




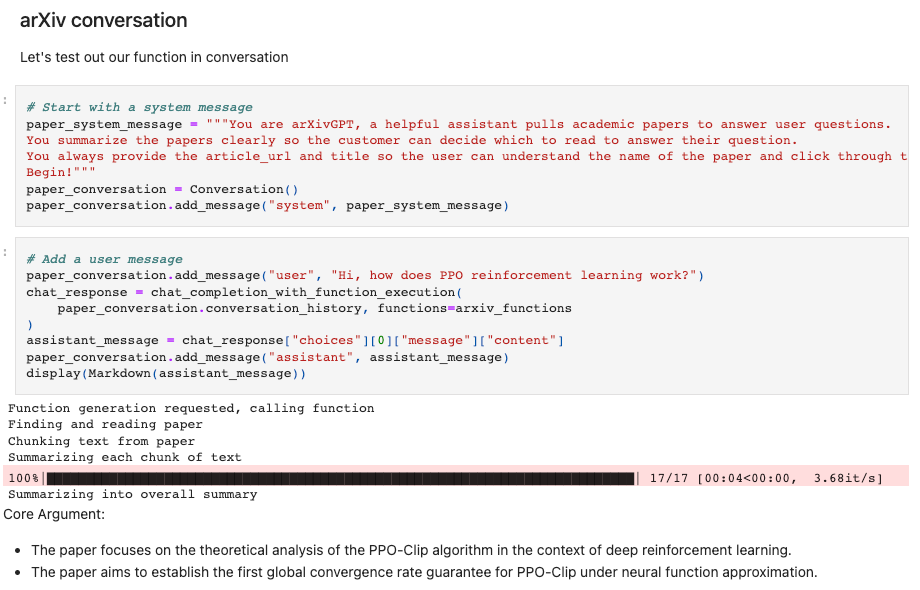
The June 2023 OpenAI Update is here and brings one clear star feature: Functions!

As OpenAI co-founder Greg Brockman noted, this is the mechanism underlying ChatGPT plugins, allowing you to call your own functions to integrate anything with OpenAI.
Where previously ChatGPT Plugins access was behind a $20 paywall and restricted to the 400 approved plugins, with only 3 being enabled at any one time1, now anyone can have GPT3/4 call their functions programmatically!
Getting LLMs to return clean JSON is a known hard problem, and while there have always been prompt engineering tricks to do so, OpenAI making a “finetuning-grade” update and officially supporting it in the API does away with a ton of uncertain, unstable, hacks, and potentially changes the roadmaps of downstream projects like Guardrails, LangChain, and Mayo’s PDF Chatbot.
Advertised use cases:
Create your own ChatGPT Plugins
Convert natural language into API calls and SQL queries

Extract structured data from text



Other updates:
25% price cut on input tokens for GPT3.5 Turbo2
75% price cut of embeddings (
text-embedding-ada-002) to $1 per million tokens. It now takes $12.5m to embed the whole Internet.A new variant of GPT3.5 Turbo with 16k tokens of context (8x longer than the original GPT3, and 4x longer than the previous version of GPT3.5, but half as long as GPT4’s max context). There are some observations that these new versions are noticeably faster3. The tokens-per-minute limits for the 16k variant is also twice that of the previous version. The March variants of GPT3/4 will be deprecated in September.

Smaller notes drawn from the Twittersphere:
Launch driven by Jeff Harris, former PM on Google Glass, Nextdoor, and Pinterest, and now PM of OpenAI’s Developer Platform, Atty Eleti and Sherwin Wu on OpenAI’s Applied AI team, and friend of the pod Logan Kilpatrick on Devrel!
Cookbook documentation created by Colin Jarvis, with Ted Sanders and Joe Palermo (referenced by Logan in our inaugural podcast)
OpenAI CTO Mira Murati calls out increased steerability, aka the system prompt is now stronger than it used to be
Langchain v0.199 released with new Functions API support, and a new
openai-functionsagent
Recursive Function Agents
Just as we did for the March 2023 update, we enlisted the help of prolific AI commentator and Spaces host Alex Volkov of Targum.video to host and reconvene 1400 of our AI Engineer friends for a snap “Latent Twitter Space” discussion on the June update, including:
Simon Willison (of Simon Willison’s Weblog)
Riley Goodside from Scale
Joshua Lochner (Xenova) from Huggingface/Transformers.js
Roie Schwaber-Cohen from Pinecone
Stefania Druga from Microsoft Research
and many more talented AI hackers:

The most interesting open question centered around exactly what functions to supply to GPT now that we have the ability to do so. One might imagine two extremes: “wide” (many functions that each do a little - ChatGPT’s implementation) or “deep” (a few functions, or models, that do a lot - Simon’s view).
With ChatGPT Plugins not yet having Product Market Fit, it is worth exploring the deep side of the function toolkit spectrum. And there is nothing deeper than the products of deep learning - you could easily have GPT as “god model” routing requests to a set of smaller models, just like the Visual ChatGPT project from March:
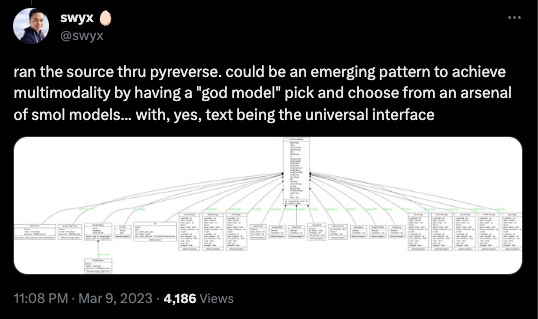
But why stop there? Why not have the model call.. itself?
This is what I have been essentially noodling on for the next version of 🐣 smol-developer:

This design respects 3 facts:
LLMs often generate invalid code
the only way to verify code is to run it in a test environment (something Shreya Rajpal taught us in her pod)
LLMs are very good at fixing code once they see their errors
Allowing LLMs to simply “try again” is the pattern prototyped in smol debugger, and is a poor man’s equivalent of “Chain of Thought” for code generation.
The “rich man’s equivalent” of Chain of Thought involves a model that does not yet exist - the long horizon planning model we identified in The Anatomy of Autonomy. You can brute force it with “Tree of Thought” style graph search, but this is expensive and slow. We will need another breakthough to solve it, but assuming we had one, we already know how to use it:

I won’t lie, it feels like we are in the 1960’s and OpenAI has only just blessed the design pattern for the first transistor. It will take a few iterations until we have fully recreated the LLM-native “CPU”:
 - TAE")
LLM Core, Code Shell
OpenAI’s Functions API is the final stage of what I’ve been calling the “LLM Core, Code Shell” pattern of LLMs interacting with code.

At the end of the day, OpenAI is still responsible for routing requests between functions, filling in parameters, and taking back control once function output has been returned. But there is a ton of developer interest in open source models (we speculated about a ~30B “GPT 2.5”, somewhere between the 1.5B GPT2 and the 175B GPT34 ), and for predictability, reliability, and security. The solution for all these may be to “unbundle the God model” and add intelligence layers to existing software architectures we know and love.
Resources and Show Notes
Google REVEAL Paper - retrieval at training time
Garak - Auto red teaming
Transcript
[00:00:00] Intro
[00:00:00] swyx: Hello, everyone. This is Swyx back again with another emergency pod. The last time we did this was in March when opening I release chat to be the plugins and the new functions API today is effectively. The chat to beauty plugins API now available to all developers and with a whole bunch of other news, 75% price drops on the embeddings. Four times the context length.
[00:00:27] And a lot more other updates. So what we do in these situations when there's a breaking news and it's very developer focused is we convene all the friends of the pod. With Simon Wilson, really good side with people from Xcel research, hugging phase. And pine cone and more that I don't even know where they work at. And I think some of them used to also contribute to Lang chain.
[00:00:50] But anyway, we just had all our developer friends. We had 1400 people tuned in yesterday. Uh, just to talk about what they think and what they want to build with the new functions API. We aim for Latin space, very much targeting for the space to be the first place that people hear about developer relevant news, and to go deep on technical details.
[00:01:10] Uh, to think about what they can build with them and to hear rumors and news about anything and everything that they can build with. So enjoy, unfortunately, Alessio was on vacation, so he couldn't help cohost, but fortunately, friend of the pod. Alex joined in and that's going to be the first voice that you hear alex has been doing a fantastic job running sort of spaces every thursday if you want to talk about just generally i stuff and that as well as just follow him for his recaps of really great news so without any further ado here is our discussion on opening eyes functions api and the rest of the June updates.
[00:01:47] Recapping June 2023 Updates
[00:01:47] Alex Volkov: For those of you who worked with OpenAI 3.5 and for et cetera, feel free to raise your hand and come up, ask questions as we explore this together. And I'll just say thanks to a few folks who join me on stage, Aton and John. And we, we've been doing some of these updates every Thursday but this one is an emergency session, so we'll see.
[00:02:06] Maybe Thursday we'll cover some more. So open the eye today released. An update the June update with a bunch of stuff and we'll start with the, with the simpler ones. But we're here to discuss kind of the, the developer things. We'll start with the pricing updates. So 75% reduction in embedding price.
[00:02:25] This follows a 90% reduction of embedding costs back in, I wanna say November, December. Anybody remember that? Maybe Roy in the audience Roy, feel free to come up as well. And we've seen kind of this reduction in cost on a, on a trajectory to basically, you know, being able to get to embed the whole internet.
[00:02:45] There's actually, I wanna find this. There's actually a tweet by Boris from OpenAI that talks about approximately it gonna cost you 50 million to embed the whole internet, like all of the text on the internet, pretty much. And Logan followed up today and said, you know, after the updates of the pricing today, it's around 12.5 million versus 50 million before.
[00:03:06] Just to give like a huge scope of numbers in terms of like how, how fast this, this type of tech advances. And we have audience and feel free when you finish eating, but basically there's now a debate whether or not embedding on client site is work, given that it's like social so free or almost like very, very heap bad stuff.
[00:03:31] Obviously it's an API and there's a concerns about using private data but embedding 75% cheaper. Imagine that you run embedding of production and John lemme know if you do Houston today if you switch to this api, you basically just received a 75% like price cut for, for the use of a bunch of, of a bunch of stuff.
[00:03:49] And by the Riley from Dxa here. Once he joins, they also, they do a bunch of embeds for pretty much every podcast out there. So, you know, just in one day, you, you can receive like a significant, significant decrease in costs.
[00:04:03] So, embedding price goes down significantly. Very exciting. In addition to this. Another price cut is the 25% for GT 3.5,
[00:04:11] Unknown 1: yeah, I just wanna say, so we use we use a lot of embedding, so we're really happy to see that.
[00:04:15] But the thing I'm most excited about pricing wise today is the new 16 K GPT 3.5 model because I, I believe it's about 150% the price of GPT 3.5 turbo previous API pricing or what, what it is now, rather, and this is really significant for us because TPT 3.5 has never had that many tokens that you can Maxim on in your contacts window for.
[00:04:38] So when we build our input prompts for our co-pilots, it's usually using most of the 4K window just for the input. And so this is a massive, massive increase for us in terms of the economics of getting a big output compared to like GPT 4 32 K or GP PT four ak. Right. It's a really, really big bonus for us and it's barely more expensive than 3.5 regular.
