


Want to help define the AI Engineer stack? >500 folks have weighed in on the top tools, communities and builders for the first State of AI Engineering survey! Please fill it out (and help us reach 1000!)
The AI Engineer Summit speakers & schedule is now live — Join the YouTube to get notifications + help us livestream!
This Oct, your cohosts are running two Summits and judging two Hackathons . As usual, see our Discord and community page for all events.
A rite of passage for every AI Engineer is shipping a quick and easy demo, and then having to cobble together a bunch of solutions for prompt sharing and versioning, running prompt evals and monitoring, storing data and finetuning as their AI apps go from playground to production. This happens to be Humanloop’s exact pitch:
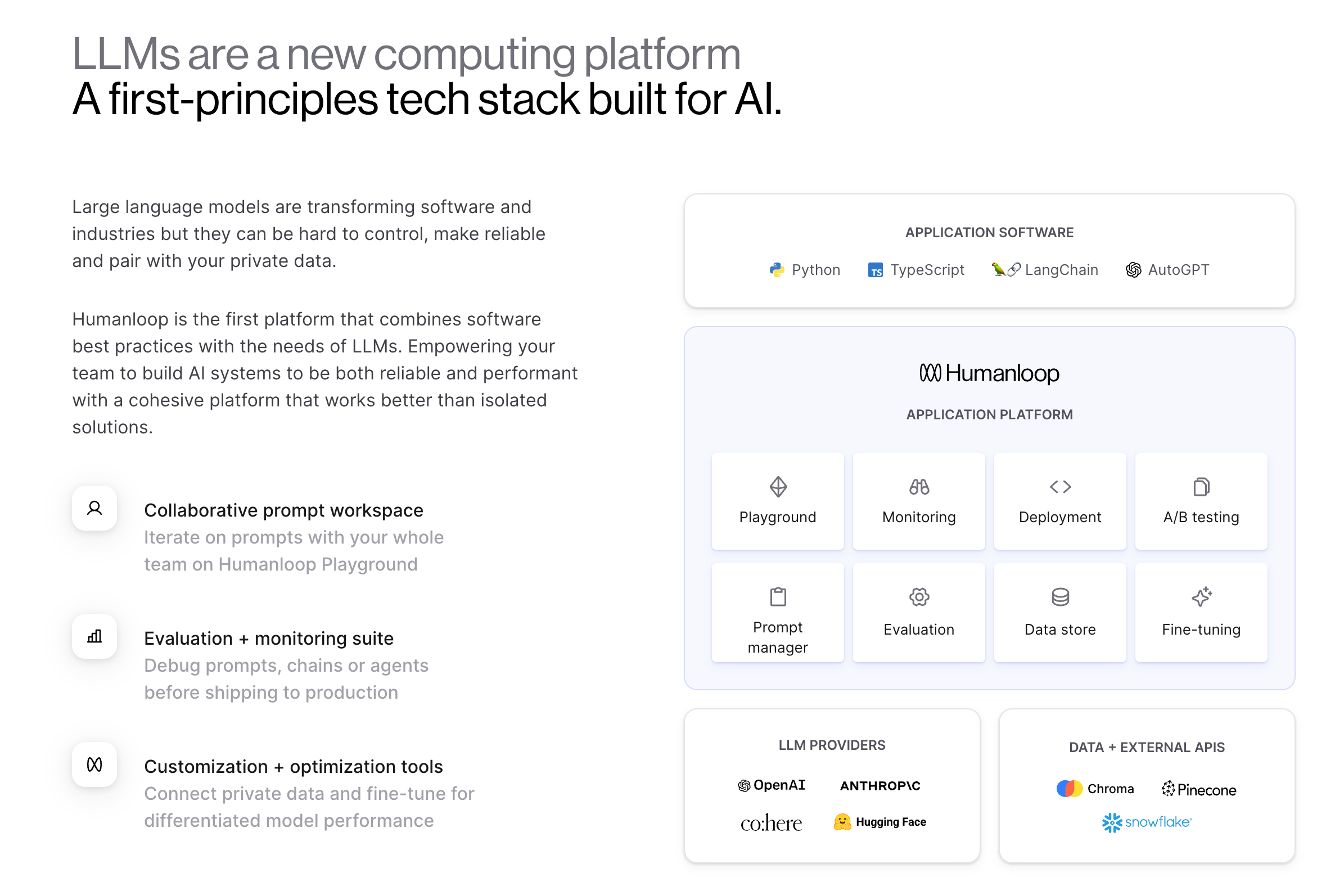
Humanloop didn’t start there - the team joined YC S20 and raised a seed round on a belief in NLP, but focused on automated labeling, but after InstructGPT (the precursor research to `text-davinci-*` and later models) came out, it was clear that the market for labeling would be in freefall. Pivoting wasn’t an easy decision — as Raza tells it:
“…a little over a year ago we pivoted. And that was scary because we had a thing that was working. We had paying customers, like it was growing reasonably, we'd raised money. And I went to, we went to our investors at the time. And I remember having a conversation. We did a market size estimate… at the time we did it, I reckon[ed] there were [only 300 companies in the world working with OpenAI’s API].”
Fortunately, that estimate was a few orders of magnitude too low. Today, Raza estimates that the market for LLM Ops is going to be bigger than software ops (where Datadog is the $30b gorilla in the space).
Note: There’s a bit of a turf war between “LLMOps”, “PromptOps”, and “LM Ops” terminologies, but for the titles we’ll adopt “Foundation Model Ops”, which is Raza’s preferred term.
The Foundation Model Ops Landscape
There are any number of VC market maps (e.g. Sequoia, a16z, Madrona) mapping startup formation. In creating the State of AI Engineering survey, we had to for the first time draw lines on what we thought the useful categories might be, and swyx had to present this for the first time on his Software 3.0 keynote:

All categories are flawed, but some are useful. There is a high level of overlap between the prompt management tools and the LLM API logging tools and Humanloop, like its other counterparts, would probably argue that their features cross boundaries. We draw this table based on subjective judgment on where their “core” competency is, but it is useful for people to consider how the landscape of “Foundation Model Ops” tooling vendors lines up vs their own needs.
Most experienced devtool investors know that devtool markets usually come in threes: three parts of a stool that individually make sense, but collectively start jostling for the limited budget (and funding) available in their larger category (and will eventually be guided by their market to build or buy each others’ features in the process)1. The third leg of the Foundation Model Ops market2 is likely going to be the open source LLM framework/tooling startups, who, like we discussed with LangChain, will all build their own specialized-yet-generalizable-if-you-squint tooling to serve (and monetize) their users.
If this is true, having a strong opinion on how people do things will help companies stand out. Raza is keenly aware of this:
“Because otherwise you end up I think, with a lot of very undifferentiated products that they're for everybody, so they're not for anyone.”
The Only Way To Know if GPT-4 Got Dumber
The “nerfing” of GPT-4 is a popular community topic that was supported by some credible evidence from Stanford, but we ultimately agree with Raza: GPT-4 is definitely not static, and probably got better in some areas, worse in some things, and the only way to tell is to run comprehensive benchmarks regularly over time, which ~nobody seems to have done conclusively (including Stanford) due to the prohibitive cost and limited API of these models.
In other words, it’s not really important whether GPT-4 got dumber overall, but it’s mission-critical to know if GPT-4 suddenly got worse for your usecase.
Humanloop’s approach is the eminently sensible one - when dealing with a closed source, unpredictable LLM API, where the maximum time you can pin a model is 6 months (as per OpenAI), the only recourse is to build or buy a Foundation Model Ops platform that can help you understand if your prompt results are declining in quality based on your own evaluations and your user feedback.
This is why Humanloop has now added an Evaluators feature, which lets you write code or use LLMs to run evals on random samples of your Humanloop workloads and track regressions and improvements over time.

All in all this turned out to be the definitive discussion and episode covering the brief recent history of the Foundation Model Ops industry, and we hope you enjoy it!
Timestamps
[00:01:21] Introducing Raza
[00:10:52] Humanloop Origins
[00:19:25] What is HumanLoop?
[00:20:57] Who is the Buyer of PromptOps?
[00:22:21] HumanLoop Features
[00:22:49] The Three Stages of Prompt Evals
[00:24:34] The Three Types of Human Feedback
[00:27:21] UI vs BI for AI
[00:28:26] LangSmith vs HumanLoop comparisons
[00:31:46] The TAM of PromptOps
[00:32:58] How to Be Early
[00:34:41] 6 Orders of Magnitude
[00:36:09] Becoming an Enterprise Ready AI Infra Startup
[00:40:41] Killer Usecases of AI
[00:43:56] HumanLoop's new Free Tier and Pricing
[00:45:20] Addressing Graduation Risk
[00:48:11] On Company Building
[00:49:58] On Opinionatedness
[00:51:09] HumanLoop Hiring
[00:52:42] How HumanLoop thinks about PMF
[00:55:16] Market: LMOps vs MLOps
[00:57:01] Impact of Multimodal Models
[00:57:58] Prompt Engineering vs AI Engineering
[01:00:11] LLM Cascades and Probabilistic AI Languages
[01:02:02] Prompt Injection and Prompt Security
[01:03:24] Finetuning vs HumanLoop
[01:04:43] Open Standards in LLM Tooling
[01:06:05] Did GPT4 Get Dumber?
