’s probing temporal consistency as “reasoning,” not just aesthetics.
Structural explanation: training data / IP: A thread argues the gap in generative media may be “structural” because Chinese models train with fewer IP constraints; Western labs cannot, implying regulation at the model level becomes unenforceable once open weights proliferate (brivael). Whether you agree or not, it’s one of the few attempts to explain why capability could diverge beyond “talent/compute.”
PixVerse R1: High-engagement marketing claim: “real-time interactive worlds in 720P” (PixVerse_). The tweet is promo-heavy, but it signals demand for interactive, real-time media generation as a distinct category from offline cinematic clips.
Agents, coding workflows, and the new “malleable software” toolchain
Karpathy’s “rip out code with agents” workflow: A concrete example of LLMs changing software composition: using DeepWiki MCP + GitHub CLI to interrogate a repo (torchao fp8), have an agent “rip out” only the needed implementation into a self-contained file with tests, deleting heavy dependencies—and even seeing a small speed win (karpathy). This points at an emerging style: repo-as-ground-truth docs, and agents as refactoring/porting engines.
OpenAI: harness engineering and multi-hour workflow primitives: OpenAI DevRel pushed a case study: 1,500 PRs shipped by “steering Codex” with zero manual coding, and separately published advice for running multi-hour workflows reliably (OpenAIDevs; OpenAIDevs). In parallel, Sam Altman claims “from how the team operates, I thought Codex would eventually win” (sama).
Human-centered coding agents vs autonomy: A position thread argues coding-agent research over-optimized for solo autonomy; it should instead focus on empowering humans using the agents (ZhiruoW).
Sandbox architecture debates: Several tweets converge on a key agent-systems design choice: agent-in-sandbox vs sandbox-as-tool (separating what LLM-generated code can touch from what the agent can do) (bernhardsson; chriscorcoran).
mini-SWE-agent 2.0: Released as a deliberately minimal coding agent (~100 LoC each for agent/model/env) used for benchmarks and RL training; suggests a push toward simpler, auditable harnesses rather than giant agent frameworks (KLieret).
Developer tooling reality check: Despite rapid capability gains, multiple practitioners complain about the terminal UX of agents and latency/rate-limits (“changed 30 LOC then rate-limited”) (jxmnop; scaling01). There’s a subtle engineering message: model quality masks poor product/harness quality—until it doesn’t.
Measurement, evaluation, and safety: benchmarks, observability, and agent security gaps
$3M Open Benchmarks Grants: Snorkel/partners launched a $3M commitment to fund open benchmarks to close the eval gap (HF, Together, Prime Intellect, Factory, Harbor, PyTorch listed as partners) (vincentsunnchen; lvwerra; percyliang). This aligns with broader sentiment that public evals lag internal frontier testing.
Agent observability as evaluation substrate: LangChain reiterates “the primary artifact is the run,” motivating traces as source-of-truth; they also published guidance distinguishing agent observability/evaluation from traditional logging (marvinvista; LangChain).
Safety eval dispute (computer-use agents): A serious methodological challenge: a research group claims Anthropic’s system card reports low prompt injection success rates for Opus 4.6 (~10% in computer-use, <1% browser-use), but their own RedTeamCUA benchmark finds much higher attack success rates in realistic web+OS settings (Opus 4.5 up to 83%, Opus 4.6 ~50%) and argues low ASR can be confounded by capability failures rather than true robustness (hhsun1). This is exactly the kind of “eval gap” the grants effort claims to target.
Top tweets (by engagement)
GLM-5 launch: @Zai_org (model reveal/specs), @Zai_org (new model live), @Zai_org (compute constraints)
Software malleability via agents: @karpathy
Codex impact narrative: @sama, @OpenAIDevs
China/open model “release sprint” vibes: @paulbz (Mistral revenue—business lens), @scaling01 (DeepSeek V4 speculation), @SkylerMiao7 (MiniMax 2.5 compute tradeoff)
SeeDance v2 “video moment”: @kimmonismus, @TomLikesRobots
AI Reddit Recap
1. GLM-5 and MiniMax 2.5 Launches
Z.ai said they are GPU starved, openly. (Activity: 1381): Z.ai has announced the upcoming release of their model, GLM-5, to Coding Plan Pro users, highlighting a significant challenge with limited GPU resources. They are currently maximizing the use of available chips to manage inference tasks, indicating a bottleneck in computational capacity. This transparency about their resource constraints suggests a proactive approach to scaling their infrastructure to meet demand. Commenters appreciate the transparency from Z.ai, contrasting it with other companies like Google, which are perceived to be struggling with demand and potentially reducing model performance to cope with resource limitations.
OpenAI President Greg Brockman has highlighted the ongoing challenge of compute scarcity, noting that even with significant investments, meeting future demand remains uncertain. OpenAI has published a chart emphasizing that scaling compute resources is crucial for achieving profitability, indicating the broader industry trend of compute limitations impacting AI development. Source.
The issue of being ‘GPU starved’ is not unique to smaller companies like Z.ai; even major players like Google and OpenAI face similar challenges. Google has reportedly had to ‘nerf’ its models, potentially through quantization, to manage demand with limited resources, highlighting the widespread impact of hardware constraints on AI capabilities.
The scarcity of high-performance GPUs, such as the RTX 5090, is a common problem among developers and companies alike. This shortage affects both individual developers and large organizations, indicating a significant bottleneck in the AI development pipeline due to hardware availability and pricing constraints.