[00:05:02] So I think that's gonna be really massive. Super excited to see what people build with the 3 5 16 K model, because honestly, like we think GP PT four is just quite expensive at this point. Like we don't
[00:05:12] Alex Volkov: use it very much in production, which we, we, we talked last week in our spaces the roadmap for OpenAI, Sam Sam talk about this publicly, is to decrease the price and also increase the speed.
[00:05:22] But yeah. Lemme welcome a few more folks here. Welcome Sean who prompted this Emergency Emergency Spaces. How are you doing?
[00:05:30] swyx: How are you doing? I'm doing okay. I'm moderately excited about it. You know I think you and I had this chat.
[00:05:36] Where we were trying to scope out what the impact is. And I, I think this is an incremental update. So good news on, on many, many fronts. They're, they're shipping with really good pace, but not a game changer in my mind. Just incremental updates.
[00:05:52] Alex Volkov: So we'll definitely get into the function thing, cuz I wanna, I wanna take a big bite to understand like what this means. But I think we covered pretty much all the other updates by now, right? So we have a decrease, significant decrease in embedding costs. We have a significant decrease in GT 3.5, just inference cost.
[00:06:08] And we have a. Four x larger contact window for GT three five, right? It used to be 4,000. Token
[00:06:15] swyx: is now 16. Yeah. And keep, keep in mind that people also have access to 32 k GT four,
[00:06:20] Alex Volkov: For, for four, but not for 3.5,
[00:06:22] swyx: not for the fast one. Yes.
[00:06:24] Known Issues with Long Context
[00:06:24] swyx: So, so something to call out for those people who are kind of new to long context.
[00:06:27] There's a little, it's a little bit uncertain how well the context holds throughout that whole, that new 16,000 token window that you're now being given there's some evidence to state that it doesn't actually pay pay enough attention to that. So a very simple way to do this is to ask it to add two numbers that would be, let's say a hundred million digits long, right?
[00:06:53] So you add two numbers. If you do that in calculator, it would do it fine in TPC three or four. Even with however many context windows it would take to, to embed that it would probably not do well because it only has so many attention heads to add numbers with. So it's just kind of an open question.
[00:07:12] We're not being told any details about, you know, any architectural changes, but, mm-hmm. Can you just scale up GPT3 to 16,000 context and have that context work the same, exact same way as 4,000 token context? It's actually unclear. So I just, I just pointed out.
[00:07:28] Alex Volkov: Yeah, no, that's a good point. And we, within this or at least I've seen this with, with Claude, when they released the hundred K token, and I actually had like significant, like probably attention decrease language, but significant like performance decrease in the a hundred K token for the exact same kind of type of data.
[00:07:45] Yeah. So the, the, we'll see, like they just used it today. John will use this in production and tell us but I think, and here's Sean, that that's what we discussed in dm. So this is the reason for the space is that the functions release is the most exciting to me. And I think it's a, it's a big change.
[00:08:00] New Functions API
[00:08:00] Alex Volkov: So So let's talk about this for our audience. We, we have some folks in the audience and Riley, if you'd like. I wanted to, to, to get you also to come up and speak. Totally. Riley said, all of us, all of us have tried at some point in our life to, to get GPT to give us back a format of some sort. We've talked about yamo being maybe left tokens count overall over json and we all, we all tried this and I think we've all been begging up to kind of gi give us the stool. And what I see today is that they, they went step forward. So instead of just giving us, Hey, we will do whatever what was that Microsoft Thinging that, that forces prompted to Jsm guidance.
[00:08:41] I forgot. Yeah. Guidance. So instead of just giving you like a guidance thing, they are actually kind of thinking step ahead as, as far as I saw and saying, Hey, why don't you provide us with the whole specification of the functions that you will use, the output to. And not only that, give us the functions themselves.
[00:08:57] We will decide based on the user prompt, which functions to use, which significantly reminds me of the plugin infrastructure. So Sean, I would love to hear from you about the function choosing and the, and the
[00:09:09] swyx: schema. I think you actually did a really good recap of it. The only thing I would add is that in the api there's essentially a new role. So historically in chat, bt there have been three roles.
[00:09:21] There's a system prompt, the, the assistant, and the user. And now we have a fourth role for the function and an extra field in the API for the function response or like the list of functions that are capable available to it. So this is effectively the ChatGPT Plugins api being released to us.
[00:09:40] So previously it was only available if you paid the 20 bucks to get ChatGPT Plus, but now you actually can turn off ChatGPT Plus because you could just access the, these plugins via, via the api. And as far as I can tell, Bing with Bing chat is actually better than ChatGPT with web browsing.
[00:09:59] So like there's, there's basically no reason why you should pay 20 bucks anymore. The reason, I guess I'm a little bit less excited about it is that we've had prompting techniques to shape js o responses and to, to select from list for a long time. And what probably has happened is OpenAI has built that in.
[00:10:19] They've maybe fine tuned a little bit towards choosing that well, but they still caution us that it might hallucinate things that don't exist. So they haven't solved the core problem really. They've just taken an existing user pattern and baked it into the api. It's great. But haven't really solved the core problem that all of us want to use it for reliable code, and it doesn't, it's not reliable
[00:10:39] Alex Volkov: yet.
[00:10:41] Yeah, for sure. And on the topic of, of formatting to JSON Riley
[00:10:45] Riley Goodside
[00:10:45] Alex Volkov: welcome on stage, Riley works at scale and he's notorious for getting Bard to give him JSON back while, while telling it. If he doesn't give JSON back, some, some people will die, or something like that. Right. What, what do you think about today's?
[00:11:00] I,
[00:11:01] Riley Goodside: you know, I think it, I think it's cool. I think like that, you know, that it's good that they're like responding to developers and like, I think that they, they're really like thinking like, what I like about like open AI's products is that they have like a good like hacker ethos and like, they just sort of like think about like, how would you like this to be solved at like an API layer?
[00:11:17] And I think that's sort of like where it comes from is that it's just sort of like, if you had full control over it, like what would you do? You'd tune one that like, does the right thing. But, but I think what's interesting though, to me honestly is that it's not like it, it's not like, like what what, like, I think Grant Sladen was doing with like, you know, like forcing the, the like grammar of llama to be like, You know given like context free grammar, right?
[00:11:37] Like, like there are ways you could make this thing like bulletproof in terms of like syntactical completeness and this isn't that, right? They just tune, they just did this entirely through fine tuning. So they, they just have like a note in the API saying that, like, yeah, sometimes it won't, you know, give you the exact syntax or it might hallucinate something like no guarantees there, like, which is, you know, like fair because like, that's what happens if you do it through fine tuning.
[00:11:58] But I think it's like interesting. That's like a it, it's, I I, I, I'm looking forward to trying it though. Like you know, I have like, I'm really confident that it's gonna be like, It, it just makes it easier, right? Like that's just what people want. This is like how people wanna use those kind of APIs.
[00:12:12] I think it's, I think it's a cool
[00:12:13] Alex Volkov: development for sure. And, and one thing that's worth noting here maybe, and I think we've talked about cdm, is that how different this is now from just prompting just level of API and implementation around this will differ from like, let's say cloud or tropic. And actually, yeah.
[00:12:28] Simon Willison
[00:12:28] Alex Volkov: Simon, I saw you raise your hand. Folks, welcome Simon to the stage. Simon Wilson has an insane blog about AI stuff and is deeply lately into plant injection. And this is potentially very scary as well, right? Because like they're suggesting running outputs and then continuous running them. So I would love to hear a thought
[00:12:45] Simon Willison: about this, Simon.
[00:12:46] So I mean, the first thing, I think this is one of those examples where people ask for something and openly, I said, actually, you want this other thing? Like we've all been bugging about reliable output. Most of the people who want reliable Jap but are trying to implement this pattern, the it tells you I need you to run this function.
[00:13:02] Then you go and run this function so openly. I appear to have said, no, no, you don't really want reliable Jap, but what you want is to be able to build this functions pattern. Well. And so we've done that for you and I'm really excited about that. I feel like, like I've met mucked around with implementing that tools pattern myself, and it's quite di difficult in terms of prompt engineering to convince it, to ask you to run a function the right way at the right time, and so on.
[00:13:25] And if they fine tuned model to solve that problem, that saves me a lot of work and that gives me a much more sort of reliable basis to build on. So I'm really excited about that. I'm not, I feel like the, the think thinking about is in terms of more reliable, JSON isn't really what's so exciting about this.
[00:13:39] It's that higher level pattern of being able to add tools into the llm. And yeah. In terms of prompt injection, I'm excited that this is the first time open. I've actually acknowledged its existence. The documentation for these features do, they don't use the term prompt injection, which is fine. It's a slightly shaky term anyway, but they do talk about the security implications of this.
[00:13:58] And right now their suggestion is anything that might want to modify the world's state in some way, you should have the user approved. Eh, I mean, it's better than not saying that, but I always worry that people are just going learn to click okay to everything, just like cookie banners and so forth.
[00:14:13] But yeah, it's it's, people build as, as always with prompt injection, if you're building with these things, you have to understand that problem. Cause if you don't understand the problem, you're, you're doomed to create software that is vulnerable to it.
[00:14:26] Alex Volkov: Thanks Simon, and I wanna get to Eric, and then I'll talk to Sean about agents.
[00:14:30] Eric Elliott
[00:14:30] Alex Volkov: So folks, welcome Eric Elliot on stage. He's the creator of Sudo Lang, which is partly getting LMS to kind do what you want. And Eric, what do you think about today's,
[00:14:38] Eric Elliott: Louis? I think it's exciting. I haven't had a chance to play with it much yet, but I'm excited to dive into it after my workday and play with it today and tomorrow and figure out what it's capable of.
[00:14:51] But just some general tips. If you guys use you can just define a little interface inside of your prompts and you can have it follow that interface and you could create an interface that's specifically for the the function calls that you wanna make and stuff like that. It, it, it might help it.
[00:15:10] Be a little bit more accurate. I've noticed that when you prompt it with pseudo code, it actually does a better job of obeying your constraints and, and following your instructions and creating the outputs that you want. So give that a try and if you have any trouble with it I would be really interested if you guys post tweets just showing the difference in the accuracy of, or the reliability of the function calls in different ways of prompting.
[00:15:38] That would be a really cool experiment to play with.
[00:15:42] Alex Volkov: Yeah, most definitely. And, and to just give folks in the audience some context around this, you can actually run different models by specifying the, the exact model that you want. Mm-hmm. Either the, the three 14 or the what, six 13
[00:15:54] Unknown 1: that we got. Yeah.
[00:15:54] There's two new models. The just using GPT4 and the model call will tell it, use the latest one. So it'll use the new one if you just do that.
[00:16:05] Functions API and Agents
[00:16:05] Alex Volkov: I wanna move to Sean. Sean as a developer for Small Devrel. They got like a bunch of exciting centers of like running agents, oh, God, and writing code, et cetera.
[00:16:13] The whole point about them five tuning a model that actually understands several of the functions that you send and you can provide types and kind of the, the, the call structure, the arguments with types. How does that affect you know, you and your friends in the agent making space that basically you write tools and then you also use some prompting to, to, to kinda ask the LM to run those tools.