[01:07:29] Europe's AI Scene
[01:09:31] Just move to SF (in The Arena)
[01:12:23] Lightning Round - Acceleration
[01:13:48] Continual Learning
[01:15:02] DeepMind Gato Explanation
[01:17:40] Motivations from Academia to Startup
[01:19:52] Lightning Round - The Takeaway

Transcript
via Descript… errors are verbatim
[00:00:00] AI Anna: Welcome to the Latent Space Podcast, where we dive into the wild, wild world of AI engineering every week. This is Anna, your AI co host. Thanks for all the love from last episode. As an AI language model, I cannot love you back, but I'll be standing in for Alessio one last time. This week we have Dr. Raza Habib, co founder and CEO of Humanloop, which is arguably the first and best known prompt engineering or prompt ops platform in the world.
[00:00:32] You may have seen his viral conversation on YC's YouTube on the real potential of generative AI. Fortunately, we go much more in depth. We ask him how they got to PromptOps so early, what the three types of prompt evals and the three types of human feedback are, and confront him with the hardest question of all.
[00:00:50] Is prompt engineering dead? At the end, we talk about whether GPT 4 got dumber. The most underrated AI research, the Europe AI startup scene, and why San Francisco is so back. By the way, dear listener, we will be presenting the AI Engineer Summit in October, and you can tune in on YouTube and take the state of AI engineering survey at the URL AI dot engineer summit.
[00:01:13] Watch out and take care.
[00:01:16]
[00:01:21] Introducing Raza
[00:01:21]
[00:01:21] swyx: So welcome to Latent Space. I'm here with Raza Habib CEO of HumanLoop. Welcome.
[00:01:31] Raza Habib: Thanks so much for having me. It's an absolute pleasure. And
[00:01:33] swyx: we just spent way too long setting up our own studio as sound engineers. I, I don't think something that either of us woke up today thinking that we'd be doing,
[00:01:42] Raza Habib: but that was really funny.
[00:01:43] Gives you greater appreciation for the work of others.
[00:01:46] swyx: Yes, Dave, you are missed. Dave is our sound engineer back in SF, who handles all this for us. So, it's really nice to actually meet you and your team in person. I've heard about HumanLoop for a long time. I've attended your webinars, and you were one of the earliest companies in this space.
[00:02:02] So it's an honor to meet and to get to know you a little bit
[00:02:05] Raza Habib: better. No, likewise. I've been excited to chat to you. You definitely, are building an amazing community and I've read your blogs with a lot of interest.
[00:02:11] swyx: Yeah and I'm, you know, based on this, I'm going to have to write up human loop. So this actually forces me to get to know human loop a lot better.
[00:02:17] Looking forward to it. So I'll do a little quick intro of you and then you can fill in with any personal side things. Sure. So you got your MSc and doctorate. At UCL in, it says here, machine learning and computational statistics, which are, I think, mostly the same
[00:02:34] Raza Habib: thing? Yeah, so the master's program is called machine learning and computational statistics, and then my PhD was just in probabilistic deep learning.
[00:02:40] So, trying to combine graphical models and Bayesian style approaches to machine learning with deep learning.
[00:02:46] swyx: Awesome. And did you meet Jordan in Cambridge?
[00:02:49] Raza Habib: So Jordan and I overlapped at Cambridge a bit. We didn't know each other super well. And we actually met properly for the first time at a PhD open day.
[00:02:55] And I ended up doing the PhD. He ended up going to work for a startup called Bloomsbury AI that got acquired by Facebook. But hilariously, his first boss was my master supervisor. And we didn't end up sort of doing PhDs together, I was often in their offices in those early years.
[00:03:11] swyx: Yeah, very small worlds.
[00:03:12] And we can talk about being in other people's offices because we are in someone else's office.
[00:03:17] Raza Habib: Yeah, so we're in the offices of Local Globe at Phoenix Court. Local Globe is one of the best seed investors in Europe and they were one of our first investors. And they have, yeah, just these incredible facilities.
[00:03:28] You saw just now outside a space for a hub for all their startups and other companies in the ecosystem to come work from their offices. And they provide these podcasting studios and all sorts of really useful resources that I think is helping grow the community in Europe. Yeah.
[00:03:43] swyx: And you said something which I found really interesting.
[00:03:45] They put on a lease. They have the building for 25 years.
[00:03:48] Raza Habib: Yeah, I can't remember if it's 25 or 20, but a really long time. They've made a conscious decision to invest in what is not one of the wealthiest parts of the city of London. Yeah. And give themselves a base here, go where the action is, and also try and invest in the local community for the long term and give back as well.
[00:04:03] I find that really inspiring. They think not just about how do we build truly epic companies and technology, but what is the social impact of what we're doing, and I have a lot of respect for that. Yeah, it's pretty
[00:04:12] swyx: important. And something I care about in SF as well, which has its own issues.
[00:04:16] So coming back to your backgrounds while you were going through your studies, you also did some internships in the buyside in finance which is something we connected
[00:04:25] Raza Habib: about. Yeah. So I sort of, I did some buyside internships in, in QuantFinance. I spent a year almost at Google AI working on their speech synthesis teams.
[00:04:34] And I helped a really close friend start his first company, a company called Monolith AI that was doing machine learning for physical engineering, so really high stakes. Our first customer was McLaren, which was really cool. So a day a week of my PhD, I was sitting in the McLaren offices, literally next to, and I mean literally, like I could almost reach out and touch it on an F1 car and we were trying to help them use machine learning to reduce how much physical testing they had to do.
[00:04:57] Right.
[00:04:57] swyx: So
[00:04:57] Raza Habib: simulations? Simulations. So surrogate modeling. Can you take these very expensive CFD solvers and replace them with neural nets? And also active learning. So they do a lot of physical experiments that if you run an experiment, you get some amount of information back and then you do something really similar and a bit of the information overlaps.
[00:05:16] And so they would put a car in a wind tunnel, for example, and they'd sort of adjust the ride heights of the car at all four different corners and measure all of them, which is really wasteful. And you spend a whole day in the wind tunnel. So we had an AI system that would basically take the results of the most recent tests you did and say, okay, the ones that will, you'll learn the most from are this set of experiments.
[00:05:34] You should do these experiments next. You'll learn a lot quicker, which is a very similar technique that we used at the early days of human loop to, to make machine learning models learn more efficiently as well. Yeah.
[00:05:43] swyx: I get the sense. By the way, I've talked to a number of startups that started with the active learning route.
[00:05:48] It's not as relevant these days with language models.
[00:05:52] Raza Habib: So I think it's way less relevant because you need so much less annotated data. That's the big change. But I also think it's actually really hard to productize. So even if you get active learning working really well... And I think the techniques can work extremely well.
[00:06:05] It's difficult to abstract it in such a way that you can plug your own model in. So you end up either having to own the model, like, you know, I think OpenAI could probably do this internally, but trying to go to a machine learning engineer and sort of let them plug their model into an active learning system that works well is really hard challenge.
[00:06:22] Yeah. And, and from a business perspective, it's also. Andresen, PHP, Gatsby, SREs, Temporal, SaaS, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding,
[00:06:51] swyx: You have to have a commitment to good process and good science. Yeah. And trust that, that actually does work out without evidence or a counterfactual, you know, tests or like a control group because that would be an extreme waste of money. Absolutely. So the chronology here is super interesting, right?
[00:07:08] Because you started your PhD in 2017. You just got it in 2022, about a year ago. Yeah, that's right. So that overlaps with your work on monolith AI and then you also started HumanLoop in 2020. So just take, take me through that interesting
[00:07:24] Raza Habib: journey. So I wouldn't recommend this, by the way, like I, I'm a big advocate of focus within HumanLoop.
[00:07:30] We try to be very focused, but I also just always had this itch to be part of companies and building things. To be fair, I think it helped as a researcher because it gave you tangible, real world problems and experience. I think in academia it's really easy otherwise to just work on things that seem interesting to you but maybe don't have such a big impact.
[00:07:49] So the way it came about, I was in the PhD and a very close friend, Richard Alfeld, who's now the CEO and founder of Monolith AI, they're a Series A, almost Series B company And he was starting this company, came to me and he said, you know, I need someone who's on the ML side. Just whilst I'm getting started, can you help out?
[00:08:05] And so it was meant to be this very short term thing initially. I got sucked into it. I was spending, you know, at least a day a week, if not more of my PhD early on. But it was really fun, right? We were sitting in the offices of McLaren. They were our first customer. I think Airbus was an early customer. I helped hire the early team.
[00:08:19] And it was a really good experience of trying to do machine learning. in the real world, at high stake situations, right physical engineering and understanding what did and didn't work. So I'm really glad I got that experience and it made me much more excited about starting a company. But that was still a part time thing and I think my supervisor sort of knew I was doing it, but it was it was it was a low enough time commitment that I could hide and still be focused on my PhD most of the time with human loop it was different like the way human loop came about.
[00:08:46] I came back from doing my internship at google in in Mountain View. And Doing the internship at Google convinced me that I loved Google, but I didn't want to work there in the near term. I wanted to be working on some, in a space where there was a lot more urgency, where it felt existential, where we were all focused on the same problem as a team pulling together.
[00:09:03] And at Google, it just felt like you were part of something very big. I was surrounded by really smart, really capable people. I learned a lot from them. But the environment was more comfortable. And I wanted to be in a small, I wanted to be in a startup, really. And so, when I came back from Google, I sort of started thinking about ideas and, and speaking to the smartest people I knew to kind of see whether we could do something for when I finish the PhD.
[00:09:26] That was the point. I was just doing research. But Peter Jordan and I started working together in that process. We were all at a similar stage of kind of trying to find other people we might want to work on side projects with, and one of the side projects basically became Human Loop. And we got into YC, and we were like, okay, well, this is a great opportunity.
[00:09:41] Let's, let's go do it. And just kind of one domino fell after another. And so didn't quite finish the PhD, but had enough research that I probably could have been writing up. And so at some point I got an email from UCL and they were like, if you don't submit in the next, whatever, I think it was two months, it expires.