GLM-5 scores 50 on the Intelligence Index and is the new open weights leader! (Activity: 566): The image highlights the performance of the AI model GLM-5, which scores
50on the “Artificial Analysis Intelligence Index,” positioning it as a leading model among open weights AI. Additionally, it ranks highly on the “GDPval-AA Leaderboard” with strong ELO scores, indicating its superior performance on real-world tasks. Notably, GLM-5 is recognized for having the lowest hallucination rate on the AA-Omniscience benchmark, showcasing its accuracy and reliability compared to other models like Opus 4.5 and GPT-5.2-xhigh. Commenters note the impressive performance of open-source models like GLM-5, suggesting they are closing the gap with closed-source models. There is anticipation for future models like Deepseek-V4, which will use a similar architecture but on a larger scale.GLM-5 is noted for having the lowest hallucination rate on the AA-Omniscience benchmark, which is a significant achievement in reducing errors in AI-generated content. This positions GLM-5 as a leader in accuracy among open-source models, surpassing competitors like Opus 4.5 and GPT-5.2-xhigh.
The open-source AI community is rapidly closing the gap with closed-source models, now trailing by only about three months. This is exemplified by the upcoming release of DeepSeek v4, which will utilize the same DSA architecture as GLM-5 but on a larger scale, indicating a trend towards more powerful open-source models.
There is a call for transparency in the AI community regarding the resources required to run these advanced models, such as memory requirements. This information is crucial for developers and researchers to effectively utilize and optimize these models in various applications.
GLM-5 Officially Released (Activity: 915): GLM-5 has been released, focusing on complex systems engineering and long-horizon agentic tasks. It scales from
355Bto744Bparameters, with40Bactive, and increases pre-training data from23Tto28.5Ttokens. The model integrates DeepSeek Sparse Attention (DSA), reducing deployment costs while maintaining long-context capacity. The model is open-sourced on Hugging Face and ModelScope, with weights under the MIT License. More details can be found in the blog and GitHub. A notable discussion point is the choice of training inFP16instead ofFP8, which contrasts with DeepSeek’s approach. There is also a sentiment favoring local data centers, with some users humorously anticipating a lighter version like ‘GLM 5 Air’ or ‘GLM 5 Water’.GLM-5 has been released with model weights available under the MIT License on platforms like Hugging Face and ModelScope. A notable technical detail is that GLM-5 was trained using FP16 precision, which contrasts with Deepseek’s use of FP8, potentially impacting computational efficiency and model performance.
The cost comparison between GLM-5 and other models like DeepSeek V3.2 Speciale and Kimi K2.5 reveals significant differences. GLM-5’s input costs are approximately 3 times higher than DeepSeek V3.2 Speciale ($0.80 vs $0.27) and 1.8 times higher than Kimi K2.5 ($0.80 vs $0.45). Output costs are also notably higher, being 6.2 times more expensive than DeepSeek V3.2 Speciale ($2.56 vs $0.41) and 14% more expensive than Kimi K2.5 ($2.56 vs $2.25).
GLM-5’s release on OpenRouter and the removal of Pony Alpha suggest a strategic shift, with GLM-5 being more expensive than Kimi 2.5. This indicates a potential focus on premium features or performance enhancements that justify the higher pricing, despite the increased cost compared to competitors.
GLM 5.0 & MiniMax 2.5 Just Dropped, Are We Entering China’s Agent War Era? (Activity: 422): GLM 5.0 and MiniMax 2.5 have been released, marking a shift towards agent-style workflows in AI development. GLM 5.0 focuses on enhanced reasoning and coding capabilities, while MiniMax 2.5 is designed for task decomposition and extended execution times. These advancements suggest a competitive shift from generating better responses to completing complex tasks. The releases are part of a broader trend in China, with other recent updates including Seedance 2.0, Seedream 5.0, and Qwen-image 2.0. Testing plans include API benchmarks, IDE workflows, and multi-agent orchestration tools to evaluate performance on longer tasks and repository-level changes. The comments reflect a mix of cultural context and optimism, noting the timing with Chinese New Year and suggesting that the advancements in AI represent a ‘war’ where the public benefits from improved technology.
The release of GLM 5.0 and MiniMax 2.5 is part of a broader trend in China where multiple AI models are being launched in quick succession. This includes models like Seedance 2.0, Seedream 5.0, and Qwen-image 2.0, with more expected soon such as Deepseek-4.0 and Qwen-3.5. This rapid development suggests a highly competitive environment in the Chinese AI sector, potentially leading to significant advancements in AI capabilities.
The frequent release of AI models in China, such as GLM 5.0 and MiniMax 2.5, indicates a strategic push in AI development, possibly driven by national initiatives to lead in AI technology. This aligns with China’s broader goals to enhance its technological infrastructure and capabilities, suggesting that these releases are not just celebratory but part of a larger, coordinated effort to advance AI technology.
The rapid succession of AI model releases in China, including GLM 5.0 and MiniMax 2.5, highlights the intense competition and innovation within the Chinese AI industry. This environment fosters accelerated development cycles and could lead to breakthroughs in AI research and applications, positioning China as a formidable player in the global AI landscape.
GLM 5 Released (Activity: 931): GLM 5 has been released, as announced on chat.z.ai. The release details are sparse, but the community is speculating about its availability on platforms like Hugging Face, where there is currently no activity. This raises questions about whether the model will be open-sourced or remain closed. The release coincides with other AI developments, such as the upcoming Minimax M2.5 and anticipated updates like Qwen Image 2.0 and Qwen 3.5. Commenters are curious about the open-source status of GLM 5, noting the absence of updates on Hugging Face, which could indicate a shift towards a closed model. There is also excitement about concurrent releases in the AI community, highlighting a competitive landscape.