[00:16:34] Now that we've kind of moved this thought process into the lm, you had a great post recently about different types of approaches. How does that play into there? And if you wanna introduce your, your thinking around this
[00:16:44] swyx: would be, first of all Alex, you're getting really freaking good at this. These are amazing questions.
[00:16:49] You're juggling all of us, like really well. Just round of applause, even though we can't applaud. Okay.
[00:16:55] So the functions api, I. Eliminate some work that I needed to do for small developer Anyway I have some literally some open issues that I can just close now. Cuz because I just say like, just use this and stop bothering me with your prompts.
[00:17:08] It still doesn't solve what I was talking about today, which is literally I think three hours ago I posted this so it's kind of fresh. Which is this distinction between l LM Core and Code Shell versus LLM Shell and Code Core. And I think everyone in the agent's world is moving on to that world.
[00:17:25] The LM Shell Code core, I'll, I'll explain this a little bit later, but this Functions API and OpenAI in general is very much in an LLM centric view of the world that the LM calls out two functions, execute stuff, and then it goes back into the function into the LLM again to do everything so.
[00:17:44] You know, I'll characterize, I don't know if open I would agree with this. I wanna characterize open AI is always wanting to build the agi. I always wanting to build the God model, always wanting to, to go back to the God model, to decide all the things. And I think the engineers who, who want more control, want more security, want more privacy, all that, all this stuff want to once it unbundle the lms, put, put make it, make individual components smart.
[00:18:07] But but not to have it in central control. And you, when you see things like Voyager, it, it's basically using LMS as a drafting tool to write code. And once you have code that, you know, works, just use code, it's faster, it's cheaper, it's more secure. And I, I think that's the fundamental attention cuz that's an, that's the feature that doesn't have OpenAI at the center of it.
[00:18:25] Functions API vs Google Vertex JSON
[00:18:25] Alex Volkov: Yeah, that's, that's, that's definitely A shift towards how open the eye wants it versus potentially being able to switch out, open the eye at some point. Right. So, so I guess and maybe Riley you can touch upon this a little bit, how much kind of functionality like this, which is not only prompt and, you know, better logic and, and better understanding and inference, but significant kind of changes to the api, which other folks and players in the space ne don't, don't, don't necessarily have, I think Google really something where like you could, you could provide an example of adjacent output.
[00:18:54] I haven't seen anything from Claude, but Riley, I would love your, your thought here. How does this kind of differentiate open the ai just from a developer perspective of like this is our ecosystem, this is how we do things in our ecosystem. And if you, you know, if you want it easier for the model to select whatever, whatever you want, you should use open AI and it's gonna be harder for you to switch.
[00:19:13] How do you think about that?
[00:19:15] Unknown 1: I mean, I, I think like, you know, I haven't like had a chance to play with it much, but I believe like vertex has something very similar to this that you can like specify JSON schema for it. And
[00:19:25] Alex Volkov: Vertex, just, just for the audience, vertex is the, the Google kinda API ecosystem, correct.
[00:19:30] That that's the one you talk
[00:19:31] Unknown 1: about? Yes. Yeah. Yeah. So Google Vertex which is like, so they're more like developer focused offering, whereas like Bard is sort of like a consumer product. They're, they're doing like a more like, differentiated rollout of it. But, but it's like but yeah, it's, it, it's, I haven't played with it much, but I mean, it's like, it's an idea that was floating out there.
[00:19:51] And I think like I've, I've heard on Twitter at least that they like you know, they, it was like a week ago or something like that. So, you know, it's, it's, but I think it's great that everyone's, you know, responding to like, just, you know, this, this feels like a convention, right? Like, this is like something that, that I've often explained to people many times, like how to get your co your prompt to upload regular json, right?
[00:20:10] And, and I think like and I often like, sort, sort of like, like, I, you know, I think like it is just a good way to think about like, prompts as like, structured, right? Like, like code is very you know, I, I've, I forget who said this, so I saw somebody on Twitter that said that like, you know, it's a mistake to think of these models as being models of natural language.
[00:20:29] They're models of code, which happens to encompass natural language, like comments and, and names of things and so on, right? So it, it's like the, the code part of it is like, is so fundamental to how they think that like, you should just like, speak their language in some sense. And, and like, I, I think that's, like, that's one thing I miss about like code Da Vinci too actually is is that like, you know, it's like more of that raw experience of just like speaking to the thing that thinks in code.
[00:20:54] But I mean, you know, D four is great, but, but like I, I'm looking forward to like playing with this like JSON thing because like, it, it is just a common frustration. It's one of the things that makes like a chat thing, a, a chat application different than an p. Right. Like that you want like certain regularity of behavior.
[00:21:09] And I think that's really good that the, like that lots of players are responding to that. I mean, something that, that we think a lot about you know, at scale for like spell book, right? We, we, we are really interested in like these sort of structured JSON objects and it's like yeah, I think it think it's a, it's just a good move
[00:21:25] Alex Volkov: for everyone.
[00:21:26] Yeah. And Shawn pulled Stephanie up. If you like to introduce or Stephanie, feel free to to chime in here. Yeah.
[00:21:32] From English back to Code
[00:21:32] Stefania Druga: I'll just let Stefani introduce herself. So I'm Steph. I'm currently doing a research internship with Microsoft Research and I work with fixe ai, which is also in the space of agents similar to LangChain.
[00:21:45] I, I had a question. I was curious. You know, I ran a hackathon for Fixie where people are building these agents for the first time, and I could see like people coming to these new applications from two ends of the spectrum. Like on one side you have folks who are like, no code really learning how to prompt they like to use like natural language.
[00:22:04] And at the same time there's like all of these problems of. Hallucination not being able to restrict the outputs or verify them. On the other side, you have developers that are used to like writing code in Python or, and like using APIs and mixing that with natural language and knowing when to do one and or the other is like not necessarily a given where power users here.
[00:22:26] So I'm curious, like with these new pushes where, you know, you write more functions you have to like, in your API calls, like have many more levels of prompting, how do you see this affecting, like, onboarding people? Are we going more towards like, developers having to put English here and there in their code, but spending much more time write writing code or the other way around?
[00:22:50] Right? Like and what does this mean for these APIs and models and who are not power users?
[00:23:02] Alex Volkov: That's a great question. I think. Anybody on stage who wants to take this? Riley, go ahead. And maybe Simon as good.
[00:23:09] Riley Goodside: Yeah, I, I think, I think it's just strips away one layer of like, thing that people have to learn, right? Like, this is just like a common like, exercise of like, how do you get it to do j s o And it's just like one less thing you have to know. Like it's, it makes it just, you can throw it in if you want it.
[00:23:21] If you don't want to like bother with this thing, you don't worry about it, you know, if it's a a chat thing. But I think it mostly just makes, you know, like life simpler to be honest. I mean that's being, you know, I'm saying that without having it. I haven't actually used the product, but it's, but it sounds cool from the docs.
[00:23:36] I find it kinda interesting how, like, with prompting, we're having to program in English and it turns out that programming in English is kind of terrible. Cause you know, with, when you, when you want a computer to do something, you want to be able to specify exactly what it should do and having any ambiguity in it whatsoever.
[00:23:52] Especially ambiguity where 50% of the time it does one thing and 50% of the time it does another, which these models do all of the time because they're not You know, you can't guarantee they'll have the same result, same input. It's actually really frustrating. So I'm kind of fascinated to see if we swing back from English language prompting to more structured prompting as a way of addressing some of these challenges.
[00:24:12] But really, I feel like on the one hand, the thing that most excites me about language models is every human being should be able to automate computers and get them to do tedious things for them. And right now it's a tiny fraction of the population to learn enough programming to be able to do that, which I think is, is deeply frustrating.
[00:24:28] But yeah, on the other hand, as a programmer, I want to be able to sell a computer and have it do it. I don't want to program which, which occasionally just refuses to do something because it decides it was, it's unethical for this particular case or whatever. Yeah, it's a, it's a complicated balance.
[00:24:43] Definitely. You know, it's gonna be really funny. The one common joke about Python is that it is pseudo code that compiles, and it's gonna be really funny if we go from code and then we go to English and then we're like, no, no, no. We need to be able to specify, you know, something in, in a concise manner.
[00:24:57] And then we end up reinventing Python.
[00:24:59] Alex Volkov: The, the thing that I got very excited about is haven't recently and fairly recently, please don't judge a move from JavaScript to TypeScript and fairly recently understanding kind the benefit of types, especially for larger systems, getting this option inside kind of the prompt in this specific area and having potentially the model be fine tuned on understanding what exactly is the, the, you know, the type of argument to, to I want as a response.
[00:25:25] I think that's incredible. For some reason, I, I, I went into the playground and I saw that they're not using the open API spec, they're using kind of their own schema style. However, still, you can still specify, hey, for this function, you know, hey, L Om, hey g t you would need to return here a number here, a text.
[00:25:41] And here is like an object and maybe even specify the type of this object. And Steph kinda circling back to what you said this for engineers like Simon who've been engineering for all, all their life, and suddenly there's like an amorphous. Stock machine that sometimes refuses to do things.
[00:25:57] It's not only this is now, okay, now I can reason about this. Now I can write out my API spec like I would do anyway, and now I can provide this to this model that potentially would adhere to this better because it's more fine tuned. I think I think it's definitely exciting on the, on the engineering part.
[00:26:12] Yeah, it looks like we have a few more folks.
[00:26:14] Embedding Price Drop and Pinecone Perspective
[00:26:14] Alex Volkov: I actually wanted to hear from Roy. Yes. Folks Roy is here on stage and listen, I'll get to you after this. Just real quick, Roy is the Devrel for Pine Kong and the example that we saw I don't know if how many of you folks had the chance to dive into the, to the cookbook, the OpenAI released.
[00:26:29] One of the examples is actually a step by step two functions that the AI calls itself, right? So the user asks about something and then in their example they're doing some embedding for the archive link and then do something else. And Roy as somebody who works in like kinda vector database space and, and we know that most of the agent tools use bank or some example of that.
[00:26:50] What do you think about today's changes? How do they affect kind of vector databases and tooling around them?
[00:26:56] Roie: Yeah, so I mean, I think that like having a reliable way of going back and forth between the model and our code is going to be especially beneficial. What caught my eye, and I know that we've talked about this in the beginning more than the function stuff is like the lowering of the embedding cost, which surprise Oh, that's a big gift for you.
[00:27:16] And I'm actually wondering Yeah, completely. And I was actually kind of, kind of confused by that, cuz like, what I'm trying to understand is like, how, how is this possible? Like, do they suddenly get cheaper GPUs to like, get embeddings from? It's, it's kind of, it's kind of both great news for us, but also you know, it's kind of a mystery as to like, why was it so expensive to begin with and what caused the, the drop all of a sudden.
[00:27:42] Alex Volkov: Yeah. And, and for, for those who recently joined, we've talked about this where the recent drop was around November, December, and they back then dropped the ADA 0 0 2 embedding to like, by like 90%, and now it's another 75% drop. So we're seeing this unprecedented price reductions from an api. I don't remember like another example of this.
[00:28:05] Go ahead,
[00:28:05] Roie: John. Yeah, and, and, and I honestly, like, I, I would love to hear from anyone here who has like better understanding of like the, the internal workings of open AI potentially as to like how they made this possible and should we expect even further reduction in the future and, and spec. And, and also I wanted to ask Zov, and I know he's still maybe like only in listening mode, but how he thinks that impacts you know embedding in the client and you know, like how, how he thinks about these changes as well.