[00:09:58] Then it expires. And I was, you know, I, I almost didn't do it because obviously running a startup is such a full time gig, but I had invested a lot of time. The honest reason why I did it as two things, one, my grandfather who recently passed away had just really wanted to see me finish. And so. You know, probably not super rational, but I just wanted to do that for that reason.
[00:10:18] But the other is I really love teaching. I, when I was at, when I was a PhD student, I did a lot of TAing. I TAed the courses at the Gatsby, which are the ones, it's the institute that Jeff Hinton started when he was there. And I really enjoyed that. And I just knew that having a PhD would make it easier one day to come back to that if I want to do a little bit of teaching at a university.
[00:10:36] Having that title helps. It's like an adjunct, I don't
[00:10:38] swyx: know if they have adjunct appointments here or maybe lecture appointments. Yeah, something
[00:10:41] Raza Habib: like that. I can't imagine doing it whilst running the startup, but, but afterwards, yeah.
[00:10:45] swyx: I've always wondered if I can give back in some shape or form. But maybe you might with your, your podcast and when get that started.
[00:10:52] Humanloop Origins
[00:10:52] swyx: What was the original pitch for HumanLoop? You said it grew out of
[00:10:54] Raza Habib: a side project. So when we started HumanLoop, both Peter, Jordan, and I had this strong conviction about the fact that NLP was getting phenomenally better. This was before GPT 3, but after BERT and after transfer learning had really started to work for NLP.
[00:11:09] That you could pre train a large language model on an unlabeled corpus and really quickly adapt it to new situations. That was new for NLP. And
[00:11:16] swyx: so did GPT 1
[00:11:18] Raza Habib: and 2, or? GPD 1 and 2 had happened, but we were thinking about BERT, we were thinking about ULMfit as the first milestones that showed that this was possible.
[00:11:26] And that the kind of, it was very clear that as a result, there was going to be a huge wave of. You know, useful applications that enterprises could build on NLP that weren't previously possible. Mm hmm. But that there was still a huge lack of technical expertise and annotated data was still a big bottleneck.
[00:11:43] We were always trying to make it a lot easier for developers and for companies to adopt NLP and build useful AI products. But at the time that we started, The bottleneck was mostly, okay, do you have the right ML expertise and can you get enough annotated data? And so those were the problems we were initially helping people solve.
[00:12:00] And when GPT 3 came out I wrote a blog post about this at the time. It was very clear that this was going to be the future, that actually, because in context learning was starting to work, the amount of annotated data you would need was going to go down a lot. But until the InstructGPT papers, it still didn't feel practical.
[00:12:15] But after InstructGPT came out once you've kind of mentally done that shift, it's very hard to keep working on anything else.
[00:12:22] And so a little over a year ago we pivoted. And that was scary because we had a, we had a thing that was working. We had paying customers, like it was growing reasonably, we'd raised money. And I went to, we went to our investors at the time. And I remember having a conversation. We did a market size estimate.
[00:12:37] I actually filled out the YC application, because I think the YC application is like the simplest business model you could possibly build, right? What are you going to build? Who's it for? How are you going to make money? How big is the market? And I did the market size question, and at the time, we did it, and I was like, I reckon there are maybe three or maybe four hundred companies in the world who might need a product like this.
[00:12:53] And the assumption was that, like, okay, it's tiny today. It's mostly a small number of startups, but it will be huge in the future and that turned out clearly to be right. I didn't realize how quickly it would happen. Yeah,
[00:13:04] swyx: It's obviously surprised I think a lot of us but you were paying attention to the research when I guess a lot of people were not necessarily looking at that.
[00:13:13] Like, to my understanding, you didn't have previous NLP. knowledge, or back on, right? You, you, you, you did speech
[00:13:23] Raza Habib: synthesis. I did speech synthesis. I did fundamental methods in any... I wasn't specialized. I was working on generative models, variational inference. I would actually say... Like,
[00:13:32] swyx: how did you know this was the thing to focus
[00:13:34] Raza Habib: on, right?
[00:13:35] Well, so the interesting thing is that like, you don't need any NLP expertise to have gotten the like current wave of deep learning, right? Or machine learning. Like if anything, I think having...
[00:13:51] And But at the time, there was only one lecture on deep learning, right? And this was 2016, 2017 or something, or 2015, 2016. The NLP community was still... You know, just waking up to the fact that deep learning was going to change everything. And the amazing thing about most machine learning actually, it's another example of the bitter lesson that we were talking about earlier, right?
[00:14:11] Like general purpose learning methods at scale with large volumes of compute and data are often better than specialist systems. So if you understand that really well, you're probably at an advantage to someone who only understands the NLP side, but doesn't understand that. I don't
[00:14:26] swyx: know if it's understanding so much as believe.
[00:14:30] Raza Habib: I think you're right. It's a bit of both. Cause
[00:14:33] swyx: I don't even think we fully understand it today. One leads to the other. Yes. Yes. That you, that you take the evidence. Seriously, yeah, and then you extend it out and it still works and you just keep going Absolutely. So you got the TAM size wrong On on the positive side at the time.
[00:14:50] We were
[00:14:50] Raza Habib: right. I think really okay Yeah And I and I know we were roughly right because we were spending a lot of time speaking to open AI And we were asking them like how many? You know, like we were, they were sending us customers and we were discussing it and we were asking about API usage, like how many big companies are there?
[00:15:04] And there was a small number at the time. Yeah, but it just rocketed since then.
[00:15:07] swyx: Okay, so You were planning to build very closely in partnership with OpenAI.
[00:15:14] Raza Habib: As in, we've always tried to keep close partnerships with all of the large language model providers, right? It's very clear that Andresen, GP, semaphores, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, sharding, Make it easier for their customers to succeed benefits them, and then we also get to learn from them about what problems people are facing, what they're planning to do in the future, so I think that all of the large language model providers are investing a lot in developer ecosystem, and not just being close to HumanLoop, but to anyone else who's making it easier for their customers.
[00:15:59] Yeah,
[00:15:59] swyx: awesome. Okay, so you started the company.
[00:16:01] Raza Habib: How did
[00:16:02] swyx: you split things between the co founders?
[00:16:04] Raza Habib: It happened very organically. Remember, we're all, on paper, we look really similar. Peter also has a PhD in machine learning, amazing engineer, previously been a CTO, Jordan has a master's in machine learning, like, really good engineer as well.
[00:16:16] As we came to work on it, it just turned out we had natural strengths and interests. That happen very, very organically. So Jordan is the kind of person who's got an amazing taste for product. He just notices things day to day. Like if he finds a product experience he really likes, you see his eyes light up, he's paying attention to it all the time.
[00:16:30] And so it made a lot of sense that he over time gravitated towards user experience. The design, actually thinking through the developer experience and leading on product. Peter. So, I got phenomenal stamina and amazing engineering knowledge and amazing attention to detail and naturally gravitated towards taking on leading the engineering team.
[00:16:48] And I like doing this. I like chatting to people on podcasts, I like speaking to customers a lot. That's probably my favorite part of the job. And so naturally, I kind of ended up doing more of that work. But it wasn't that we sat down initially and said, okay, you're going to be the person who does sales and invest.
[00:17:03] It was much more organic than that. Yeah. Yeah.
[00:17:06] swyx: And you had to pick your customers, so what did you end up picking?
[00:17:09] Raza Habib: So in the end, our customer changed dramatically when we launched the latest iteration of HumanLoop. When we decided to focus much more on large language models, we suddenly went from a world in which we were building predominantly for machine learning engineers, people who knew a lot about ML, maybe had research backgrounds, to building for...
[00:17:27] And a much more product focused. Yeah, engineers. Something that, you know, some people I think would refer to as an AI engineer. So I've heard. And these are people who are much more focused on the outcome, on the product experience, on building something useful, and they're much more ambivalent towards the means that achieve the end.
[00:17:44] Yeah. And that works out as a much better customer for a tooling provider as well because they don't fight you to build everything themselves, they want good tools and they're happy to pay for them. Because they're trying to get to a good outcome as quickly as possible. So we found, we found a much better reception amongst that audience and also that we could add a lot more value to them because we could bake in best practices and knowledge we had, and that would make their lives much easier.
[00:18:05] And they didn't need to know so much about machine learning.
[00:18:07] AI Engineers in 2021
[00:18:07] swyx: Where do you find them? Because this is in like early 2021. Yeah. There were no.
[00:18:17] So, how did you find these early
[00:18:19] Raza Habib: adopter types? So, we could see some people using GPT 3. And so we would like directly reach out to companies that were building on GPT 3. And in the early days, you know, when we first did it, before we did the pivot, we gave ourselves a two week sales experiment. We said, let's take our designs and our initial idea.
[00:18:34] And let's see if we can get 10 paying customers in two weeks. And on the second day we had 10... And paying for what specifically? So we, we were just pitching them on being part of a development partnership. So we said, we're going to, we're building a tool that will help you with prompt engineering and evaluating how good your prompts are.
[00:18:50] This is what it looks like. We're looking for design partners. It costs this much to be a design partner. And On the second day, we already had 10. And so we were like, okay, there's a real problem here because people were feeling the pain and they were showing us their jerry rigged solutions for this.
[00:19:04] They were showing us how they would stitch together Excel spreadsheets and Grafana and Mixpanel and the OpenAI Playground in these like very kludgy pipelines to somehow quickly iterate on prompts, version them, collaborate as a team, find some way to measure things that were very subjective. And so we were like, okay, actually, there's a very clear need here.