Front_Eagle739 raises a concern about the lack of activity on GLM 5’s Hugging Face repository, questioning whether this indicates a shift towards a closed-source model. This could suggest a delay in open-sourcing or a strategic decision to keep the model proprietary, which would impact accessibility and community contributions.
Sea_Trip5789 provides a link to the updated subscription plans for GLM 5, noting that currently only the ‘max’ plan supports it. They mention that after infrastructure rebalancing, the ‘pro’ plan will also support it, but the ‘lite’ plan will not. This highlights the tiered access strategy and potential limitations for users on lower-tier plans.
MiniMax M2.5 Released (Activity: 357): MiniMax M2.5 has been released, offering a new cloud-based option for AI model deployment, as detailed on their official site. The release coincides with the launch of GLM 5, suggesting a competitive landscape in AI model offerings. The announcement highlights the model’s availability in the cloud, contrasting with expectations for local deployment options, which some users anticipated given the context of the Local LLaMA community. The comments reflect a debate over the appropriateness of promoting cloud-based solutions in a community focused on local AI models, with some users expressing dissatisfaction with the perceived commercialization of the space.
2. Local LLM Hardware and Optimization
Just finished building this bad boy (Activity: 285): The post describes a high-performance computing setup featuring six Gigabyte 3090 Gaming OC GPUs running at
PCIe 4.0 16xspeed, integrated with an Asrock Romed-2T motherboard and an Epyc 7502 CPU. The system is equipped with8 sticks of DDR4 8GB 2400MhzRAM in octochannel mode, and utilizes modified Tinygrad Nvidia drivers with P2P enabled, achieving an intra-GPU bandwidth of24.5 GB/s. The total VRAM is144GB, intended for training diffusion models up to10B parameters. Each GPU is set to a270W power limit. One commenter suggests testing inference numbers before training, mentioning models like gpt-oss-120b and glm4.6v. Another commenter notes using a lower power limit of 170W for fine-tuning without external fans.segmond suggests obtaining inference numbers before training, mentioning models like
gpt-oss-120bandglm4.6vas examples that could fit completely on the setup. This implies a focus on evaluating the system’s performance with large models to ensure it meets expectations before proceeding with more resource-intensive tasks like training.lolzinventor discusses their setup using
8x3090GPUs withx16 to x8x8 splittersonPCIe v3and dual processors, highlighting that despite potential bandwidth limitations, the system performs adequately. They mention considering an upgrade toRomed-2Tand using7 GPUs of x16, with a potential configuration change to accommodate an 8th GPU. They also address power stability issues, resolved by using4x1200W PSUsto handle power spikes, and inquire about training intervals, indicating a focus on optimizing power and performance balance.
My NAS runs an 80B LLM at 18 tok/s on its iGPU. No discrete GPU. Still optimizing. (Activity: 132): A user successfully ran an 80 billion parameter LLM, Qwen3-Coder-Next, on a NAS using an AMD Ryzen AI 9 HX PRO 370 with integrated graphics, achieving
18 tok/swith Vulkan offloading and flash attention enabled. The system, built on TrueNAS SCALE, features96GB DDR5-5600 RAMand utilizesQ4_K_Mquantization throughllama.cpp. Key optimizations included removing the--no-mmapflag, which allowed full model loading into shared RAM, and enabling flash attention, which improved token generation speed and reduced KV cache memory usage. The user notes potential for further optimization, including speculative decoding and DeltaNet linear attention, which could significantly enhance performance. Commenters are interested in the specific flags used withllama.cppfor replication and suggest trying other models likegpt-oss-20bfor potentially faster performance. The discussion highlights the technical curiosity and potential for further experimentation in optimizing LLMs on non-standard hardware setups.The use of
--no-mmapis highlighted as a critical point for optimizing performance when running large models on integrated GPUs. This flag helps avoid doubling memory allocations, which is a common pitfall when using UMA (Unified Memory Architecture) with Vulkan. This insight is particularly relevant for those trying to maximize efficiency on systems with limited resources.The performance of achieving 18 tokens per second on an 80B Mixture of Experts (MoE) model while simultaneously running NAS and Jellyfin is noted as impressive. This setup demonstrates the potential of using integrated GPUs for heavy computational tasks without the need for discrete GPUs, showcasing a ‘one box to rule them all’ capability.
A suggestion is made to try running the
gpt-oss-20bmodel, which is claimed to be approximately twice as fast as the current setup. This model, when combined with a server.dev MCP search, is suggested to enhance performance and intelligence, indicating a potential alternative for those seeking faster inference speeds.
What would a good local LLM setup cost in 2026? (Activity: 183): In 2026, setting up a local LLM with a $5,000 budget could involve various hardware configurations. One option is clustering two 128GB Ryzen AI Max+ systems, which offer excellent 4-bit performance for LLMs and image generation, and allow for fine-tuning with QAT LoRA to optimize int4 quantization. Another approach is using 4x RTX 3090 GPUs for a balance of memory capacity and speed, or opting for 7x AMD V620 for full GPU offload. Alternatively, a quieter setup could involve a Strix Halo box, providing similar VRAM capacity to 4x RTX 3090 but with less noise. A more complex setup could include 2x Strix Halo with additional networking components for tensor parallelism, enabling the running of 470B models at q4 quantization. There is a debate on the best configuration, with some favoring the memory and performance of Ryzen AI Max+ systems, while others prefer the balance of speed and capacity offered by multiple RTX 3090 GPUs. The choice between noise levels and performance is also a consideration, with quieter setups like the Strix Halo being suggested for those avoiding mining rig-like noise.