[00:28:34] Alex Volkov: Feel free to raise your hand and come up if you want. Shawn, you, you're muted before if you wanna I think
[00:28:39] swyx: obviously none of us here work at OpenAI. Logan usually joins in some of these spaces, but obviously he might, he might have a meeting right now. So we don't know, right? What, what, what happens internally in, in OpenAI.
[00:28:50] I do think that having had conversations with some OpenAI employees in the past whatever they released in like November was the most unoptimized version of this. You have to believe that there's basically a few orders of magnitude improvements, maybe two or three, not, not, not that many, but orders improvements in infrastructure and cost as they understand your usage patterns and, you know, distribute load, like scale up machines.
[00:29:14] That's that kinda stuff. And then the other thing to watch out for is, and sometimes the models shift and then just call it the same name. So actually they're deprecating the older models and moving to a newer one, right? So they may, they may have found an, a better trade off between inference and training, such that inference is much cheaper.
[00:29:33] And that's definitely been the trends that we've been observing on our podcast about Lama style models quote. So you can see like a general trends toward optimization and inference. So I, I think, I think that's one thing there. And then lastly, I'll just point out that embeddings are a form of lock-in.
[00:29:50] So it's actually very much in a, in OpenAIs incentive to lower the cost of embeddings, because then you embed the whole world in OpenAIs image and you have to speak OpenAIs to, to queries, to retrieve and, and all that stuff. So I, I, I mean, I, I, I can't explain the, the, the degree of, of price reduction, but I can explain the motivations of it.
[00:30:11] Alex Volkov: And I think Zar, we'll get in just a second. Sean, as it relates to what you said they're reiterating multiple times that they're not using any of the data that, that provided via api towards, towards training. And I think it's worth highlighting that, at least that that's what we're trying to do, because we've heard, at least I heard from many peoples like, Hey, Walter, user data for training, et cetera.
[00:30:30] So I think yes, for ChatGPT especially for the free version, but via the api, it looks like the data that we're providing is not Is not getting OpenAIs is not using it to train. Oh.
[00:30:39] Xenova and Huggingface Perspective
[00:30:39] Alex Volkov: So I wanna welcome to the stage Denova. Innova is the of Transformers. Gs recently a hug and face employee.
[00:30:46] And we just recently had, we talked about embeddings on client side, partly because of the same reasons, right? Because you don't wanna provide maybe your production data or maybe you wanna run cheaper and tester embeddings. So, no, definitely feel free to chime in here about the role of cheaper and cheaper embeddings on open AI side as the, and also the lock in into open AI ecosystem versus running them on client side or, or, you know, on models for, for free on local hosts.
[00:31:14] Xenova: Yeah. Thanks. Thanks for, thanks for having me. Yeah, I think there's, there's definitely, I think there's two different use cases for these types of things where the opening, what opening is really providing is like these very large scale. I, I mean, any, any business now that wants to embed all their data or, you know, any project that wants to, as, as you've mentioned like embed a large amount of data, they're gonna benefit so greatly from from these price reductions as, and I mean, as, as we have some people in on the stage here as well with the vector databases.
[00:31:47] I mean, there's, it's, it's only gonna accelerate that part of, of the space right now. And then the other option, which is sort of what I'm, it, it's funny, I I'm not too sure if this is like a battle between these two sides or it's like just two different use cases is. The the client side running of these you know, generating embeddings and at, well, with the project I'm working on now, transformers, JS is basically running these models, client side, running them in the specifically the way I started it was for running in the browser locally, and I think that.
[00:32:21] As we, as I saw from, oh, a demo that was created like a week or two ago, there's, there's quite a bit of interest running these things locally. Obviously you don't want to be sharing some sensitive data or latency perhaps is an issue that you don't want to make, like a bunch of these requests.
[00:32:37] And then anyway, there's, there's a few reasons for, for client site embeddings. And obviously the, the major drawback of this is that you do not have the same like power. I mean, some of the open AI embeddings are what, like 1,536 dimensions, whereas limits I've seen in the browser or locally is around like 7 68.
[00:32:59] So depending on your use case, I think you can do very well with either case for the very, like industry level things. I, I mean, it's quite certain that you'll be looking for like a you know, using OpenAIs API as well as a, a vector database perhaps for those use cases. But for, you know, lesser maybe hacker type of things where you're messing thing, messing around with some things a little project that you've got going on.
[00:33:26] I definitely think like client side generation of embedding still has a place to a, a role to play. But yeah it's, it's very, very cool that this type of stuff is, is happening where, you know, these press reductions and whatnot. So and sorry Alex, yeah, I just wanted to say Z Nova. That, that I'm, I've been actually using Transformers js in node, which works really well.
[00:33:50] And I think that for those kind of use cases, it goes well beyond Hackery. I think that there's a real case to be made for using local and, you know, you know, open source models that don't kind of call out to a third party. And you know, as, as once we can have like better open source models that are compatible with Transformers, js you know, the better what we'll get.
[00:34:13] And in fact all of pine cones, JavaScripts examples are going to be using transformer GS for that matter. So, That's also taken.
[00:34:23] Function Selection
[00:34:23] Alex Volkov: That's great. I wanna, I want the panel to talk about the selection of the functions, right? So one of the things we saw today was that open AI essentially lets us to provide several functions including the function definitions.
[00:34:36] So description of what the function does, and then the parameters, or I guess attributes if we're talking about python and attributes types as well. And then kind of similar to what happens with plugins, if you have used plugins in GPT before and you select several of them, the, the, the model kind of decides which plugin to use based on user input.
[00:34:58] And obviously we've had some of these in agent plan and PT and, and probably small Devrel from, from swyx as well. Some decision of what tool, what tool to use goes to the kind of the, the planning loop or planning agent. And honestly, anybody on stage, feel free to chime in here. How are you feeling about, I know like this is repeating a little bit, but like, how are you feeling about giving BLM that type of decision power based on the description, based on the parameters to answer users kind of request differently?
[00:35:27] Do we need to now provide all of our APIs to this? How
[00:35:30] swyx: are you thinking about this? I think that one piece of thing in the, something in the documentation that I was looking for and didn't see was what's the limit of the amount of functions we can give it? Because ChatGPT plugins if you, if you try it inside of the web ui, you're only allowed to specify three of them.
[00:35:47] There's 400 in the plugin store. Do I, do I just enable all 400? Like, is is that, can I stress test that? Probably not, right? Like, so this, there's just an undocumented limit somewhere. What if they conflicts? What if, are there two, two plug-ins that are very, very similar to each other? What happens there?
[00:36:03] So I feel like this is just like an uncharted territory. Like it's not really clear how to benchmark this stuff. Hopefully they're benchmarking it internally within OpenAI, but the rest of us, we we're just supposed to like, give it functions and hope that it works. Seems, there seems a little bit unscientific, but I don't know how to test it.
[00:36:19] I'm not so worried about this because in this case, we have complete control over which functions are available, so we get to pick the two or functions we are most useful. With plugins, it's much worse because the users picking there and so you are potentially. Your, whatever code you've written is potentially interacting in the same environment as code someone else has written you dunno anything about.
[00:36:39] And that's the point where I worry that weird decisions may be made that, that don't necessarily make sense. But I feel like if you are, if you control the full library of functions that you're exposing, I think you'll probably be okay. The other thing to think about is I think it's probably gonna be better to have a small number of functions where each one can do a lot more stuff.
[00:36:57] Like I've built ChatGPT plugin where my function takes a sequel query and return to response. And actually there's a example in the open AI documentation of, of doing exactly that as well. That works amazingly well because your documentation for the function can literally be, send me a sequel query in SQLite syntax.
[00:37:15] And that's it. The model already knows SQL and knows SQLite syntax. So just like five or six tokens of instructions isn't, isn't, isn't enough for to be able to do incredibly sophisticated things. So, yeah, my, my hunch is that we'll find that we actually want to only give it two or three functions, but have each of them have quite sophisticated abilities, maybe based on domain specific languages like SQL or even JavaScript and Python.
[00:37:37] You know, give it an eval function and let it go wild. See what happens. Yeah.
[00:37:41] Alex Volkov: Well, two, two things. In ter in terms of the the number of functions you can add I think it's unlimited. It's just based on the context length of your of your query and their counter list input tokens. And second thing, another idea would be that you could add a like you can change this within, like
[00:38:00] Simon Willison: you have a call before to determine from the list of functions which function is most appropriate for this use case.
[00:38:09] And then you just pass those limited set of functions. Oh, yes. No, that's a fantastic idea because yeah, you are in full control of each time you loop through it, so you can change the recipe of functions dynamically as your application progresses.
[00:38:22] Alex Volkov: Yeah. Yeah. So, so it looks like a, a few for a few notes here for, for the Pakistan audience, the cookbook, Simon, I think that's what you are referring to.
[00:38:29] The, the cookbook.
[00:38:30] Unknown 1: Yes. Yeah, that's a really great example.
[00:38:33] Alex Volkov: It's a great example, the open air release for us to kind of, to dig through and then see some examples. And so two, two thoughts. Two, two things I noticed then. I think Sean, we talked about this as well. One of them is, is this new role for a function output.
[00:38:47] So when you provide messages back to PT, kinda chat interface, there's the system role, there's the user role, and now we're getting a function role. And back there you can provide. What function actually generated kind of this output. So you can and, and the format that the cookbook shows us is your user does something.
[00:39:05] You provide the, the GPT, kind of the user query and your functions. GPT potentially chooses one, or you can force a specific function output. You can say, Hey, for this thing, I want this function to run and generate a result for this function. So we don't necessarily have to give it the choice, we can just say, Hey, run this function for this user input.
[00:39:24] And then once the, once we get back adjacent output formatted per spec, we then need to provide it back to GPT potentially to summarize or do something with that data, which kind of plugs in also to the vector DB retrieval systems, right? So we can retrieve something and then ask for, for an additional thing.
[00:39:42] And I think that the, the decision of whether or not to run a function directly or to give it a choice is gonna be an interesting one also. Now as I'm talking, I'm thinking about this in Sean. Please chime in here as well. You can technically provide it a function output of a function that the previous prompt didn't run.
[00:39:58] Designing Code Agents with Function API
[00:39:58] Alex Volkov: Like, right? Like, like with the user input and the system input, you could just invent the function output Exactly. In that function role. So I'm really
[00:40:07] swyx: interested to see how you can, so one thing that I've had an issue with this small developer is like, it basically does single shot generation. And sometimes you just need it to give it more inference time, right?
[00:40:18] You need to do the trio thought thing. You need to ask it, like, you know, rerun the code and fix it, whatever. I don't care. Just do it five times and then, and then I'll, I'll take a look after you're done messing around with the errors. And so actually, like the functions can call themselves the functions.
[00:40:32] You can synthesize code to fulfill functions. And so I, I'm, I'm actually very intrigued by what Simon has raised, which is, you know, let's just say for, for the very specific purposes of code generation, I have maybe three paths, right? One is generate code, two is test code, and three is. Like call existing code.
[00:40:53] And if sometimes I call existing code and sometimes I can call myself and, and have a little bit of recursion in there I essentially have the basis of a code agent just with this, those
[00:41:01] Alex Volkov: three functions.