[00:19:23] Let's go help these people. Yeah,
[00:19:25] swyx: excellent.
[00:19:25] What is HumanLoop?
[00:19:25] swyx: So what is HumanLoop
[00:19:27] Raza Habib: today? Yeah, so at its core, we help engineers to measure and optimize LLM applications. So, in particular, helping them do prompt engineering, management, and then evaluation. So evaluation is particularly difficult for large language models because they tend to be used for much more subjective applications than traditional machine learning.
[00:19:46] Definitely than traditional software, right? If you're coming from a pure software, non ML background, then the first thing you have to learn when you start working with LLMs is this stuff is stochastic which I think, you know, most people are not used to. So just playing with software that every time you run it, it's different and you can't just write unit tests.
[00:20:00] Yeah. It's the first kind of painful lesson. But then it turns out that a big piece of these applications ends up in prompts, and these are natural language instructions, but they're having similar impact to what code has. So they need to be treated with the importance of code. And so iterating on that, managing it, versioning it, evaluating it, that, those are the problems that HumanLoop helps engineers with today.
[00:20:19] And in particular, we tend to be focused on companies that are at a certain scale, because one of the challenges that, one, they tend to care more about evaluation. I think if you're a two person startup, you sort of build something quick MVP it into production. But larger companies need to have some confidence of the product experience before they launch something.
[00:20:38] And also what we've found is that there's a lot more collaboration between engineers and non engineers, between product managers and domain experts who are involved in the design, the prompt engineering, the evaluation. But are maybe not the engineering part, and they have to work together nicely, so giving them the right tools has been a really important part as well.
[00:20:56] Yeah.
[00:20:57] Who is the Buyer of PromptOps?
[00:20:57] swyx: Something I've often talked about with other startups in this space is who's the buyer. Yeah. Because you talked about collaboration between the engineer and the PM, or... whoever. And it's not clear sometimes. Do you have a clear answer? It
[00:21:11] Raza Habib: varies highly on company stage. So in the, in the early days when we started human loop, you said, where do we find our customers, right?
[00:21:17] They were all startups and scale ups because those were the only people building with GPT 3 more than a year ago. There, there was no large companies. And there it was always founder, CTO. Even if there were 10, 20 person companies, series A companies, always founder. Who is speaking to reaching out to us, who's helping build it.
[00:21:31] So like an example here, you know, one of our earliest customers was Mem and it was Dennis at Mem who was kind of the person we were speaking to. Now that we're at a bit more at scale and we're speaking to larger companies, it's a little bit more varied. Surprisingly, it's still quite often senior management that first speaks to us.
[00:21:46] So with Duolingo, it was Severin, the CTO was actually our first contact. Just inbound. Inbound. But, but increasingly now it's people with who are engineers who are actually working on, on projects. So it's like a senior staff engineer or something like that will reach out, book a demo. They'll probably sign up first and have a play, but then they tend to book a demo because they want to discuss data privacy and how things will be rolled out and, and sort of going beyond just individual usage.
[00:22:14] But that's the, that's the usual flow is we see them sign up. Sometimes we reach out to them, often they'll reach out to us, and then the conversation starts.
[00:22:21] HumanLoop Features
[00:22:21] swyx: Yeah, yeah. Awesome. For people who want to get a better sense of human loop the company. I think the website does a fantastic job of explaining it
[00:22:29] Raza Habib: Thank you.
[00:22:29] We're always
[00:22:30] swyx: working on it. Put in quite a lot of work. So it says here human loop application platform includes a playground, monitoring, deployment, A B testing, prop manager, evaluation, data store, and fine tuning And based on our chat earlier, it seems like evaluation is kind of the more beta one. That's in sort of like a private beta That's
[00:22:48] Raza Habib: correct.
[00:22:49] The Three Stages of Prompt Evals
[00:22:49] Raza Habib: Yeah. So we have evaluation in private. There's, there's always been some aspect of evaluation. It was actually the first problem that we were solving for customers. But evaluation in human loop early on, early on was driven entirely by end user feedback. So so if you're building an LLM app, there's probably three different places where evaluation matters a lot.
[00:23:06] There's the evaluation that you need when you're Iterating in design, and you haven't got something in production yet. Mm-hmm. , but you just need feedback on as you're making changes, are you making things better? You're iterating on prompts, you're iterating on the context, trying out different models, like how do you know that the changes are actually improving things.
[00:23:21] Then once you're in production, there's sort of a form of evaluation you need for monitoring. Is this, you know, it seemed to work when I was in development, but now I'm putting a whole bunch of different customer inputs through it. Is it still performing the way that I expect it? And then the last one is something like equivalent to integration tests or something like this.
[00:23:37] Every time you make a change, how do you know you're not making it worse on the things that are already there? And so I think we always had a really good version of the monitoring user feedback version. But what we were missing was support for offline evaluation and being able to do evaluation during development or regression testing.
[00:23:52] And we're going to be launching something for that very soon.
[00:23:54] swyx: Yeah, this isn't slightly unintuitive to me because I just I would typically just assume they're all three are the same evals
[00:24:02] Raza Habib: Yeah, so they can't necessarily be the same evals just because You don't have the user feedback at the time that you're in development.
[00:24:11] I'm not
[00:24:11] swyx: thinking about user feedback. I'm just thinking about validating the output that
[00:24:14] Raza Habib: you get. Yeah, so you're validating in similar ways, but if you're doing a really subjective task, then I think the only real ground truth is what your customers say is the right answer, right? If you're building copilot, like do the customers accept the code suggestions or not?
[00:24:25] Yes. That is the thing that ultimately matters. And you can only have proxies for that in development. And so that was why those two things end up being different. Yeah.
[00:24:34] The Three Types of Human Feedback
[00:24:34] swyx: And in terms of the quality of feedback so we did an episode with Amplitude, which, you know, is an analytics platform dedicated for collecting this kind of behavioral feedback.
[00:24:45] And you mentioned Copilot. There was a very famous post about reverse engineering co pilot that shows you the degree of feedback. I think typically when people implement these things, they implement it as a sort of thumbs up, thumbs down sort of binary feedback until you find that nobody uses those.
[00:25:02] Nobody does those feedback. Like I barely use the up down on chat GPT. Yeah.
[00:25:06] Raza Habib: So this was something we learned really early on in building human loop. And you know, we, the feedback aspects of human loop were very Customer driven. People were, the people who are getting amongst our early users, the people who are getting traction and who had built something that was working well, had jerry rigged some version of feedback, collection and improvement themselves.
[00:25:24] And they were pushing for something better here. And they all. We're collecting usually three types of feedback, and HumanLoop supports all three of these. So you have the thumbs up, thumbs down type feedback that you just described. You don't get much of it. It's useful when you get it, but you don't get that much.
[00:25:38] And then the other form of feedback, so we call that votes. And then you have actions, and these are like the implicit signals of user feedback. So I can give a concrete example here. There's a company I really like called Sudowrite. And Sudowrite, founded by James Yu, and they're building editor experience for fiction writers that helps them.
[00:25:54] So as they're writing their stories or novels, there's a sidebar and you can highlight text and you can say, like, help me come up with a different way of saying this or in a more evocative way, you know, there's many different features built in. And they had built in early on. You know, analytics around does the user accept a suggestion?
[00:26:11] Do they refresh and regenerate multiple times? How much do they edit the suggestion before including it in their story? Do they then share that? And all of those implicit signals correlate really well with the quality of the model or the prompt. And they were like running experiments all the time to make these better.
[00:26:26] And you could just see it in their traction figures. As they figured out the right prompt, the right features, the things that people were actually including, the product became much more loved by their users.
[00:26:37] swyx: Let's see our third.
[00:26:38] Raza Habib: And the third one is corrections. So this helps particularly when you want to do fine tuning later on.
[00:26:45] So anywhere you're exposing generated text to a user and they can edit it before using it, then that's worth logging. So a concrete example here is we have a couple of customers who do sales email generation and they generate a draft, someone edits it, and then they send the draft. And so they capture the edited drafts.
[00:27:00] swyx: And I think A lot of this is sort of preemptive, right? They're not, they don't necessarily use that capture data immediately, but it's there if they want it for Absolutely fine tuning for validating prompt changes and anything
[00:27:14] Raza Habib: like that. Exactly. Yeah, exactly. It's data that you want to have and you want to have in an accessible way such that you can improve things over time.
[00:27:20] Yeah.
[00:27:21] UI vs BI for AI
[00:27:21] swyx: And you tend to, you have a UI to ex expose it. But do you think that people use that UI, or do they, do they prefer to export it to, I don't know, Excel? Or, how do people like to consume their data, once they've captured it?
[00:27:34] Raza Habib: Yeah, so we see a lot of people using it in the UI. And part of the reason for that is we have this bidirectional experience with an interactive playground.
[00:27:42] So we have the ability to take the data that was logged in production, and open it back up in an environment where you can rerun the models when you make changes. And that ability has been really important for people to reason about counterfactuals. Oh, the model failed here. Yeah. If the context retrieval had worked correctly, would the model have succeeded?
[00:28:00] And they can really immediately run that counterfactual. Or is it a problem with GPT 3. 5 versus 4? So they'll run it with 4 and see what... You know, does that fix it? And that lets them build up an intuition about why things have worked or haven't worked. People do export data sometimes. So we, we allow people to format the data in the right way for fine tuning and then export it.
[00:28:18] And that's something we see people do quite a lot if they want to fine tune their own models. But we try to give fairly powerful data exploration tools within HumanLoop.
[00:28:26] LangSmith vs HumanLoop comparisons
[00:28:26] swyx: What about your integrations with the rest of the ecosystem? On your landing page, you have LangChain, all the GPTs mentioned, Chroma, Pinecone, Snowflake and obviously the LLM providers.