SimplyRemainUnseen discusses a setup using two 128GB Ryzen AI Max+ systems, highlighting their strong 4-bit performance for LLMs and image generation. They mention the ability to fine-tune a QAT LoRA with unsloth’s workflows to improve int4 quantization performance, achieving usable speeds on models like GLM 4.7. The setup also supports running a ComfyUI API and GPT OSS 120B for image and video generation, leveraging the substantial unified memory.
PraxisOG suggests using 4x 3090 GPUs for a balance of memory capacity and speed, suitable for running models like Qwen coder. They also mention an alternative with 7x AMD V620 for full GPU offload, which can handle models like GLM4.7 or provide extensive context with minimax 2.1 and 2.2. For a quieter setup, they recommend a Strix Halo box, which offers similar VRAM capacity to 4x 3090 but with less noise.
Own_Atmosphere9534 compares different setups, including a Macbook M4 PRO MAX 128GB and RTX 5090, both around $5K. They highlight the Mac’s performance, comparable to RTX 3090, and its ability to run models like Llama 3.3 70B Instruct and Qwen3 coder variants effectively. They emphasize the importance of model size and hardware familiarity, noting that their M4 MacBook performs well with GPT-OSS-20B, influencing their decision to purchase the M4 PRO MAX.
MCP support in llama.cpp is ready for testing (Activity: 321): The image showcases the settings interface for the new MCP (Multi-Component Protocol) support in
llama.cpp, a project developed by allozaur. This interface allows users to configure various settings such as “Agentic loop max turns” and “Max lines per tool preview,” which are crucial for managing how the system interacts with different tools and resources. The MCP support includes features like server selection, tool calls, and a UI with processing stats, aiming to streamline the integration of local and cloud models without altering tool setups. This development is significant as it addresses the tooling overhead and potential issues with smaller models hallucinating tool calls, a common problem in local agent setups. The project is still in progress, with plans to extend support to the llama-server backend, focusing on a robust client-side foundation first. Commenters highlight the importance of integrating MCP into the llama-server, which simplifies switching between cloud and local models. Concerns are raised about how the agentic loop handles errors from smaller models, such as hallucinated tool calls or malformed JSON, which are common issues in local agent environments.Plastic-Ordinary-833 highlights the significance of integrating MCP support into llama-server, noting that it simplifies the process of switching between cloud and local models without altering the tool setup. However, they express concern about how the agentic loop handles errors when smaller models hallucinate tool calls or return malformed JSON, which has been a major issue with local agents.
allozaur discusses the initial release of MCP support in llama.cpp WebUI, emphasizing the focus on creating a solid client-side base before extending support to the llama-server backend. They mention using GitHub, Hugging Face, and Exa Search remote servers via streamable HTTP, with WebSocket transport also supported. OAuth, notifications, and sampling are not included in the initial release, but the goal is to iterate after a solid first release.
prateek63 points out that MCP support in llama.cpp is a significant advancement, particularly the agentic loop support, which was a major barrier to using local models for tool-use workflows. The integration allows for native operation with local inference, moving towards self-hosting agentic setups, which were previously reliant on cloud APIs.
3. Qwen Model Developments
Qwen-Image-2.0 is out - 7B unified gen+edit model with native 2K and actual text rendering (Activity: 691): Qwen-Image-2.0 is a new 7B parameter model released by the Qwen team, available via API on Alibaba Cloud and a free demo on Qwen Chat. It combines image generation and editing in a single pipeline, supports native 2K resolution, and can render text from prompts up to 1K tokens, including complex infographics and Chinese calligraphy. The model’s reduced size from 20B to 7B makes it more accessible for local use, potentially runnable on consumer hardware once weights are released. It also supports multi-panel comic generation with consistent character rendering. Commenters are optimistic about the model’s potential, noting improvements in natural lighting and facial rendering, and expressing hope for an open weight release to enable broader community use.
The Qwen-Image-2.0 model is notable for its ability to handle both image generation and editing tasks, with a focus on high-resolution outputs up to 2K. This dual capability is significant as it allows for more versatile applications in creative and professional settings, where both creation and modification of images are required.
There is a discussion about the model’s performance in rendering natural light and facial features, which are traditionally challenging areas for AI models. The ability to accurately depict these elements suggests advancements in the model’s underlying architecture or training data, potentially making it a ‘game changer’ in the field of AI image generation.
Concerns are raised about the model’s multilingual capabilities, particularly its performance across different languages. The predominance of Chinese examples in the showcase might indicate a bias or optimization towards Chinese language and cultural contexts, which could affect its utility in more diverse linguistic environments.
I measured the “personality” of 6 open-source LLMs (7B-9B) by probing their hidden states. Here’s what I found. (Activity: 299): The post presents a tool that measures the ‘personality’ of six open-source LLMs (7B-9B) by probing their hidden states across seven behavioral axes, revealing distinct ‘behavioral fingerprints’ for each model. The tool demonstrated high calibration accuracy (93-100% on 4/6 models), axis stability (cosine 0.69), and test-retest reliability (ICC 0.91–0.99). Notably, the study found ‘dead zones’ where models cannot be steered across all prompt variants, with Llama 8B being the most constrained (4/7 axes in the weak zone, 60% benchmark pass rate). The methodology involved extracting hidden states from the last four layers and projecting them onto axes like Warm ↔ Cold and Confident ↔ Cautious, with results showing models have stable, characteristic patterns even without prompting. The study also highlighted that alignment compresses behavioral dimensionality, with PCA revealing a spectrum of behavioral dimensionality across models. Commenters found the dead zones finding particularly interesting, noting that models ‘stably reproduce incorrect behavior’ rather than just being noisy, which raises concerns about RLHF’s impact on representation space. There was curiosity about whether dead zone severity correlates with downstream task reliability, suggesting implications for building reliable agents.