[00:41:02] And so you can, like, basically those are all the things that you're running for a very small subset of, of, of use cases and you could potentially now provide them. Again, we haven't played with all this yet, right? Yeah. It's brand new. We're doing an emergency re recap, but potentially what you're saying is you can just in every prompt now provide all those three capabilities and either have the model chosen for you or force a specific one to, to give you the output that you need.
[00:41:29] With potentially high re reliability. Right? So that's the part that I would love to discuss
[00:41:34] swyx: as well. I'm gonna hand it, attend it to Stephan a bit. But yes so I'm extremely, extremely inspired by Voyager. Different Nvidia, and Jim Fan I think is somewhere on, on Twitter. The core inside of Voyager is that you should use LMS as a drafting tool to write code and then to, and then once you validate it that the code works.
[00:41:52] You never have to write it again. You can just kind of invoke it. And so you ratchet up in capabilities and you, and that's why Voyager was able to achieve the Diamond and Minecraft so much faster than all the other methods. And I think that's exactly the way that we should probably code as well.
[00:42:07] And, and so yeah, you just kind of do a bit of recursion build up a skills library. And I'd probably be thinking that that is gonna be the, the v2, a small developer. .
[00:42:16] Models as Routers
[00:42:16] Stefania Druga: I was just thinking that there's like, at some point, like a blurry line between these functions and the way we conceptualize agents because some of these functions can be seen as agents. And I'm very curious, like to your question earlier, like when the model chooses which function to use, how does it do that?
[00:42:34] And how could we constrain like that mapping, right? Like, do we have some sort of schema based on like the types that functions take and the outputs they have? Or can we actually build the retrieval into the training, right? So there, there's this paper from Google called Reveal that shows like how they could Encode and convert diverse knowledge sources, like it was images and text and all sorts of other, like multimodal embeddings into a memory structure consisting of key value pairs.
[00:43:06] And they did this at training time, so they have like much more robust and fast responses at retrieval. So I'm, I mean, I'm curious, like, I, I think the implications of having functions and having the model do the routing for these functions will also pose questions in terms of schema and retrieval.
[00:43:27] Alex Volkov: I think the, the interesting outcome of this potentially is, Now the descriptions of functions suddenly potentially are as important as the prompting before, right? So now we have to write descriptions that potentially will help e lm to choose the functions. But there's definitely step, there's a way to force like to, to ask for a specific function output, which is, I think what most developers do by default while expecting Jsun, is for this one use case, give me an output that's like JSON formatted for this one use case.
[00:43:53] And that's still possible, but I agree that it's very exciting, like how it chooses. And we're, we're gonna have to build up and actually Riley maybe, maybe as well, we're gonna have to build up kind of like an understanding of how it would choose, right? Like, we're gonna have to start playing again like Riley did for a year.
[00:44:11] Just like playing with us, trying to see like which one of those people will choose and build like an intuition of how to write proper descriptions and potentially when the, when the model chooses a different different function.
[00:44:23] Stefania Druga: Especially if we wanna share our functions and not rewrite functions that other people have written.
[00:44:28] And imagine you have like a much larger search space at that point.
[00:44:34] Riley Goodside: Yeah, it's, it's really nebulous because like, you're sort of like, it gives you the ability to like run software that only exists in your imagination, right? Like, if you can have, just have like some fake description of how something works, like you're, can be like, oh, it's like Twitter, but it has this, you know, or something like that.
[00:44:48] And like, it'll work, right? So it, it, it, it, or at at least it has in the past, like ways that I've done it, of like doing this through prompt engineering. Like, I haven't used like the, the current thing, but I mean, like, that's generally how these go. Is that, that you, it's like, it's it, it's made to work off documentation, right?
[00:45:06] Like that's, you know, I think that that's the key thing is that it's seen a lot of documentation, it has a lot of experience in the training data of like how documentation relates to code because like, it's trained on like code bases. And I think that's like, you know, it's a good kind of expertise to leverage.
[00:45:23] nisten: I would definitely add a functioned summary of what's there at the end of every prompt, just to shim it. I I, I found it a little bit frustrating even just with normal plugins as to know which plugin is, is gonna pick. Right. So there's, there's some prompt engineering to do there. Okay. So some people are suspecting that, again, it's not a real 16 k, it's more like a variable 16 k kind of like 4 32 K, 16 K. I noticed this with 32 k as well.
[00:45:53] The Maxim responses I was getting back was like up to like 7,000 ish tokens and and, and that that was about it. I mean, you can, you could input 30 k of, of stuff. You can input a code base and then maybe get something back, get a summary back. So I think this might be the case here as well. You can't really get back a very long response, but at least now it, it is responding up to 7,000 tokens, whereas before it was pretty hard to make it right, even like responses longer than 2000 tokens out of one single prompt.
[00:46:29] So yeah, any, anyway, it doesn't look like an an eight K in responses. You, you can dump in up to it. So
[00:46:37] Alex Volkov: Niton, we're, we're gonna wait for you to, to test the limits of this and see if you can get 16 K tokens of JSON back. And meanwhile, I wanna welcome mayor on stage. Mayor is the the mayor.
[00:46:48] Prompt Engineering replaced by Finetuning
[00:46:48] Alex Volkov: Introduce yourself if you're still affiliated, and let's talk about LangChain and how already supports this nity that we've released. Yeah.
[00:46:56] Mayo: No, I, I was just gonna, I, I just tweeted probably just an hour ago. I just, I, I just couldn't get the hype behind this because for me personally, I'm, I'm looking at this as they're not saying anything new, right?
[00:47:09] First of all in terms of the context window, you know, when we kind of look at that and I saw fi file you also, you, you made a tweet as well, just saying, Hey, like, guys, what, what, what, what did they say in this new here? So, okay, the, the context window has gone up, but the embeddings are cheaper. So retrieval.
[00:47:29] It's still gonna be a go-to, right? So what's the benefit exactly for this extra context window if we're, if we're still gonna perform retrieval anyway, and now retrievals cheaper, then I don't really see the too much of the bene unless you want to do named entity recognition. But from a QA perspective again, I, I, I, I don't, I didn't really get the, the big deal there.
[00:47:52] The second thing was the in terms of the function calling, which Lang chain had abstractions for that even the, you know, there's, there's been a lot of research papers and, and like LLMs and using tools as well. So we've been aware of that. You know, it's been a case of prompt engineering.
[00:48:11] The only thing I can see here that seems to be the trend is, is some sort of like maybe a replacement of prompt engineering with fine-tuning, where you have this kind of fine tuning of the model. To be able to base your output tools and, and for agency. So, yeah, I, I dunno, maybe I'm missing something here, but I just, I just, the, the, the updates just, it, it,
[00:48:37] Alex Volkov: I can, I can I can address at least the first part of this and then folks on stage feel free to, to address the, the first and second part.
[00:48:43] Thanks Mayo. So, in as, as regards to like larger context window, the thing that excites me the most is that when you have variable input from your users, when like users can do something that you're, you don't necessarily need, know the size of. Larger complex window just makes it easier for you to just provide all of that context into, into an API without thinking about in the head, okay, I need to count tokens, et cetera.
[00:49:07] Now, obviously, pricing aside, you have to like obviously consider that, you know, each token has a price and then users can, can go and rack up your bills. But for, for my examples, and by users I mean the stuff that users provide, right? So I run our boom toum uses whisper to translate, and then I use DT 3.5 and four to actually kind of fine tune the translation.
[00:49:25] I just shove the whole translation transcript into the, the prompt, right? And so what happens often is for longer videos, for example, I have to then stay there and say, Hey for this, you know, for this transcription, I need to count it with TikTok and I need to do some maybe splitting and splitting doesn't really work.
[00:49:41] And so it larger context window definitely unlock. Those type of possibilities with the kind of, you know, the restriction that talk that Sean talks about, whether or not the attention is the same and it's split the same across this whole context window, but just being able to not think about this with four x the size of token now available on GPT 3.5.
[00:50:00] I think that's definitely a huge plus for, for folks who are not, you know, necessarily token price conscious at this point.
[00:50:08] This also works well with kind of how OpenAI, the combination about plugins and building plugins for the ecosystem for PT works, right? They're saying, Hey, don't shove all of your API in there. Select the two or three use cases, is gonna be easier for the model to, to use.
[00:50:22] And Simon speaks to a previous kind of talk about choosing the right functions at every time you run, run the prompt. If you wanna, if you wanna add some thoughts here or not. And if not, we're gonna go to move to far l And you have your hands raised. Go ahead. Yeah, I, I just wanna add
[00:50:38] Roie: that if you, like, you don't want to outsource or abstract the way the thought process for your agent or chain or whatever call to achieve, to, to be able to, to know which action is being called, right?
[00:50:56] And, and it goes. Towards the idea of interpretability, you know, like understanding how you're getting to the actions that you're getting. And it's basically like, like you've got your prompt magic or engineering at play to get to a specific action or specific output that is visible, right? Like we, we don't know what's going on under the hood with, with their API call.
[00:51:27] And I, I don't know if I would trust it in all circumstances
[00:51:31] Alex Volkov: or applications. So just to recap, you saying in terms of observability and, and repeatability of how it chooses, maybe folks don't give out. Give out. Yeah. 100% the decision which, which functions to use. Yeah, that's interesting. But, but I, I can see it from both sides.
[00:51:48] Like I can definitely see where if you wanna build. And I think you're talking exactly. What about the kind of the decision that Sean is it's in one of the pin tweets on the jumbotron that Chan was talking about where there's, there's increasingly split between whether you are using a large language model is also kind of the, the arbiter of, of the stuff, and then some pieces of your code is getting called by it or vice versa when you're using this for like planning and, and some of the decision making.
[00:52:14] Yeah, go ahead. Well, Sean, could you,
[00:52:15] The 2 Code x LLM Paradigms
[00:52:15] Roie: like, I'd love to hear from Sean on his yeah, agreed on his tweet on, on the, the breakdown between the two paradigms because it, it, it does resonate with me as well. It's it's a good way of breaking it down. So would love to hear more about this.
[00:52:29] swyx: Yeah. And for what it's worth, I was actually tweeting it without knowledge that they was gonna drop this thing today.
[00:52:35] So it's not actually related, but it's, it's. In an overall trend, right, which is what I've been calling code is all you need that you can't really use language models effectively unless you have code. That language models are enormously enhanced by training with code and language models are good at writing code and using code.
[00:52:52] And so we just basically just need to, to utilize code really effectively. But I think the, the main tension that I feel, you know, I'm sort of halfway between the retrieval augmented generation world, which is kind of like V1 of whatever people I've been building with lms, and then V2 of it has been the agent world.
[00:53:09] I feel this fundamental tension in terms of whether you put the model at the, at the center of everything and you write code around it. So this is called you know, LLM Core and then code shell. And, but ultimately still the model driving things, the model hallucinating things, the model planning things or do you constrain the model so much that it only does a, a small job?
[00:53:30] Which is something that I originally got from the core design of baby agi, which is you have individual components of a software program that are, that are intelligent, but they, they are only constrained to do small things. And so I think that, that is, that is the alternative, which is LM shell as a outer layer to interpret things for a code core.