[00:28:36] Raza Habib: Yeah, so the way we see HumanLoop is sitting, you know, between the base LLM providers, and an orchestration framework like code, you know, LangChain or LlamaIndex might sit sort of separately to that. You know, you, you have this analogy, I think, of like LLM first or code first AI applications and we're very strongly of the opinion that like most things should be happening in code, right?
[00:28:57] That developers want to write code, they want to orchestrate these things in code, but for the pieces that require LLMs, You do need separate tooling. You need the right tools for prompt engineering. You need some way to evaluate that. And so we want HumanLoop to plug in very nicely into all of these orchestration frameworks that you might be using or your own code and let you collect the prompts, the evaluation data that you need to iterate quickly, kind of in a nice UI.
[00:29:20] So it's
[00:29:20] swyx: So here's where LandChain collides
[00:29:22] Raza Habib: with you. Has started to now. Yes.
[00:29:25] swyx: Because they just released the prompts manager. And they also have a dashboard to observe and track and store their prompts and data and the results. They don't have feedback collection yet, but they're going to build
[00:29:38] Raza Habib: it.
[00:29:38] I'm sure they will. You know, it's a very vibrant ecosystem. There's lots of people running after similar problems and listening to developers and building what they need. So I'm not... I'm not, I'm not completely surprised that they've ended up building some of the features that we have. Because I think so much of what we need is, is really important for developers to achieve stuff.
[00:29:58] Yeah. I think one of the strongest parts of it is it's going to be very tightly integrated with LangChain, but a lot of people are not building on LangChain. And so for anyone for whom LangChain is not their production choice system, then I think actually it's going to be friction to work in that way. I think that there's going to be.
[00:30:14] There are a plethora of different options for developers out there, and they will find their own niches slightly. I think we're focused a little bit more, as I said, on companies where collaboration is very important, a little bit larger scale and slightly less so far. As an individual developer isn't quite the same way that Lanchain has been to date.
[00:30:31] swyx: That's a fair characterization, I think. It's funny because yeah, you are more agnostic than Lanchain is. And that is a strength of yours, but I've also worked for companies which have... Tried too hard to be Switzerland. Yeah. And to not be opinionated about anything. And it's been them in, oh,
[00:30:50] Raza Habib: you have, you have to have opinions, right?
[00:30:51] Yes. You've gotta, you've gotta bake into the, we learn a lot from our customers, and then we try to productize those learnings. So I gave you a concrete example earlier, right? On having good defaults or what types of feedback you can collect. Yeah, and that's not an accident. Like we're very opinionated about that because we've seen what's worked for the people who are getting to good results.
[00:31:09] And now if you sort of set up human loop with that, you naturally end up with the correct defaults. And there's loads of examples of that throughout the product where we're feeding back learnings from having a very rate large range of customers in production. To try and set up sensible defaults that you don't realize it, but we're nudging you towards doing the right thing.
[00:31:25] swyx: Oh, excellent. So that's a great, really great overview of the products surface area. I mean, I don't know if we left out anything that you
[00:31:32] Raza Habib: want to highlight. No, I think I think that's great. And you know, the focus for us, I think, being like a really excellent tool for prompt management, engineering, versioning, and also evaluation.
[00:31:42] So kind of combining those and making that easy for a team.
[00:31:46] The TAM of PromptOps
[00:31:46] swyx: What's your estimate of the TAM now?
[00:31:49] Raza Habib: I mean, eventually at the current rate of growth, right? I think it's really difficult to, it's difficult to put a size on it because how big it's going to be. Like. So, certainly like more than large enough for a venture backable outcome.
[00:32:03] Today I don't know, Datadog is something like a 35 billion company doing like web monitoring or whatever. I think LLMs and AI are going to be bigger than software. Yeah. And that market is going to be absolutely enormous. And so. Trying to put a size on the TAM feels a little silly, almost.
[00:32:19] Oh, I know.
[00:32:20] swyx: You had to do it for your exercise, so I just figured I'd get an update.
[00:32:23] Raza Habib: But it was a different world back then, right? At the time that I was doing it, trying to get people to take the idea of putting GPT 3 in production seriously was work. And most people didn't believe it was the future.
[00:32:33] It was like, it's difficult to believe this because it's only been a year, and I think everyone has kind of rewritten history, but I can tell you, because I was trying to do it, that a year ago, it was still contrarian to say that large language models were going to be the default way that people were building things.
[00:32:47] Yeah,
[00:32:47] swyx: yeah. Well, well done for being early on it and convicted enough to build a leading company doing that. I think that's commendable. And I wish, I wish I was earlier.
[00:32:58] How to Be Early
[00:32:58] Raza Habib: You've still been pretty early. You've done, you've done all right. It's, I, I
[00:33:00] swyx: do think, I do have this message because I think I talk to a lot of people who are, who feel like they've missed it.
[00:33:05] Raza Habib: But it's just beginning. It's still so early. Yeah, what,
[00:33:08] swyx: what would you point to, to encourage people who feel like they've missed you know, the boom?
[00:33:14] Raza Habib: I, I just think that The, I guess like a question to ask yourself if you missed chat GPT was why did you miss it? Yeah. And the people who didn't miss it, and I'm not necessarily including us in this.
[00:33:24] I think we were relatively late, even though we were earlier than most, like what did the people who get it right really grok or what did they believe, right? What did Ilya Suskovor or Shane Legg, the people who kind of saw this early, and I think it was a conviction about. Deep learning and scale and projecting forwards that, okay, if the, if we just project forwards the current improvements from deep learning and assume they continue, like what will the world look like?
[00:33:51] And if you, and if you do that today, and obviously it's extrapolating, right? That's not a, that's not a theory based prediction. It's just an extrapolation. But the extrapolation has been right for a really long time. So we should take it seriously. Yeah. If you extrapolate that forward just a year or two then you find that, you know, you would expect the models to be phenomenally better than they are today.
[00:34:08] And they're already at a scale where you expect large economic disruption, right? Even if GPT 4 doesn't get better. And you know, if all we get is GPT vision plus the current model, we know that there's loads of useful applications to be built. People are doing it right now. They're going to get better, right?
[00:34:23] This is the worst they're ever going to be. So if this is what's possible today, you know, I think the hardest challenge actually is to take seriously the fact that in the not too distant future, you will have models even more capable than the ones we have now. How do you build for that world? I think it's a difficult thing to do, but it's certainly extremely early.
[00:34:41] 6 Orders of Magnitude
[00:34:41] Raza Habib: Yeah, I
[00:34:41] swyx: think the quote that resonated with me this past week was Nat Friedman saying, imagine Everything that we have now with six orders of magnitude, more compute. By the end of the decade and plan for
[00:34:52] Raza Habib: that. Yeah. And that seems to me like a... Six orders is a lot. Six orders seems optimistic...
[00:34:59] But I think it's a good mental exercise, right? Even if it turned out only to be... If was only four orders or only three orders, right? It transformative. If GPT 4, instead of costing 40 million, or GPT, you know, whatever it costs, tens of millions of dollars, became tens of thousands of dollars. I've heard a total
[00:35:15] swyx: all in cost 500
[00:35:15] Raza Habib: million.
[00:35:16] So let's say it was 500 million today, and it became 1 million or 2 million. Yeah, yeah. That becomes accessible to... So, you know, even startups, let alone, you know, medium sized companies. And I think we should assume something like that will happen. I would say even without significant research breakthroughs on the modeling side, I would just expect inference costs to become a lot cheaper.
[00:35:34] So training is difficult to optimize from a research perspective, but figuring out how to quantize models, how to make hardware more efficient, that to me feels like you chip away at it and it'll just happen naturally. And we're already seeing signs of that. Yeah. So I would expect inference to get phenomenally cheaper, which is most of the cost.
[00:35:49] swyx: Yeah, and a previous guest that we had on by the time this comes out is Chris Lattner who is working on Compilation for Python that that's going to make inference a lot cheaper because it's going to fully saturate the actual compute that we already have. Yeah
[00:36:03] Raza Habib: So I think I think it's an easy prediction to make that inference inference costs come down phenomenally.
[00:36:09] Becoming an Enterprise Ready AI Infra Startup
[00:36:09] Raza Habib: Fantastic
[00:36:10] swyx: In my mind you went up market Faster than most startups that I talked to. So you started selling to enterprise and I see you have Duolingo Max and Gusto AI as case studies You have a trust report. You don't need SOC 2 It's just
[00:36:24] Raza Habib: we're in the process of so we have SOC 2 part 1 and we're currently being audited for SOC 2 part 2 Yeah, but you have the Vanta thing up.
[00:36:31] We have the Vanta thing up and we have we have the part 1 We have the trust report. We have regular pen tests We have to do a lot of this stuff in order to get to
[00:36:38] swyx: it to sell the enterprise. Yeah so I mean, I love the Vanta story. It's not ai. Yeah. But do you think that the Vanta Trust report is gonna work
[00:36:45] Raza Habib: in what sense?
[00:36:46] As a SOC two replacement?
[00:36:48] SOC two proxy? I don't know. Honestly, all I can say is that like, customers still care that we have SOC two. Yeah. And we're still having to go through it. Yeah. Van Vanti, even with SOC two though, Vanti makes the process of doing it. Phenomenally easier. Okay.
[00:37:03] That's a big annoyment. So I would, I would endorse the product. I've been less close to it than, than my co-founder, Peter and a couple of others. Oh yeah. There's always a
[00:37:09] swyx: van Vanta implementation, a stock to implementation person. Yeah. And that poor person is like, for a year they're dealing with this
[00:37:15] Raza Habib: but it's certainly been a lot faster because of, because of that.