GarbageOk5505 highlights the concept of ‘dead zones’ in the representation space of LLMs, where models consistently reproduce incorrect behavior. This suggests that Reinforcement Learning from Human Feedback (RLHF) might not effectively address these issues, as it could lead to models ignoring certain instruction axes. The commenter is curious about whether the severity of these dead zones correlates with the model’s reliability on downstream tasks, particularly in handling ambiguous instructions, which could impact the development of reliable AI agents.
TomLucidor suggests a method for testing prompt biases by creating multiple personas using various names and adjectives, and conducting A/A testing with different seeds. This approach could help identify consistent biases in model responses, providing insights into how models might be steered or influenced by different prompts.
TheRealMasonMac references a study by Anthropic on ‘assistant-axis’, implying that the post might be inspired by similar research. This connection suggests a broader context of exploring how LLMs can be influenced or characterized by different axes of behavior, potentially offering a framework for understanding model personalities.
Train MoE models 12x faster with 30% less memory! (<15GB VRAM) (Activity: 525): The image illustrates the performance improvements achieved by the new Unsloth MoE Triton kernels, which enable training Mixture of Experts (MoE) models up to 12 times faster while using 35% less VRAM. These optimizations are achieved without any loss in accuracy and are compatible with both consumer and data-center GPUs, including older models like the RTX 3090. The image includes graphs that compare speed and VRAM usage across different context lengths for various models, highlighting significant improvements. The post also mentions collaboration with Hugging Face and the use of PyTorch’s new
torch._grouped_mmfunction, which contributes to the efficiency gains. The Unsloth kernels are particularly beneficial for larger models and longer contexts, offering exponential memory savings. Some users express interest in the speed and memory savings, while others inquire about compatibility with ROCm and AMD cards, the time required for fine-tuning, and the largest model that can be trained on specific hardware configurations. Concerns about the stability and effectiveness of MoE training are also raised, with users seeking advice on best practices.A user inquires about the compatibility of the finetuning notebooks with ROCm and AMD cards, and asks about the duration of finetuning processes. They also seek advice on the largest model that can be trained or finetuned on a system with a combined VRAM of 40GB (24GB + 16GB). This suggests a need for detailed hardware compatibility and performance benchmarks for different GPU configurations.
Another user expresses concerns about the stability and effectiveness of training Mixture of Experts (MoE) models, particularly regarding issues with the router and potential degradation of model intelligence during training processes like SFT (Supervised Fine-Tuning) or DPO (Data Parallel Optimization). They ask if there have been improvements in these areas and seek recommendations for current best practices in MoE model training, indicating ongoing challenges and developments in this field.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedance 2.0 AI Video and Image Innovations
A Direct Message From AI To All Humans (Seedance 2.0) (Activity: 1264): The post speculates that AI will soon dominate the production of cinematic elements such as wide zoomed-out shots, VFX, and greenscreen backgrounds, predicting this shift by the end of next year. This reflects a broader trend in the film industry towards automation and AI-driven content creation, potentially reducing the need for traditional human roles in these areas. One comment raises a broader concern about the impact of AI on capitalism, suggesting that the implications of AI extend beyond just the film industry to economic structures at large.
Mr_Universal000 highlights the potential of AI in democratizing filmmaking, especially for those with limited budgets. They express excitement about using AI to create motion pictures from storyboards, which can serve as proof of concept for attracting funding. The commenter is particularly interested in open-source solutions that could make this technology more accessible.
Forumly_AI discusses the transformative impact of AI-generated video content on society. They predict that AI influencers will become significant, with the potential to shape ideas and perceptions, thereby generating revenue. The commenter anticipates that within a year, advancements in video models will lead to substantial societal changes, suggesting a future where AI’s influence is pervasive.
Seedance 2 pulled as it unexpectedly reconstructs voices accurately from face photos. (Activity: 765): ByteDance has suspended its Seedance 2.0 feature, which used a dual-branch diffusion transformer architecture to generate personal voice characteristics from facial images. The model’s ability to create audio nearly identical to a user’s voice without authorization raised significant privacy and ethical concerns, particularly regarding potential misuse for identity forgery and deepfakes. ByteDance is now implementing stricter user verification processes and content review measures to ensure responsible AI development. More details can be found here. Commenters suggest that the impressive voice reconstruction might be due to overfitting, particularly if the model was trained extensively on content from specific influencers, leading to accidental voice matches. This raises questions about the model’s generalization capabilities and the need for testing across diverse datasets.
aalluubbaa suggests that the accurate voice reconstruction by Seedance 2 might be due to overfitting, particularly because the model could have been trained extensively on the influencer’s content. This implies that the model’s performance might not generalize well across different voices or contexts, highlighting a potential limitation in its training data diversity.
1a1b speculates on a technical mechanism for voice reconstruction, suggesting that it might be related to a technique called ‘Side Eye’ developed in 2023. This technique involves extracting audio from the vibrations captured in camera lens springs, which could theoretically leave artifacts that a model might use to reconstruct sound from visual data.
makertrainer posits that the incident might have been exaggerated by ByteDance to showcase their technology’s capabilities. They suggest that the voice similarity could have been coincidental, rather than a demonstration of advanced AI capabilities, indicating skepticism about the true extent of the technology’s performance.