[00:53:50] And with this update and I, I recognize Mayo by the way, that yes, these techniques have have existed in land chain. And, and promise engineering has, has existed as, as a thing. But just OpenAI just made it. Official, right? Like we have a fourth role in the ChatGPT roles that is for functions. And now we have enabled language models to call functions pretty easily. It is not perfect yet. It's still hallucinates it's still generates invalid json so we still, you know, there's still a role for, for, for engineers to play here. But we might be moving from a code you know, LM core code shell world into a LM shell code core world, and I feel like that is a very big shift.
[00:54:29] Mayo: I agree with what you're saying. I guess the, what, what it seems to me is that there's a shift here from kind of prompt engineering heavy approaches to fine tuning, right? I mean, that's, that was my key takeaway from looking at the paper.
[00:54:45] swyx: They, they did fine tune on. Yeah. This specific use case. Yeah. That's something that you can't achieve through problem engineering. Yeah.
[00:54:52] Mayo: Yeah. So previously we, we, we would achieve the same thing through prompt engineering, right?
[00:54:59] Alex Volkov: And, and I guess remains to be seen the quality of how much of the stuff that we've previously done with prompt engineering.
[00:55:05] Because really I wanna get you in, in a second specifically around this, right? Around prompt engineering. Even when you ask JSON, even if you threaten sometimes above the, you'll get here some JSON for you, and then you're gonna have to like, deal with the, the, the unnecessary kind of descriptions.
[00:55:20] And now we're getting more of like a direct tooling, I guess.
[00:55:24] Riley Goodside: Go ahead. Yeah, I think it, like, it, it's the, there, you know, the, when we went to this like message-based api, we made conversation and like chat a lot simpler to implement, but like, not everything is conversation. Like the, the sense of that, that like, that you're doing completion, like document completion is, is gone.
[00:55:42] Like there used to be this, like this, like this drama that you sort of had to put on for the model of like, pretending that you are in this kind of document and like using the right kind of language that's appropriate for that document and so on to like, make it believe it and then like, then it would, you know, reliably do the thing.
[00:55:56] And like now it's, it's like, it's all conversation. Like, it might just like decide like, oh, that's rude and like say, I'm sorry, I can't do that. And break character in some sense, right? Like it's, it's very like, heavy on the refusals now. And I think that like, there, there's blowback from that in small ways and I think they're patching that like, like it sort of like makes it like more like it makes the the things that you would otherwise be tedious to do, like, like less tedious.
[00:56:20] Right. You can, you can have something that like is like the proper way to do it. And so I think that's, I think it's a good move overall. But yeah. Sorry. I think Stephanie hear your hand up.
[00:56:30] Smol Models for the future
[00:56:30] Stefania Druga: Oh, I just quickly wanna say that if I was to put my money on, on it, like I would say the small models, long term is the way to go for various reasons.
[00:56:38] I, first of all, like I, I'm imagining a future where these models can run on device and, and they're more secure and more affordable, and the information is more private and. The data and the training is not concentrated in the hands of a handful of organization, but then from a practical and pragmatic point of view, you know, there's like, right now lots of limitations in terms of compute, even in these large organizations like Microsoft and Google.
[00:57:03] Like everyone is like strapped for compute right now. So I, I do think we need to push for smaller models and more efficient models and for interactive applications like latency really needs to be improved. Right now, we're nowhere near where you could actually sustain interactive applications at scale.
[00:57:21] The last thing I was going to say is that I don't wanna chat with everything. I'm imagining like this dystopian future where I need to chat with my calendar and I need to chat with my email. I need to chat with my sir. Like I, I, I think like there's also the aspect of. UI and UX that will need to evolve because having a chat interface for most of these applications is not gonna scale, in my
[00:57:43] swyx: opinion.
[00:57:44] 1000, well, there's so many claps in the one, hundreds in everything that you said, but yeah, we've been try to push forward this field of ai UX on our podcast for a while. We, we had a couple meetups and yeah, I strongly encourage people to explore beyond the text box. I dunno if OpenAI is interested in that, right?
[00:58:00] Because they're soft deprecating the old completion API and now everything's chat and I think Riley feels this pain because now you can't play those, those old tricks anymore.
[00:58:09] Just
[00:58:10] Riley Goodside: because they're doing that doesn't mean, I don't think they have like one opinion or another. I think that like, You know, we could just like think of these models as reasoning a, like engines that we could leverage and then do whatever we want with the output. And especially now with like, you know, the added ability to, to use you know, some, some form of structured output.
[00:58:31] And and I, I do agree with Mayo. I mean, it does, it does seem like they've basically been listening to the community and kind of adding a feature that may have already existed, but they're doing it their way, which is also okay. But like that to me kind of signals that, you know, if anything, they're trying to give us more paths to, you know, create interactions that go outside of just chat
[00:58:54] The Evolution of the GPT API
[00:58:54] Alex Volkov: back and forth.
[00:58:55] That's actually a good a good segue into how. Do you guys think these changes affect kind of what sev just said, that people don't necessarily wanna chat with everything, so even though it's still in this chat format via had api, right? So Riley was talking about the completion endpoint. Previously you, you would send some text and then the expectation from the model, I think it was da Vinci, right?
[00:59:15] There would just autocomplete kind of the rest of it, like by a few segments. Since then, we moved to this chat thing and then we saw some differences between like even 3.5 and, and four where the system message kinda applies differently. So, go ahead. Right?
[00:59:30] Riley Goodside: Yeah. And like, I, I sort of like, I mean just to give like, like sort of like, you know, slight historical tangent.
[00:59:35] Like, like when GPT three was first published, the, when like the paper came out describing it. All they described that it was capable of doing was in context learning. This idea that like if you gave it like a bunch of examples of a task, like translation or just like some, like, you know, in these like classic machine learning problems that you would use neural networks for it could do them.
[00:59:51] Like, which is from like, you know, following a bunch of examples. They called this in context learning and like they didn't really advertise that it was doing much more than that. They kind of like had another section of like, oh look, if you give it a half of, like half of an article, it'll finish the rest of the article.
[01:00:02] And, and like, it's funny and cool and like, you know, but like it gets good at like mimicking style, like is sort of like the substantial thing. And those, like, those were like the, the applications of it and like, it wasn't warranted as something that you can talk to, right? Like, that had to be like slowly and like, you know with like a lot of innovations like engineered into it and you know, like RLHF is, you know, a big part of that and like part of like RLHF is like choosing what you want it to be.
[01:00:24] And like they chose the, something that is like an assistant that they, that there's like a general like purpose like. Something like a person that you can talk to that like will follow commands and like, if you ask it a question, it'll answer it. It won't be sarcastic, it won't be rude. You know, like it should have like certain personality traits that make it usable and like, it, it's, it's a cool idea.
[01:00:44] But like, there's, there's, you know, there's other ways of, of like doing it too. Like, like, you know, like like Reynolds and McDonald like had like a paper that showed that you could beat one of GPT three s 10 shot prompts with a zero shot prompt by like like conjuring up a little fiction for translation.
[01:00:59] So like, just saying like, French colon, you know, French sentence and then English colon like only worked so well. But then they found that it worked better. If you say the an English sentence is given, give the English sentence. The masterful French translator or the Yeah, the masterful French translator flawlessly translated it, translates it into English as colon, and then they, you know, like hit the completion button.
[01:01:21] And that gives you better performance than giving it 10 examples of how to do translation. And like that, like, that's sort of the start of like, this idea of that you have to just like, you know, flatter the model sometimes. Like tell it, it's really good. And like, you know, they do have these like silly tricks to like, you know, constrain it to the right kind of document to make like your thing work.
[01:01:38] And it's like that is going away, right? Like every version that they've like released has made it less about that. Like the, there's like the, the, I, I mean I had like a cheat about this once I said that the, that cheerfully declaring that you're smart before working has been deprecated, right? Like it's every version of the model that they release makes that like less effective of a trick.
[01:02:00] And there's like a plot somewhere that shows this. But let, like, you know, it's that, that like art of it is like going away and now it's like talking to this particular assistant, but they have control over what they want that assistant to be like. They're sort of the storytellers and we're like talking to one particular character in, in their fiction, which is the assistant.
[01:02:18] Sorry, that's my long rant there. No,
[01:02:21] Alex Volkov: it's great. It takes us forward and please write, stay on this. And now it feels like we're getting a semi third option. Right? So still in this UI of like messages or chat, essentially, we're now getting like a new type of, Ability, which is function, which is like you, you pass a function.
[01:02:36] And we still haven't played with this a lot. Like we're still here talking about this instead of running a thing. But now we're kind of getting a more of a more fine tune controlled, do the thing that, that, you know, you need to do in those functions versus, Hey, talk to me about the thing that I need.
[01:02:50] Right. Does it feel like that shift to you as well, or still too early to tell?
[01:02:55] Riley Goodside: I think it's, it's fixing one of the like problems that resolved from it. And it was a big one, right? That, that used to be, that's like that there were ways of like getting it to be regular and good with code and like the structure the right way. And like, they didn't quite fit into this. Like, you are an assistant who answers questions, kind of like role play and like, so it's good that, that they're addressing that need, I think.
[01:03:15] But. Yeah, I, I think like, it, it, it makes it easier to like, you know, do more work in this conversation ui, the like, so it makes you miss like, you know completions a little bit less, I'd say.
[01:03:27] Functions API Security vs Prompt Injection
[01:03:27] Alex Volkov: Yep. And, and so we'll see. Simon I wanna ask you if you're still with us. About you know, your love about, you know, the security of these things and whether you think that the tools that we've just gotten besides being very developer friendly, engineering friendly and, you know tight friendly.
[01:03:42] So we'll be able to actually expect a specific response. Do you think that there's promise here to solve some of the prompt injection things that we've, we've seen and you, that you've talked about?
[01:03:55] Simon Willison: I mean, honestly, I think this is gonna make things worse in that prompt injection is kind of, doesn't matter if you're just playing with a chat bot that can't actually do anything.
[01:04:04] It only becomes dangerous when you hook them up to functions that let them do things in the world. And this new thing makes it much, reduces the barrier to hooking up to function by an enormous amount. So my intuition is that people are going to charge straight ahead, hook it up to all sorts of things they shouldn't have, and, and have all sorts of nasty things happen as a result.
[01:04:25] There are some improvements. So the one of the big features that opener announce is that the system prompts is now respected more, which does tie into prompt injection to a certain extent. But, you know, GP PT four is better at system prompts than 3.5. It just means that prompt injection hacks are a little bit harder to, to pull off.
[01:04:42] You have to be a little bit more devious with them. So I don't think sort of incremental improvements in the system prompt are necessarily gonna have a huge impact on the problem. I mean, it's really, it's really frustrating, right? The all of the things that I want to build with this stuff, kind of, a lot of them don't make sense if we can't make sure that, you know, I don't ask it to summarize an email and that email says delete all of my e other emails, and the model goes ahead and just does it.
[01:05:07] I feel like the thing where you can control which functions are included in each round does help to a certain extent, but I know it's still, it's still really difficult. Right. I think Phil, I think the thing I've decided I've come down on is, Whoever provides the most input as part of your prompt, they have full control over what comes outta the prompt.
[01:05:27] The other end. That's the way you have to think about it. So if you are summarizing a webpage, whoever wrote that webpage essentially gets to take full control over the output of your language model whether you like, whether you want them to or not. And that's really frustrating. It means that there's a lot of things that are very unsafe to build.