[00:37:18] swyx: But just more broadly, like becoming an enterprise oriented company what if you had to. Change or learn.
[00:37:25] Raza Habib: Yeah, so I would actually say that, like, we've only done it because we were feeling the pull. Right. It, it, I wouldn't recommend doing it early if you can avoid it because you do have to do all of these things.
[00:37:37] SOC 2 compliance. And I think Peter is filling out a very long InfoSec questionnaire today. Right. And although you have most of the questions prepared, each one is just a little bit different. So there is just GPT to fill it out. There's this overhead on each time. No comment. And, but the potential gain for some of these larger companies, right, if they can make efficiency improvements of 1, 2, 4, 5 percent is so much bigger.
[00:38:04] And the efficiency improvements probably aren't 5%, they're probably 20%, 30%. And so when the upside is so large, you know, if you are a, if you're a large company, that's, you know, your costs are dominated, say, by customer support or something like this, then the idea that you might be able to dramatically improve that, or if you can make your developers much more efficient.
[00:38:23] There's just no shortage of things. And I think a lot of companies in the build versus buy decision, they want to do both because they want to have the capacity internally to be able to build AI features and services as part of their product as well. So they don't want to buy everything.
[00:38:37] Certain things, it makes a lot of sense. It's fully packaged. No one's building their own IDE. Like they're going to use copilot or whatever is the equivalent, but they want to be able to add, you know, I think the first AI feature that Gusto added was the ability within their application. For people who are creating job ads could put in a very short description and it would auto generate the first draft job ad and was smart enough to know that there are different legal requirements and what information has to be there for different states.
[00:39:04] So in certain states you have to, for example, report the salary range and in certain states you don't. It's pretty easy to like give that information to GPT 4 and have it generate you a sensible draft. But. That was, I think, something that they got to production, you know, within weeks of starting. And just to see such a large company go from zero to having AI features in production, and now they're adding more and more.
[00:39:26] It's been quite phenomenal.
[00:39:27] swyx: Yeah, the speed of iteration is unlike enterprise, which is fantastic. I think a lot of people see the potential there.
[00:39:36] I think people's main concern with having someone like HumanLoop in the loop is the data and privacy element, right? Do people want on prem HumanLoop?
[00:39:45] Raza Habib: So we do do VPC deployments where they're needed.
[00:39:48] We don't do full on premise. So far, most people, we've been able to persuade that they don't need it. So, so the, whenever someone says we need VPC, the first question I always ask is why? And then we go through what are the real reasons, like what are they concerned about? And we see whether we can find ways either contractually or, you know, in our own cloud to satisfy those requirements.
[00:40:07] There are exceptions, like we work now with some, you know, financially regulated companies. MXGBT is one of our customers, mXGPT is that Global Business Travel arm. And, you know, they've got very sensitive information. And so they're particularly concerned about it.
[00:40:23] And there's more auditing. But, for the people who are not financially regulated, usually we can persuade them that look, we have SOC 2, we're essentially there, we've got regular pentests, we follow really, like, high security standards. Most people so far have been accepting of that. Have
[00:40:41] Killer Usecases of AI
[00:40:41] swyx: you ever attempted to classify the use cases that you're seeing?
[00:40:45] Just, you see the whole universe, and you're not super opinionated about them. But, like, you know, there's summarization, there's classification, there's, you know,
[00:40:54] Raza Habib: Okay, so interesting. I've not, I've certainly not tried to classify them as that granularity. Like, is it summarization or question answering? I often think more about the end use case.
[00:41:04] So, like, is this an edtech use case? Right, that's the vertical to me. I think, I think a little bit more about it like that. In terms of use cases, it's really varied, right? There are people using the models as completion, there's chat, like it wouldn't be so obvious to know without doing some like GPT level analysis on it, like getting GPT to look at the outputs and inputs, which you can do, which we can do.
[00:41:28] Whether they're doing summarization or something similar, but I would say I feel like most use cases blend like that to me feels like an old school N L P way of viewing the world. Like an old school N L P. We used to break down these tasks into like summarization and N E R and extraction and QA, and then pipeline things together.
[00:41:43] And actually I feel like. That doesn't map very well onto how well, how people are using TP4 today. Because they're using them as general purpose models. And so it is one model that's doing NER, it's doing extraction, it's doing summarization, it's doing classification, and it's often in one, one end to end sort of system.
[00:42:01] swyx: I think that's, that's what people want to believe, that they're using them as general purpose models. But actually when you open up the covers and look at the volume, 80 percent of it is. Some really dumb use
[00:42:12] Raza Habib: case that like question answering over documents or something like that. Yeah. Yeah, I'm
[00:42:16] swyx: trying to get some insight from there.
[00:42:17] I don't know.
[00:42:18] Raza Habib: Yeah. So I can tell you the trajectory we've seen, right? So really early on. The like killer use case was some form of writing assistant, whether it was like a marketing writing assistant. The Jaspers. Right. Jasper, Copy AI. We had like seven of them at one time, right? And then you had like specialist writing assistants.
[00:42:34] Some, some I think have gone on to be really successful products like Sudowrite or Type AI is another one, but they're still fundamentally like helping people write better. And then I think increasingly we've seen more diversification. There was a wave of chat to documents in one form or another. Yeah, chat PDF, still doing well.
[00:42:50] Yeah, chat PDF doing super well. Once RAG started working, like retrieval augmented generation, there was that. But since then, as people are more problem driven. And they're like trying to say, okay, how can we use this? We see a much broader range. So even within like, take Duolingo as an example, they've got Duolingo Max.
[00:43:07] So that's like a conversational experience, but they're also using large language models within the evaluation of that. They're all choosing it for content creation. And each of these companies sort of, you start with one use case and I feel like it expands because you just discover more and more things you can do the model with, do with the models.
[00:43:21] swyx: Yeah, yeah. Do you see much code generation?
[00:43:24] Raza Habib: Yes. So I would say that like developer focused tools, I would say like edtech and, and developer focused tools are like probably two of the biggest areas that we see people working on.
[00:43:36] swyx: I'm always wondering, because code generation is so structured that you might have some special affordances for that.
[00:43:42] But again, that's anti the bitter lesson. I always wonder what we can optimize for, but that's my optimization brain when I should not. I should just scale things up.
[00:43:53] Raza Habib: I think there's, I think there's merit in both. Yes.
[00:43:56] HumanLoop's new Free Tier and Pricing
[00:43:56] swyx: Okay. So today, by the time we release this. You will have announced your new pricing.
[00:44:00] Raza Habib: Yeah, that's right. So one thing that people have said to us a lot actually is that the barrier of entry to getting started with HumanLoop is just quite high. There isn't, you know, you can't just install an open source package and just get going or whatever it might be.
[00:44:12] And and there have been quite a few small companies that have signed up and then sent us messages, you know, we're a not for profit or an early stage company, we really want to use HumanLoop, but it's just prohibitively expensive for now, we wouldn't mind paying in the future. And so we've thought really hard about how can we make it like lower the barriers to entry for people to try it out and get started and get value and have the amount they have to pay scale much more with the value they get so that they're only paying for things when they've got value from human loop.
[00:44:37] And so we will be launching a new set of pricing. There'll be a free tier so you can sign up, you can get going on the website, you can start building projects and you won't have to pay anything. And only once you get to a certain scale, you've got more than three people on the platform, you're logging a certain amount of data to us.
[00:44:51] Then pricing kicks in and it scales with you. So you know, as your volumes go up, that's the time when you'll start paying us more. So much more gradual than it is now.
[00:44:59] swyx: And you're tying some features to the tiers?
[00:45:02] Raza Habib: A little bit, but mostly we're trying to give you just a sort of... Most of the product experience on the free tier, I think there's one or two things you don't have, but you have almost everything.
[00:45:12] And then once you're off the free tier, you have everything, but you pay the amount you pay kind of scale slightly differently. You get volume discounts at scale. Awesome.
[00:45:20] Addressing Graduation Risk
[00:45:20] swyx: And so this is where one of the hard questions is, right? Like, is there a graduation risk as people get very serious about logging?
[00:45:26] You brought up Datadog earlier and for sure Datadog is looking at your market as much as you're looking at theirs. So how do you, how do you think about that of, like, ultimately... At scale becomes a commodity, right, the logging.
[00:45:40] Raza Habib: So I think that the that actually this is really different to that. So the more people use it, we find actually the stickier it becomes.
[00:45:46] It's almost the opposite, that as they get to scale. So, so you're right that the millionth feedback data point is worth a lot less than the thousandth feedback data point. But what continues to be really valuable is this infrastructure around the workflow. We see a process of prompt management, engineering, fixing things.
[00:46:01] So we see, you know, you have what happens over time is people put more and more evaluations onto Humanloop. They've got more people on their team, the product manager and also three linguists and someone else who are opening up, the data that's being logged through Humanloop back into that interactive environment they're rerunning things or plugging in other data sources.
[00:46:19] And so over time, actually the raw logs, I agree with you kind of come commoditized. But the tooling that's needed to be able to. So, of collect the data, but make it useful and do something with it to improve your model, that's the bit that becomes more valuable, right? Once you have something working at scale, then improving it by a few percentage points is like very, very impactful.
[00:46:40] So a lot of our customers early on. And Like, Oh, we can just dump our logs to like an S3 bucket or we can plug it, you know, and then like, why do we need a special purpose tool? And most of them come back to us later, because what they find is, oh, okay, I've logged something, but it's really difficult for me to like match up the log to like what model generated it and then quickly run that and try something else.