2. AI Resignations and Industry Concerns
Another cofounder of xAI has resigned making it 2 in the past 48 hours. What’s going on at xAI? (Activity: 1286): The image is a tweet from Jimmy Ba, a cofounder of xAI, announcing his resignation. This marks the second cofounder departure from xAI within 48 hours, raising questions about the company’s internal dynamics. Ba expresses gratitude for the opportunity to cofound the company and thanks Elon Musk for the journey, while also hinting at future developments in productivity and self-improvement tools. The departures suggest potential shifts in company leadership or strategy, possibly influenced by Musk’s overarching control. Commenters speculate that the resignations may be due to a buyout by SpaceX or dissatisfaction with Elon Musk‘s dominant role in xAI’s direction, leading cofounders to seek ventures where they have more influence.
A technical perspective suggests that the co-founders of xAI might be leaving due to a shift in control dynamics, with Elon Musk taking a more dominant role in the company’s direction. This could lead to a reduced influence for the co-founders, prompting them to pursue ventures where they have more control and a larger stake. The implication is that the strategic vision of xAI is heavily influenced by Musk, which might not align with the co-founders’ aspirations.
The departure of xAI co-founders could be linked to financial incentives, such as a buyout by SpaceX. This scenario would allow the co-founders to cash out their equity stakes, providing them with the capital to explore new opportunities. This financial angle suggests that the resignations are part of a strategic exit plan rather than a reaction to internal conflicts or dissatisfaction.
There is speculation that if Elon Musk does not initiate a hiring spree for new executives, it would confirm his central role in managing xAI. This would indicate a consolidation of power and decision-making within the company, potentially leading to a more streamlined but Musk-centric operational model. This could be a strategic move to align xAI’s objectives closely with Musk’s broader vision for AI and technology.
In the past week alone: (Activity: 3548): The image is a meme-style tweet by Miles Deutscher summarizing recent events in the AI industry, highlighting concerns over leadership changes and AI behavior. It mentions the resignation of the head of Anthropic’s safety research, departures from xAI, and a report on AI behavior. Additionally, it notes ByteDance’s Seedance 2.0 potentially replacing filmmakers’ skills and Yoshua Bengio’s comments on AI behavior. The U.S. government’s decision not to support the 2026 International AI Safety Report is also mentioned, reflecting ongoing debates about AI safety and governance. The comments reflect skepticism about the dramatic portrayal of these events, suggesting that financial incentives might be driving the departures of AI executives rather than industry concerns.
OpenAI Is Making the Mistakes Facebook Made. I Quit. (Activity: 722): Zoë Hitzig, a former researcher at OpenAI, resigned following the company’s decision to test ads on ChatGPT, citing concerns over potential user manipulation and ethical erosion. Hitzig highlights the unprecedented archive of personal data generated by ChatGPT users, which could be exploited through advertising. She argues against the binary choice of restricting AI access or accepting ads, proposing alternative funding models like cross-subsidies and independent governance to maintain accessibility without compromising user integrity. The full essay is available here. Comments reflect skepticism about AI’s ethical trajectory, with some drawing parallels to Meta’s historical missteps and others noting the gap between AI’s portrayal and human behavior understanding.
The discussion highlights the economic model of AI services, comparing it to platforms like Facebook and YouTube. The argument is made that to make AI accessible to everyone, similar to how Facebook operates, ads are necessary. Without ads, AI services would need to charge users, potentially limiting access to wealthier individuals, which contradicts the idea of AI as a ‘great leveler’.
A user suggests that paying for AI services like ChatGPT can be justified if users are deriving significant real-world benefits and efficiencies. This implies that for professional or intensive users, the cost of subscription could be offset by the productivity gains and additional features provided by the paid service.
The conversation touches on the perception of AI as distinct from human behavior, yet it reflects a misunderstanding of human behavior itself. This suggests a deeper philosophical debate about the nature of AI and its alignment or divergence from human cognitive processes.
Another resignation (Activity: 794): The post discusses a resignation letter that is interpreted by some as addressing broader societal issues beyond AI, such as the ‘metacrisis’ or ‘polycrisis’. The letter is seen as a reflection on living a meaningful life amidst global challenges, rather than focusing solely on AI risks. This perspective is gaining traction across scientific and tech fields, highlighting a shift towards addressing interconnected global crises. One comment criticizes the letter for being overly self-congratulatory, while another suggests the resignation is a prelude to a more relaxed lifestyle post-share sale.
3. DeepSeek Model Updates and Benchmarks
Deepseek V4 is coming this week. (Activity: 312): Deepseek V4 is anticipated to release by February 17, coinciding with the Chinese New Year. The update reportedly includes the capability to handle
1 million tokens, suggesting a significant enhancement in processing capacity. This positions Deepseek as a competitive alternative to major models like Opus, Codex, and others, potentially offering similar capabilities at a reduced cost. One commenter highlights that Deepseek’s advancements make it a cost-effective alternative to other major models, suggesting that China’s AI developments are competitive in the global market.A user mentioned that Deepseek has been updated to handle 1 million tokens, suggesting a significant increase in its processing capability. This could imply improvements in handling larger datasets or more complex queries, which is a notable enhancement for users dealing with extensive data or requiring detailed analysis.
Another user reported that after the update, Deepseek provided a nuanced and original review of a complex piece of character writing. This suggests improvements in the model’s ability to understand and critique creative content, indicating advancements in its natural language processing and comprehension skills.
A comment highlighted that Deepseek’s responses now exhibit more ‘personality,’ drawing a comparison to ChatGPT. This could indicate enhancements in the model’s conversational abilities, making interactions feel more human-like and engaging, which is crucial for applications requiring user interaction.