[01:05:44] Alex Volkov: One cool thing, Simon, that I noticed recently, just recently is that Bing Chat, that does have a page access, right? So if you use Edge on Devrel version, and this is like you have the sidebar for, for Bing. It has full page access and they started saying that sometimes it doesn't work and they actually have like a classified the first to understand if the page has prompt injection.
[01:06:03] I dunno if you have seen that and if you wanna
[01:06:05] Simon Willison: discuss. Yeah, I, I don't believe in those. The idea that you can detect prompt, inject, prompt injection attacks sure you'll detect some of them. But the problem I have with that is that the whole point of security engineering is that you are up against like adversarial attackers who will try everything under the sun until they find a security hole.
[01:06:25] So if you've got a prompt injection filter that catches 99% of all prompt injection attacks, that's worth nothing because the attackers will find the 1% that gets through and they will, they will, they will take over your system that way. So, yeah, I, I just, I'm, I'm just not a fan of solutions that, that get most of the problem solved because in security, I don't think that that counts for anything at all.
[01:06:46] For sure.
[01:06:47] Alex Volkov: And so with these capabilities that we can technically constrain the response into one function and that function has to have the same kind of schema, et cetera, do you think, do you think it's gonna be a little easier to protect your stuff
[01:06:59] swyx: or no? I
[01:06:59] Simon Willison: don't think so. I feel like that's kind of irrelevant.
[01:07:01] Like cuz the, the problem if, if the function is delete my email, it doesn't matter if you get the schema right or not, it's still, it can cause a harmful action. What you have to do instead is when you're designing the system, you have to say things like, okay, make every action reversible. So at least if the LLM goes rogue and deletes all of my emails, I can under delete my emails again, that kind of thing.
[01:07:21] Or if it's an action that cannot be reverted, like sending an email to your boss, that's the point where you have to have human approval designed in. So when you're designing these, you have to assume that a prompt injection attack could succeed and make sure that the damage caused by that is either reversible damage or at least has some way of the human, of, of, of a human catching what's going on, stopping it.
[01:07:45] swyx: I really love this. I'm gonna try to use that as a template for small developer. This, yeah, there's different modes. You, you market, you market function as reversible or requires human input and you build up a library of them.
[01:08:00] nisten: I think functions are just the complete utter game changer to everything.
[01:08:05] And if you're gonna run any kind of sensitive data through this, I don't think any large company or medical field should let you run it without a function to clean up what you're sending through. So this goes both ways. Yes, it opens up major security holes, but at the same time, it completely changes everything.
[01:08:25] And I mean it because up until now, Yeah, you could do a, a lot of things, but operations were really hard. Scaling was really hard. The thing has a mind of its own. Sometimes it, it, it returns stuff in the right structure. Sometimes it don't. And like, how do you build products around those? Because in computer science and Devrel and stuff, like you expect a response either in error or in a certain format, and it didn't have that.
[01:08:50] Well, now you do, so now you have an interface to the whole world. Now you can do stuff with it. Like this completely changes everything because, so you clear it off, you can clean up your data.
[01:09:07] Simon Willison: You are finally free. I agree with everything you just said. Go ahead. I completely agree, and yet the security implications are still terrifying to me.
[01:09:18] But yeah, no, I'm, I'm super excited. I'm going to, I have things I'm going to build on top of this, but I'm gonna be very careful about the, I think the reversibility. Especially like I want to build things that let people clean up data. Like have a conversation with your data to clean it. Because everyone who works with data says this spend 90% of the time on cleaning.
[01:09:35] They hate it. It's great. I want to solve that problem, but I want there to be an undue function precisely to, to protect against some of the things that could go wrong.
[01:09:45] Riley Goodside: There's a couple of things I wanted to say. Like, one is while I shared like the excitement, I think that we still have to be careful because, you know, these things are still going to hallucinate and there's not going to, there's, there's still not a.
[01:09:58] A clear way to overcome that, even using functions. That's number one. And number two is that I kind of want to echo what may have said before. And while I, I do appreciate that again, this is like a great advancement. It's super cool. I don't know if I would call it a game changer because this has existed, right?
[01:10:15] Like this, this has happened in various, various frameworks, you know, blank chain guidance you know, other, other frameworks have guardrails in place.
[01:10:25] Yes, this, this looks like a very good implementation of this concept of having guardrails and being able to basically force the LLM to do what you want.
[01:10:34] And yes, it's very you know, It's, it's, it's beneficial to all of us that open AI that owns these models, actually put, put like some effort into fine tuning their own model so that this works really well. But I, I just, I just wanna curb the enthusiasm a little bit, right?
[01:10:51] To just say like, this isn't like, you know, earth shattering and like, hasn't, we haven't seen anything
[01:10:55] Alex Volkov: like this before. The same could be said about C Petito, right? When C released folks are like, well this is just prompting and this is just sending the same like back and forth, you know, text. And then Yeti was the first product that, that got to like a hundred million, whatever.
[01:11:14] Sure. Sure. Let, let's
[01:11:15] swyx: see how, how the adoption
[01:11:16] Alex Volkov: goes, right? I mean, the second all was drop from this space and then start actually according to this. And then we'll come back here and then we'll see. Go ahead Simon and hear.
[01:11:26] Simon Willison: I just wanna say for me until today, the functions thing was always a hack, right?
[01:11:30] You could get it working on top of language model, but you had to do some pretty weird prompt engineering and mucking around to, to get that to happen. And now that it's part of the core platform, it feels so much the, the friction involved in getting that working feels so much lower. I'm no longer afraid of it.
[01:11:45] You know, I was kind of cautious of doing this trip in the past cuz I knew there were so many ways that it might break. Now that I know that opening, I fine tuned a model for it. I feel a lot more confident in using it. So I think that makes a big difference.
[01:11:59] Alex Volkov: I won't say thanks for. Everybody here on stage sharing with us, like exploring with us Simon and Sean and Riley and Miston and Zov Farrell and Mayor, and Steph and Roy, and so many great folks here discussing kind of these late exchanges.
[01:12:12] They're definitely exciting, potentially if, if you are siding with miston groundbreaking and earth shattering, which I tend to agree. And this is, this is was the reason for the space with, with Sean. We discussed this in DM and we brought a great panel of friends to discuss how, how big this is. And I think now that we're hitting like an hour and a half, I think we're here.
[01:12:34] Let's do a fairly quick kind discussion about what are we building with this new tool that we have. Yeah. So I'll let Steph go and then let's, let's maybe everybody feel free to turn mute and kind of have an unstructured debate. And then we'll gonna close this out because I'm losing my voice and although this has been fun, it prevents all of us from going, actually playing with this, with these new tools.
[01:12:54] So Steph, go ahead and then feel free folks to chime in and say, what are we building with this?
[01:12:59] Stefania Druga: I just wanted to give a shout out to Leon and his team. They just launched Garak, which is this tool for a security probing for LLMs, and it has a, an auto red teaming function. So that might be interesting to check out.
[01:13:14] But one, one thing that I was thinking about while Simon was talking and I read your blog post on prompt injection, and you know, on one hand we want to have more people exposing these vulnerabilities and maybe sharing their code for red teaming and their examples at the same time, that is helping people who want to abuse like these models and functions.
[01:13:34] So it's, it's, it's a tricky one. I'm curious how, how you're thinking about it. And I had a parting question as well, which is, what are we gonna ask next from OpenAI? What is missing and what would make our use of the technology of the
[01:13:47] Simon Willison: API better?
[01:13:48] So this is a really interesting ethical question. The, it, it's like, All aspects of security service people about responsible disclosure of security vulnerabilities. The frustrating thing with prompt injection, we don't have a fix yet. So, you know, normally if you find a sequel injection hole in someone's website, you quietly tell them about it and they patch it, and then everything's fine with prompt injection.
[01:14:10] Seeing as there is no known way to fix these problems, I kind of feel like it's on us to make sure people understand it before they build systems that are vulnerable to them. So that, that's the approach I've been taking is just, just really trying to shake people and say, no, you can't just say, oh, we'll filter it out, it'll be fine.
[01:14:27] That doesn't work yet. You need to, sometimes you need to say, no, I cannot build the feature you're asking me to build because it can't be built securely. And that's really frustrating. I kind of hate that. Like I, I don't want to be the person who says there's a security hole, you need to stop. I want be the person who says there's security hole.
[01:14:42] Here's the fix for it, and now we can move on with our lives. But sadly we're, we're, we're not at that that point with it yet.
[01:14:48] Riley Goodside: I, I, I like, I 100% agree. Like, I, like it's been frus, it's been weird to me like it's gone from like supe suspicious to like frustrating, to like, just like curious, like, like this seems to be such a hard problem.
[01:14:59] Like it's a, like, there, there, they're like the, like I, I, I think what's going on really is that like, to solve this, you kind of had to re-engineer it to this message-based API because like they have now reserved tokens. They have tokens that only they know exist that they can insert it in as like quote marks.
[01:15:17] And they can have things like a system message. They can tune it in a way that it actually like, you know, like if you could peer into its brain and see like what circuit is it implementing? It's something that pays attention to the system message in the right way. That it like understands the difference between what, like the open AI customer told it our instructions and what the user told it.
[01:15:36] And like, I think that's progress in the right direction of like, that it's like a sensible, like target. Like it makes sense to me, like as an outsider of, of like, that's how you would like go about addressing this. But it just, like, it's a big change. And so like, I, I think they're moving towards it, but it like speaks to just like, what a hard problem this is.
[01:15:51] You know, because like, it, it is since May, I think since like preamble where the original like discoveries of it, you know, in May. And so when, when they put it in, you know, responsible disclosure and so it, it is just, it seems like it's just a deep like issue with how like, you know, the in instruction tuning or attention or something about this works that, that like, it's not trivially fixable and yeah, I think, you know, they, they're, they're making piece, you know, like piece by piece progress towards it.
[01:16:17] I think.
[01:16:18] GPT Model Upgrades
[01:16:18] Alex Volkov: Very interesting to see because we did get an upgrade to 3.5 model. Right. And Simon, you previously mentioned that there's a difference from a system message how much the, you know, the model adheres to it will forward like way better than 3.5. It's interesting to now test again this new model and see whether that listens to the system message better.
[01:16:37] Maybe they implemented some of that in this kind of new update to, to this model.
[01:16:43] Simon Willison: Yeah, they call that stability. They specifically say that the free new the up models are now more steerable than they used to be, and they talk about stability. That basically means how much, how closely base the system.
[01:16:55] I, I'd love to see some examples of that. You know, I, I've not played around with it yet, but I'd love to see a few examples of prompts that were easily prompt, injected with the previous 3.5, which are now protected against. But I did note that they, they have not flat out said, This is a solved problem.
[01:17:11] And until they do, I'm gonna assume it's not a solved problem because you know, it's in their interest to, to solve it and then tell people they've solved it.
[01:17:18] Alex Volkov: So I'm sure that you'll research this. And folks, Simon has a great blog, basically like a pensive from Harry Potter that Simon has since 2013. I looked at it.
[01:17:28] Simon, you're very prolific. So I recommend following Simon and and his login thoughts. Z Nova, go ahead. And I think after that we'll do like a round of, of last parting thoughts.