[00:47:01] Or I've like logged something and that log involves a retrieval. And I would like to know like what went wrong with the retrieval or where, which document the retrieval came from and I didn't log that information correctly, et cetera, et cetera. And like the complexity of like setting this up well is quite high.
[00:47:16] So you can either spend a lot of time at that point, at that stage, two things happen. Either people roll their own solution and early on we saw a lot of people build their own solutions. Or they come and use something like us. And I think increasingly, because we've been working on this for now more than a year the difference between something you would build yourself and, and sort of a bot solution is now quite enormous.
[00:47:36] Yeah. And so I just wouldn't recommend it. And the, I guess the difference on the Datadog point, or like other analytics tools, you mentioned Amplitude or Datadog, they're much more about passive monitoring. And I think one of the amazing things about AI is the interventions you can take can be very quick and very powerful.
[00:47:51] And so coupling very closely the ability to update a retrieval system or change a prompt to the analytics data and allowing you to run those experiments, I think is very powerful.
[00:48:00] swyx: Fantastic answer. It's almost like we we prepped for this.
[00:48:03] Raza Habib: It's also almost like I think about this a lot.
[00:48:05] If I didn't have an answer to that question, it would be difficult to justify spending all my time building this, but I, I do think it's very important.
[00:48:11] Company Building & Learnings as a Founder
[00:48:11] swyx: Company building, what have you changed your mind on as a
[00:48:13] Raza Habib: founder? Ah, that's a great question. So one thing that comes to my mind as soon as you say company building is like a piece of advice that Michael Siebel has at YC, right?
[00:48:21] Which is like, don't do it, or at least don't do it pre PMF, right? Like one of the biggest failure modes of early stage startups is, especially if they've raised investment from, from, you know, large investors, is that they persuading themselves that they have PMF too early and they go into a sort of scaling mode and hiring people and a lot of that stuff is important, distracts from the most important thing that you have to do, which is, understand the needs that are most pressing for your customer or figure out who the right customer is and build what they really want or if they don't necessarily know what they want build what they really need So one thing that I believed, and I still believe, is that you want to do that at the right time.
[00:48:59] That company building too early is a distraction. And
[00:49:02] swyx: when was that for
[00:49:03] Raza Habib: you? So for us, it was actually November, December last year. So November, December 2020. So we were a four person company for almost two years. And it was only when everything was breaking, when all the charts were up and to the right, and we really could not service our customers anymore because the team was too small.
[00:49:20] That's when we started like actively hiring people. And even then we've been really slow and deliberate about it. Maybe a little bit too slow, given how much there was a lot of suffering in being that slow. I wish we had a couple more people when things took off. There was a period of time, I'd say from like November to March, where all of us were like barely functioning because there was just so much to do.
[00:49:42] But we've, we've continued to have the bar set really, really high, and hire slowly, and very deliberately. And I think we get more done with a smaller team of really, really excellent people than we would had we hired more people sooner. So that's something I kind of agreed on.
[00:49:58] On Opinionatedness
[00:49:58] Raza Habib: The other thing that has maybe changed a little bit in my mind is related to how opinionated you should be.
[00:50:04] So I think you asked this question about opinionation in the product, and I think there's a. Risk of just listening to your customers and building what they want. Yeah. That can lead to hill climbing. And I think especially and we did, we were guilty of this, I think a little bit early on in the first year of HumanLoop.
[00:50:21] Oh, you did it? Well. Better than most . Thank you. But I think that, you know, where things started working for us was when we were. We had a lot more strength in our convictions, right? When we said, actually, you know, we believe GPT 3 is going to be the future of how people build this. And even if people don't believe that today, we're going to build for that future.
[00:50:37] That is hard to do. I still think we don't do it enough. Like, I want us to do it even more. We have things we believe about the future that are somewhat contrarian. And being able to plan for that and be opinionated and build for that future. And also to be building the things that we believe our customers need, not exactly what they ask for.
[00:50:55] Because otherwise you end up I think, with a lot of very undifferentiated products that they're for everybody, so they're not for anyone. And they, they don't have a strong point of view. So I think especially for building dev tools, I think you should have a point of view. Yes,
[00:51:08] swyx: I strongly agree with that.
[00:51:09] HumanLoop Hiring
[00:51:09] swyx: Hiring. What are you hiring for and given that you're now hybrid, you're spending some time in SF, where are you hiring?
[00:51:17] Raza Habib: Yeah, so we're hiring in both SF and London. The role that is most urgent for me right now personally is hiring for a developer relations engineer. So this is an engineer who loves community.
[00:51:28] Loves documentation, loves giving talks, building demos you know, as part of launching this new pricing where we're going to have a free tier, is also having a much bigger push towards helping individual developers and smaller teams succeed with human loop as well. And, and even developers in larger companies who just want to get, you know, try it out before they're at scale.
[00:51:47] And I think to do that well requires a really good Onboarding experience, really amazing documentation and really good community building, and we need someone fully focused on that. I don't think it can be someone's part-time job. We want someone a hundred percent focused on building community. You know, ideally we'd find someone as good as Uix who to do this job.
[00:52:05] So, yeah, so if you're a developer relations engineer, or even if you're just a product focused engineer, Who is excited about AI and ML and, you know, has some track record of community building, then that's the role that I would love to hear about. And we'll be hiring for it primarily in San Francisco.
[00:52:20] Although if you are amazing elsewhere, we'll consider it, but SF being the focus.
[00:52:25] swyx: Thanks for the compliment as well. But yes, I'd highly recommend people check out. The job it's already live on the website. A lot of people don't know, I have a third blog that is specifically for DevRel advising, because I do do some angel investing and people ask me for advice all the time, and I actually cache my frequently asked questions there.
[00:52:42] How HumanLoop thinks about PMF
[00:52:42] swyx: Anything else on the company side that I didn't touch on?
[00:52:45] Raza Habib: If you're within YC, this will be boring, but if you're outside of YC, I think that you probably can't hear this enough times, because I've seen so many people get this wrong. Which is just like... Before PMF, nothing other than PMF matters. And there's just there's so many possible distractions as a startup founder, or things you could be doing that sort of feel productive, but don't actually get you closer to your goal.
[00:53:06] So, like, trying to narrow focus to finding PMF and what that means will be a little bit different for different startups and, you know, different experiences. I have friends who are doing deep tech, biotech startups or whatever, right? And so, I don't think there's a one size fits all, but, but try not to do anything else.
[00:53:21] That, that advice has been really good for us. And I, and it's often not count, it's often not intuitive. Yeah.
[00:53:28] swyx: Does. Human loop have PMF right now?
[00:53:31] Raza Habib: I think we have PMF within niches. So I think we definitely have, like especially for, I would say, like, if you're a team building an LM application within a larger company, then, like, yes, we see people sign up.
[00:53:42] They use the product. More people use it over time. Usage goes up. They give us great feedback. There's always room for improvement. But we have a form of PMF, and I think there will be like multiple stages of it. But we certainly found some PMF, yeah. What is the next
[00:53:58] swyx: tier of PMF that you're looking for?
[00:54:00] Raza Habib: Well I'm hoping it's on this evals project that we're launching, right? So we definitely have PMF on the current sort of prompt versioning management stuff. We've got about 10 companies currently in closed beta on evals, giving us a lot of feedback on it. It's a real problem for them. We've seen them get value from it, but we haven't launched it publicly yet, and I'm hoping that will be the next big one.
[00:54:18] Yeah.
[00:54:19] swyx: Just a technical question on the evals which I don't know if it's too small, but Typically evals involve writing code. Yeah. So it's like Freeform, Python, JavaScript, something like that, for you guys?
[00:54:29] Raza Habib: Yeah, so it's the combination of and again, we're iterating on this, but yeah, yeah, you can define them in Python, And they can also call language models as well.
[00:54:36] swyx: And it's executed on your servers?
[00:54:38] Raza Habib: Both are options. Okay. Interesting. So we have a protected environment. You can basically execute everything on our servers. Well done. Which was not easy to build and I'm not the right person to talk about it. But I think there's a really interesting engineering blog and how you can make it safe for other people to exec code on your servers.
[00:54:55] But also it's going to be set up such that you can also run things in yours and just have the output logs still go to human loop and useful. This is the
[00:55:02] swyx: promise of the edge clouds of the world the Deno's, the Cloudflare workers, the Modals. I don't know if you've explored any of those, but then you would not have to set it
[00:55:10] Raza Habib: up yourself, essentially.
[00:55:11] I'm pretty sure they've all been explored by my team in recent months. Yeah, yeah.
[00:55:16] swyx: Oh, excellent.
[00:55:16] Market: LMOps/PromptOps vs MLOps
[00:55:16] swyx: Okay bringing it out to market takes. Yeah. Just the, you know, bringing up for human loop as a whole. How do you feel about LLM ops or prompt ops as a
[00:55:23] Raza Habib: category term? LLM ops. I would drop one L firstly.
[00:55:27] I think we call them large language models today, but the goalpost of large is going to keep moving. So I think the point is sort of foundation models or... Oh, I have a proposal to deal
[00:55:35] swyx: with that. Oh, yeah. I have T shirt sizing. So I've defined S, XS, and then M, and L, and all the way to XXL. And you're going to
[00:55:42] Raza Habib: have to keep updating that over time.
[00:55:44] But I think foundation model ops is maybe a better term, because I also think that, like, within six months we're going to have images, and then, you know, People won't call them just language models anymore. Yeah
[00:55:53] swyx: and is it worth a separate category than MLOps?
[00:55:55] Raza Habib: But I do think it's worth a separate category.