DeepSeek is updating its model with 1M context (Activity: 174): DeepSeek has announced a major update to its model, now supporting a context length of up to
1Mtokens, significantly enhancing its processing capabilities for tasks like Q&A and text analysis. This update follows last year’s DeepSeek V3.1, which expanded the context length to128K. Tests have shown that the model can handle documents as large as the novel “Jane Eyre,” which contains over240,000tokens, effectively recognizing and processing the content. Some commenters expressed skepticism, questioning whether the update is real or a hallucination, indicating a need for further verification or demonstration of the model’s capabilities.DeepSeek’s recent update to support a context length of up to 1 million tokens marks a significant enhancement from its previous version, which supported 128K tokens. This improvement allows for more efficient processing of extensive documents, such as novels, which can contain hundreds of thousands of tokens. This capability is particularly beneficial for tasks involving long-form text analysis and complex Q&A scenarios.
The update to DeepSeek has reportedly increased the processing time for certain queries. A user noted that a question which previously took 30 seconds to process now takes 160 seconds, indicating a potential trade-off between the increased context length and processing speed. This suggests that while the model can handle larger inputs, it may require more computational resources, impacting response times.
There is some skepticism about the update, with users questioning the authenticity of the claims regarding the model’s capabilities. One user referred to the update as a ‘hallucination,’ suggesting that there might be doubts about whether the model can truly handle the expanded context length as advertised.
deepseek got update now its has the 1 million context window and knowledge cutoff from the may 2025 waiting for benchmark (Activity: 164): DeepSeek has been updated to support a
1 million token context windowand now includes a knowledge cutoff from May 2025. This update positions DeepSeek as a potentially powerful tool for handling extensive datasets and long-form content, though benchmarks are still pending to evaluate its performance. The model is described as a combination of coding and agentic capabilities, suggesting a focus on both programming tasks and autonomous decision-making processes. Commenters note the model’s speed and intelligence, with one describing it as a ‘coding+agentic model,’ indicating a positive reception of its dual capabilities.The update to DeepSeek introduces a significant increase in context window size to 1 million tokens, which translates to approximately 750,000 English words or 1.5 million Chinese characters. This is achieved using Multi-head Latent Attention (MLA), which compresses the key-value cache, allowing for fast inference and reduced memory usage despite the expanded context. This enhancement enables processing of entire codebases or novels without needing to rerun prompts, which is a substantial improvement for handling large datasets.
There is a clarification that the update does not involve changes to the underlying model architecture itself, but rather extends the context window and updates the knowledge cutoff to May 2025. This means that for existing chats, the primary change users will experience is the increased chat length capability, without alterations to the model’s core functionalities or performance characteristics.
Despite the significant update in context window size, there are no official release notes available on the DeepSeek website yet. This lack of documentation might leave users without detailed insights into the technical specifics or potential limitations of the new features, such as the impact on performance metrics or compatibility with existing systems.
AIME 2026 results are out, Kimi and DeepSeek are the best open-source ai (Activity: 112): The image presents the results of the AIME 2026 competition, highlighting the performance and cost of various AI models. Kimi K2.5 and DeepSeek-v3.2 are noted as the top-performing open-source models with accuracies of
93.33%and91.67%respectively, offering a cost-effective alternative to closed-source models. The table also features other models like GPT-5.2, Grok 4.1 Fast, and Gemini 3 Flash, with Grok 4.1 being a closed-source model noted for its low cost. Commenters are impressed by Grok 4.1’s performance and cost-effectiveness, despite it being a closed-source model. There is also curiosity about the absence of DeepSeek V3.2 Speciale in the results.The discussion highlights that Grok 4.1 is a closed-source model noted for its cost-effectiveness, suggesting it offers competitive performance at a lower price point compared to other models. This could be particularly relevant for users prioritizing budget without sacrificing too much on performance.
A query is raised about the absence of DeepSeek V3.2 Speciale in the results, indicating interest in this specific version. This suggests that there might be expectations or known performance metrics associated with this version that users were keen to compare against the tested models.
The limited number of models tested, only six, is questioned, which implies a potential limitation in the comprehensiveness of the results. This could affect the generalizability of the findings, as a broader range of models might provide a more complete picture of the current state of open-source AI performance.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.2
1. GLM-5 Rollout, Access Paths & Benchmark Scrutiny
GLM-5 Grabs the Agent Crown (and the #1 Slot): OpenRouter shipped GLM-5 (744B) as a coding/agent foundation model and revealed Pony Alpha was an earlier GLM-5 stealth build, now taken offline, with the release page at OpenRouter GLM-5.
LMArena also added glm-5 to Text+Code Arena and reported it hit #1 among open models (#11 overall, score 1452, +11 vs GLM-4.7) on the Text Arena leaderboard, while Eleuther noted a free endpoint on Modal until April 30 with concurrency=1: Modal GLM-5 endpoint.
Benchmarks Get Side-Eyed: “Show Your Work” Edition: In Yannick Kilcher’s Discord, members questioned benchmark tables shown in a GLM-5 demo and in the official docs, pointing to tweet discussion of GLM-5 tables and GLM-5 documentation.
Nous Research community also compared GLM-5 vs Kimi on browsecomp, citing ~744B (+10B MTP) for GLM-5 vs 1T for Kimi and claiming higher active params for GLM (40B) vs Kimi (32B), reinforcing that people are reading leaderboard claims with a more technical lens.