[01:17:36] JSONformer
[01:17:36] Mayo: Yeah, I just wanted to bring up this because I, I, I'm not hundred percent sure of how they've really implemented it behind the scenes, but has anyone here sort of heard of, like j s o former, the, like, one of these projects that was sort of aimed at these at generating structured
[01:17:54] Simon Willison: data?
[01:17:54] I love that thing. That thing is so clever. Yes. It's wonderful.
[01:17:59] Mayo: Yeah, so I mean, I'm just wondering why or, so I'm, I'm speaking from, cause I, I'm not really sure how they've implemented, implemented it behind the scenes, but assuming they are not doing it this way, is there a reason why OpenAIs chosen not to?
[01:18:16] Because JSON form is like, by definition you cannot, there's no such thing as prompt injection in this case because you only generate a. Tokens
[01:18:24] Simon Willison: that, so you, I disagree on that front. I think JSON form solves the problem if you want it to output JSON in the outputs invalid js o. It does, but prompt injection in this case is much more about when you summarize a webpage, does the text from that trick it into then making a valid call to a function that does something you don't wanna do.
[01:18:44] But yeah, JSON form. So, so my hunch on JSON form, I wonder if they just haven't had time to implement it yet. It's quite a tricky thing for them to, because the way JSON form works, people haven't seen it, is it basically injects extra logic at the next token prediction thing. So it knows that if you are doing, JSON, you've just done the curly bracket, the only token that can come next is a single quote is a double quote.
[01:19:06] And then the only things that come after that are not double quotes until you get to the end and cycle. So you can force your model to output structured text that matches JSON or YAML or whatever. Super clever. Yeah. But yeah, I, I, I, my guess is the OpenAI. I just haven't got round to fully implementing that yet.
[01:19:22] And they'll, they'll get it working at some point.
[01:19:24] Mayo: Right. Yeah. So that's just sort of what I was, what I was getting at with the sort of in the, the bullet. I, I mean, I'm reading there, read me right, right here. It's like the bulletproof way to generate structured data. But so what I, I mean, this does not cover the case where you, the, the, the separation between the user's input and the calling of the function, that is always susceptible to problem injection.
[01:19:46] That, that, that's where the security holes are. But assuming that you are forcing it to generate a structured dot, like json, there are these current approaches where, I mean, it's modifying the loads. I mean, I'm, that's how I assume it's currently working, where it modifies how the next token is predicted.
[01:20:03] But so that, that, that's sort of what I'm getting at is like, so why hasn't OpenAI done that approach or have they, or Yeah. I'm, I'm not hundred percent sure on that.
[01:20:12] Alex Volkov: Yeah. I think the thing about these spaces is we, we don't have Logan here or anybody open, and when we do. They don't necessarily are able to tell us what they're using.
[01:20:21] Go ahead, Riley.
[01:20:23] Riley Goodside: Oh, I was just curious timing if you'd played with I think grant Sladen working on like context free grammar stuff that, like I linked a while back, I didn't know how that compared to JSON former.
[01:20:32] Simon Willison: I think it's the same exact trick, just even more, even cooler because his thing, you can give it any grammar you like, forget about JSON.
[01:20:39] It's anything that can be specified as a grammar. He, I think he posted the idea that he'd like to be able to upload a web assembly program to open AI to, to the open API and say run this to pick the next token, which I think would be freaking incredible. Huh. That's absolutely brilliant idea. Yeah.
[01:20:58] Riley Goodside: That's cool.
[01:20:59] That's really cool.
[01:21:03] Closing Comments - What We Want Next
[01:21:03] swyx: Well maybe just go around and say like, what we think should be built or. Yeah. Page from Steph. What do we want? OpenAI to ship next? Yeah, this is you know, some, some people from over there will definitely be listened to this, so here's your chance to do your your pitch for why, what they should build next. Go ahead Steph.
[01:21:23] Stefania Druga: I was going to say, I, I would like love to have knowledge graphs and be able to have better retrieval. So, you know, this idea of like training with retrieval in mind and yeah, like not necessarily relying on vector databases. Like that's, that's something that I would love to see in the future.
[01:21:44] Simon.
[01:21:46] Simon Willison: I want widgets in chat. GPT I think chats a terrible interface. I would like to be able to build it like a ChatGPT plugin that could say, now show them a map, now ask them to pick something from this list of options. Things like that. Just let us go beyond just having people type text to us.
[01:22:02] swyx: Indeed, indeed. Ov
[01:22:04] nisten: i, I want like a 30 B model that's open source from them. I don't mind if it's like a LAMA license. Oh, open source. Okay. Got it. Yeah, yeah, yeah. Just, just some, some model you can mess around with that. That'd be nice. All the classes guys, adb, if you can do that.
[01:22:22] swyx: So like, what, you know, maybe we should train like GPT 2.5.
[01:22:26] Like just, just double deck a little bit. Yeah. Yeah. Z Nova or Farel. I mean, I'm sort
[01:22:32] Far El: of on the open source coming from having face, so, you know, so but, but I, you know, yeah. GT to win five. Let's go with that.
[01:22:43] Roie: Yeah. Honestly, I'll just I, I just want 32 k GT four with 75% or
[01:22:53] Alex Volkov: 80%
[01:22:54] Riley Goodside: cost reduction.
[01:22:56] swyx: Come on, you'll get that next month. Jim.
[01:22:59] Alex Volkov: Bigger. Jim. Bigger I, I really hope so. I'm good. I'm good. Otherwise,
[01:23:07] Riley Goodside: I'm, I'm very curious to see what we'd be able to build with these new functions. And specifically combining them with agents.
[01:23:15] I think the opportunities there are pretty amazing. It's definitely gonna, gonna make life a lot easier. And yeah, of course. If we could have like some more open source models, that would be awesome.
[01:23:26] Alex Volkov: And Python's gonna have a chance for us to, or at least for folks to, to test this out. Right.
[01:23:31] Ray, you wanna tell us about the hackathon? Oh,
[01:23:33] Riley Goodside: sure. We're holding a, our first virtual hackathon on June 19th to the 26th hundred K in prizes. It's gonna be super fun. It's gonna be held in Kumo space. And we invite you all to attend and show us
[01:23:48] swyx: what you got. A hundred K in prizes. That's, that might be the highest I've, I've yet heard for one of these virtual
[01:23:54] Riley Goodside: hackathons.
[01:23:55] swyx: That's pretty cool. Male. And then Alex, and I'll go and then I'll have Riley give the last word. So male, go ahead.
[01:24:02] Mayo: Yeah. Open source a hundred percent. I mean, we, we, it, it's good what they've done, but then, you know,
[01:24:08] Alex Volkov: my mind just goes to, you know, how can this be applied to open source, right? You know what, they've just pulled out
[01:24:14] Mayo: for the fine tuning, you know, how can
[01:24:16] Alex Volkov: we apply to open
[01:24:17] Mayo: source?
[01:24:17] So, yeah, I'd love for them to, you know, start to, to be open as it says in that name. Right.
[01:24:26] swyx: Yeah. They should just rename at this point.
[01:24:28] Riley Goodside: How about
[01:24:28] swyx: you, Sean? How about you? Oh, well, okay. So yeah, obviously, you know, you want things for free they're not gonna give it to you. End of story. I, I'm, I'm just very interested in Franken models.
[01:24:38] I'm very interested in what Simon has been sketching out this, in this space, which is essentially using them to call still smaller models, but that, that do very specific things, but can do a lot of things. And so I'm interested in essentially just kind of rewriting my developer agent. To do that kind of routing and, and explore the possibility of recursion.
[01:25:01] And when I, when I have more information about that, I'll, I'll report back.
[01:25:07] Alex Volkov: That's great. I wanna just before I, before we go, I wanna call out Sean has a podcast called Latent Space. So definitely check it out.
[01:25:12] swyx: So I'll be posting the recording of this. Yeah. I mean, this is awesome. This is great.
[01:25:16] Everybody chipped in. Yeah. You have the developer perspective. This is what we want. Yeah. Awesome. And we, we also are gonna drop our first, I think the first ever interview with George Hotz on Tiny Corp. And I'm very excited about that one. He so make sure,
[01:25:32] Alex Volkov: yeah, make sure you don't miss that because MD is lagging behind Nvidia and George is working in that space and potentially some exciting things to come.
[01:25:41] swyx: He had this email with Lisa Su went back and forth. It was very dramatic and nothing where George is boring.
[01:25:46] Alex Volkov: Yeah. So, Riley, go ahead. What, what would you want.
[01:25:52] Riley Goodside: I think like the thing that you know about this, this whole release is that like, it it's is coolest functions are like, there, there, I think the real thing that might be more important in the end is, is just this march towards lower prices and bigger context windows.
[01:26:05] I think there's a lot of unexplored stuff to do with big context. And there's a lot of, lot of possibilities that are opened up when things are just cheaper. And you can like, put in redundancy checks. You can have like secondary prompts that like, check the work of the first prompt. You can like, you know, re engineer reliability around the parts that you need.
[01:26:19] So I mean, it's hard to overstate just like how good it is that just the stuff's becoming cheaper.
[01:26:25] Alex Volkov: And Riley, I, I saw that there's a webinar coming up and then you're gonna teach advanced engineer. You talk about this.
[01:26:30] Riley Goodside: Oh yeah, sure. So scale is on July 15th. And I think we've already closed application unfortunately, but oh on, yeah.
[01:26:38] On July 15th we're having a a hackathon and I'll be giving a talk on pro engineering there. And I, last time we did this, I, we did like a repl like like I did the talk again for our webinar. So we'll I expect we'll probably be doing that again.
[01:26:52] Alex Volkov: So I wanna thank everyone here.
[01:26:54] Coming up to the stage. Here's my request to open the eye. I want the vision API as fast as possible. Oh, oh yes. I've been mouthwatering on the Vision API today. Mikhail Parakhin from Bing confirmed that already like 10% of Bing users get access to the GT four Vision api. And I participated in interview with the founder of BeMyEyes, who are currently the only people in the world who has access to Vision api and those great conversation and.
[01:27:23] I, I expect amazing things once that drops for the ability of, you know, a GPT4 to understand the real world. Not to mention how many prompt injections we can do via text. And, but that's a conversation for another, for another time with Simon and Riley. But I definitely wanna thank everyone for coming here.
[01:27:39] This has probably been the biggest space that I've ran, so thank you, Sean, for, for prompting this and everybody who joined. Hey, yeah. And, and now we're gonna have some time to go and, and play with these models and new techniques, and hopefully we'll see you guys again. The, the last slide I'll say is that I'll do, I'm doing spaces every Thursday.
[01:27:55] Many of the folks will stay here, join, we'll talk about latest updates. This was an emergency one, and glad to hear the channel is gonna compile this into a podcast. So definitely subscribe to Latent Space. But everybody, thank you for joining and go, go play with the new tool tools we got.
[01:28:10] swyx: Let's go build.
The Functions API still has a practical limit because they count towards the (up to 16k) token limit, so you can now include more than 3 plugins, but not the entire universe
Since every completion charges on input and output, depending how much context you feed in vs how much you generate, this could be anywhere from a 5-24% effective price cut
Note that Google has released the 20B UL2, which is still comparatively unloved among the open source models because it isn’t yet listed on the Huggingface Leaderboard, while Falcon 40B still sits comfortably at the top (although to my knowledge nobody has yet independently reproduced their claims)