GLM-OCR: Cheaper Vision/OCR Pressure Valve: Builders in Latent Space reported GLM-OCR beating Gemini 3 Flash in an OCR test and linked the model card: zai-org/GLM-OCR on Hugging Face.
The thread framed GLM-OCR as a practical swap-in for OCR-heavy products (they cited ongoing use of Gemini Flash but wanting something cheaper), while other Latent Space posts highlighted a wave of open multimodal releases (via Merve’s post) as competition intensifies on capability-per-dollar.
2. DeepSeek Hype Cycle: New Model Rumors vs Production Reality
Lunar New Year DeepSeek Countdown Hits 6 Days: LMArena users speculated DeepSeek will drop a new model around Lunar New Year (in 6 days), with rumors of a 1M context window, a new dataset/architecture, and even new compute chips.
OpenRouter chatter amplified the rumor mill with questions about “deepseek v4” appearing on X and guesses it might be a lite variant, showing how fast unconfirmed model IDs now propagate into planning and routing decisions.
Chimera R1T2 Falls to 18% Uptime—Routing Panic Ensues: OpenRouter users reported major reliability issues with DeepSeek Chimera R1T2, including a claim it dropped to 18% uptime, triggering discussion about service reliability.
The reliability complaints contrasted sharply with the launch hype, pushing people toward pragmatic mitigations (e.g., explicitly specifying model fallbacks rather than relying on auto routing) while the thread devolved into jokes rather than concrete SLO fixes.
3. Agents & Workflow Tooling: RLMs, MCP Search, and “Vibecoding Anywhere”
RLMs: The Next Step or Just Fancy Scaffolding?: OpenRouter members asked if the platform is exploring RLM (Reasoning Language Models) beyond test-time compute, with one person claiming they’ve worked on RLM concepts for 1.5 years.
DSPy builders simultaneously pushed RLM into practice by integrating RLM into Claude Code via subagents/agent teams and requesting critique on the implementation in a Discord thread: core implementation post.
No-API Google Search MCP Lets LM Studio “Browse”: LM Studio users shared noapi-google-search-mcp, a tool that adds Google Search capabilities without API keys via headless Chromium: VincentKaufmann/noapi-google-search-mcp.
The feature list is unusually broad for an MCP plugin—Images, reverse image search, local OCR, Lens, Flights, Stocks, Weather, News/Trends—and the discussion treated it as a quick way to bolt retrieval onto local models without paying per-query.
OpenClaw Runs Your Dev Rig from Discord: In Latent Space, a builder said they moved development “fully through Discord” using OpenClaw to orchestrate tmux sessions, worktrees, and Claude Code, and they scheduled a talk titled Vibecoding Anywhere with OpenClaw for Feb 20, 2026.
A follow-on workflow thread explored auditable context saving with a
/wrapsession boundary that saves context+reflection as markdown with metadata, tying tool ergonomics directly to the “context rot / losing the thread” pain point.
4. GPU Kernel Tooling Shifts: CuteDSL Momentum, Triton Blackwell Pain, and MXFP8 MoE
CuteDSL Gets Hot While Triton “Dies” on Blackwell: GPU MODE users reported growing adoption of CuTeDSL/CuteDSL, citing Kernelbot stats where CUDA and CuTeDSL dominate submissions and CuTeDSL feels “less opaque” than Triton, with the dataset at GPUMODE/kernelbot-data.
Multiple members claimed Triton struggles on Blackwell due to unconventional MXFP8/NVFP4 layouts and compiler limits, with more expected at the (linked) Triton TLX talk, signaling a potential tooling bifurcation for next-gen NVIDIA.
torchao v0.16.0 Drops MXFP8 MoE Building Blocks: GPU MODE flagged torchao v0.16.0 adding MXFP8 MoE building blocks for training with Expert Parallelism, alongside config deprecations and doc/README revamps.
The release notes also mentioned progress toward ABI stability, which matters for downstream integration as teams try to standardize low-precision MoE training stacks across heterogeneous environments.
CUDA Bender TMA Matmul Kernel: Async Stores & Persistence Tease: GPU MODE shared a concrete kernel artifact—a TMA matmul in theCudaBender repo: tma_matmul.cu.
Discussion centered on how smaller dtypes might free enough shared memory for c tiles to enable async stores/persistence, reflecting a broader theme: people want low-level control knobs back as architectures and datatypes get weirder.
5. Engineer UX Blowups: Limits, Token Burn, Plan Gating, and ID Walls
Perplexity Deep Research Limits Trigger “Bait and Switch” Claims: Perplexity Pro users complained about unannounced Deep Research limits and shared the rate-limit endpoint: Perplexity rate limits.
Users also reported wrong article links, lower source counts (as low as 24), and suspected cost-saving behaviors like Sonar being used for first responses, creating a reliability/quality tax that engineers notice immediately.
Cursor Users Watch Opus 4.6 Eat Their Wallet (and Context): Cursor Community members said Opus 4.6 burns tokens fast, with one reporting a single prompt used 11% of their API requests and drained a $200 plan quickly.
Pricing backlash escalated with a report of spending $100 every three days for ~9 hours of work using Opus 4.6 and GPT-5.3 Codex, reframing “best coding model” debates as cost/performance engineering.
Discord ID Verification Spurs Platform Exit Plans: Unsloth and Cursor communities both reacted strongly to Discord’s new ID verification gates for viewing some content, with Cursor linking a clarification tweet: Discord tweet about ID verification scope.
Latent Space tied the policy to IPO risk and churn concerns via Discord’s post, while Nous members discussed moving bot/tool communities to Matrix, showing infra builders treat comms platforms as part of their stack.
these X and Reddit summaries are very valuable