[00:55:57] Okay. I think that the people from it's for are different. We discussed this a little bit earlier, right? But a machine learning engineer and a traditional software engineer are very different people. They have different levels of knowledge and different goals. I also think that the generality of the models has changed what people are building.
[00:56:13] And so the problems they face are really different. It's you know, like what you need for building a recommender, a small recommender system at enormous scale is very different from what you need to build a generative AI application that's very subjective. Yeah. And so I do think that they have, I actually think like we've seen a lot of MLOps companies recently try to pivot into solving problems in this space.
[00:56:33] And I think it's going to be hard for them because they're changing who they're building for. So they, they now have to straddle two different sort of ideal customer profiles. And they also have a lot of legacy infrastructure focused around models whose output was like a measurable, quantifiable number.
[00:56:47] It was F1 or it was accuracy or something like this. And I think their lives are going to keep getting harder as the models go more general and go multimodal. Yeah. Because what they've built so far just won't fit that world. Yeah. So I think, I think it probably can be done, but I think it's going to be very hard.
[00:57:01] Impact of Multimodal Models
[00:57:01] swyx: You mentioned GPT 4 vision, you, and obviously there's more multimodal models coming along the way. How big does that factor into your planning? Because you're very language oriented right now. So
[00:57:10] Raza Habib: it's, it's increasingly like a, an internal conversation. Every time we have a product roadmap discussion, like, Planning forward, starting to iterate on and when to build in support for Vision has become very much front of mind.
[00:57:21] So I think, like, now. Like, we're working on it. Okay.
[00:57:25] swyx: One version of this, I posed this exact same question to Harrison, which is, let's say the GPT 4 Vision API drops tomorrow. Yeah. What changes in human
[00:57:32] Raza Habib: loop? Well, for one thing that you need just to be able, I mean, like, very simple things, right? Like, we need to be able to render and read in images in the playground environment that's interactive, right?
[00:57:41] So there's a bunch of just, kind of, follow your nose things that I think we'd have to figure out. But, as I said, we've just started working on this. It's sort of become a product roadmap item. We, but not, like, we have to support it. Like, it's very clear. This is not a question of if, it's a question of when.
[00:57:56] swyx: Okay. Yeah. Yeah. Excellent.
[00:57:58] Prompt Engineering vs AI Engineering
[00:57:58] swyx: Is prompt engineering dead?
[00:58:01] Raza Habib: So we talked about this a little bit on the walk here, and I've never been a huge fan of the phrase prompt engineering. Because I think it simultaneously makes it not important enough and too important at the same time.
[00:58:13] I don't think it's a form of engineering in the way that software is a form of engineering where it has this rich body of literature and theory and you have to learn about it and takes like very specialist skill. I think you can get good at it very quickly. But I do think that prompts are a very important part of LLM or AI applications, right?
[00:58:29] Like, natural language written instructions have become part of your source code. And they have impacts on your product quality, they have impacts on the way your product behaves, so you should be treated with that level of seriousness as you would any other code artifact. Yeah. So in that sense, I don't think it's dead.
[00:58:42] I think it's alive and well and becoming increasingly important. It's interesting, there's like, you know, Anthropic had that very well paid job, prompt engineer. Yeah. And I think they've hired a few prompt engineers now as well. And those people are leading on deployments in Anthropic and adding a lot of value.
[00:58:57] So there's, there's clearly, it's clearly happening. But I think maybe it's slightly misnamed. I actually prefer your kind of AI engineer framing where this is a different engineering skill set. You still need to be able to build product. You're still an engineer. But you have an intuition for how to get the best out of models, how to evaluate them.
[00:59:13] You understand the problems that come from stochasticity and you also understand just the nuances. Like if you have a good mental model for how a large language model works, I think prompt engineering becomes a lot easier. And so having that skill set I think is going to be important. But I doubt that five years from now there will be like a separate job title of prompt engineer.
[00:59:33] swyx: Yeah, I try to contrast it basically as prompt engineering is still 2022 and AI engineering is 2023. But yeah, the central thesis is you can't just get by with prompts. You have to write code to manage prompts, to generate prompts, and to generate code and for you to evaluate and run that code.
[00:59:52] Raza Habib: Yeah, I think I'd agree with all of that. But to me that doesn't diminish the importance of the prompt as an artifact in the system. Yes,
[00:59:58] swyx: still important.
[00:59:59] Raza Habib: I feel like when I saw chainlethbot for the first time, I went from a world in which I was like, okay, models are not good at reasoning to models can do some reasoning.
[01:00:06] It was a sort of step change in my beliefs about the capabilities of these models.
[01:00:11] LLM Cascades and Probabilistic AI Languages
[01:00:11] Raza Habib: And I still think that the LLM Cascades paper hasn't had the impact that it should have. Can you summarize that? So this was a paper from Google and it's just sort of getting you to view LLMs as a way of doing inference in a probabilistic programming framework.
[01:00:26] So that's a lot of words. So let me, try and sort of you have a PhD in this. But, but, you know, before, before AI was all LLMs. There was, and there still is, like a huge branch of research around probabilistic programs. So this is just ways of like writing code where probability and random variables are first class citizen.
[01:00:45] So you can have like random variables, and then there's lots of different operations you can do to condition and make predictions about them and do inferences around them. And this language modeling cascades paper basically said, Hey, actually, like large language models are a really powerful inference engine that could be used as a composable piece inside something that looks like a probabilistic programming language.
[01:01:07] And we were chatting earlier today. About the framework that will emerge for, for large language models. And I know you're working on small and you've given this a lot of thought. And you know, LangChain and LlamaIndex and all these different groups, AutoGPT, are trying to circle around, like, what's the right set of abstractions?
[01:01:22] How might we be able to compose LLMs in ways to write more complex programs? And I think that LLM Cascades paper was one of the first attempts to think about that in first principles. And say, okay, what are the primitives you might want? And I think I'm surprised it hasn't been built on more.
[01:01:37] swyx: The very, very first AI grant from Nat Friedman mentioned that they were looking for a UI for Cascades.
[01:01:44] Raza Habib: And no one took them up on it. I don't think it I think it needs a... I think it's a... It's a framework. It's a framework. I think you want it in code. Yeah, yeah. And I would love to work on it if I had all the time in the world. It's sort of, you always have to choose your, you know, you can't do everything at once.
[01:01:57] Well,
[01:01:57] swyx: If someone is working on it, maybe reach out and... I would love to chat to people
[01:02:00] Raza Habib: about it who are working
[01:02:01] swyx: on it. Yeah.
[01:02:02] Prompt Injection and Prompt Security
[01:02:02] swyx: How many of your customers and users are actually worried about prompt injection and prompt security?
[01:02:07] Raza Habib: Not enough. Really? So I would say almost zero. Yeah. And I think that's correct today because very few of our customers have action taking LLMs.
[01:02:15] Yeah. And I think as long as your models are like read only. Prompt injection isn't that big a deal. Like it's not to me about like leaking your prompts or something because the prompts are only really valuable in the context of your code anyway. But I do think that once you get to the stage where you're letting the models have read write access to any source of data, then prompt injection becomes a problem the same way any other form of code injection is a problem.
[01:02:37] But honestly no one ever asks us about it. Right. Like almost never. Yeah. And I think that's because of the stage where people are at, right? Which is that they're still trying to overcome hallucinations and they're still trying to put guardrails in place around the behavior of the models. And very few people are using agents in production at meaningfully sized companies.
[01:02:53] Yeah. But I think. As soon as that becomes the case, if we do get to a stage where more people are allowing the models to read from a data source and write to a data source, then prompt injection will become something they care about. Yeah, and you guys will
[01:03:05] swyx: be well positioned to offer something.
[01:03:07] Raza Habib: Absolutely. I think sort of being this, you know, layer between the raw model and the end application actually buys us a lot in terms of what we can
[01:03:15] swyx: help with. Yeah. Well, you know, they're a bunch of... Security minded people who are trying to offer that as a standalone thing, and it's a feature, not a product.
[01:03:23] I think I'd agree with that.
[01:03:24] Finetuning vs HumanLoop
[01:03:24] swyx: OpenAI's fine tuning rollout, which was last month, how does that affect HumanLoop?
[01:03:30] Raza Habib: Yeah, so when we started the first version of HumanLoop GPT, 5 wasn't out yet. It was all GPT 3, and we saw a lot of fine tuning at the time. And post the release of... 3. 5 and 4, by virtue of the fact that it was impossible to fine tune, like we could just see it in our analytics.
[01:03:46] The amount of fine tuning just kind of fell off a cliff partly I think because the models were better. Yeah. But also just partly like it wasn't an option. Yeah. And so I'm kind of interested to see now that 3. fine tuning are back, whether that kind of fully recovers. 4 isn't back yet, but it's, but 3.
[01:04:02] 5 fine tuning being back we've, we've definitely seen a lot. In the past, people generating outputs with GPT 4, filtering based off evaluation or feedback criteria, and then fine tuning smaller, faster models. And so I think we likely see a lot of fine tuning of GPT 3. 5 on 4 generated data, and that's a workflow that we've been, we natively support within HumanLoop now.
[01:04:25] So you can actually kind of do all of those things without having to leave it. If you have a bunch of generations, you can filter them on some criteria. Click fine tune, run it ahead of evals, and then decide whether or not to deploy that model. But time will tell as to whether or not this is something that goes back up in importance the way it used to be.
[01:04:42] Yeah.
[01:04:43] Open Standards in LLM Tooling
[01:04:43] swyx: A follow up question that occurs to me always, we talk about you being that layer that that positions you very well. A lot of people are fighting to be that layer. And it occurs to me that as a user, potentially of human loop and your competitors, that I may not want to have to choose or be locked in.
[01:05:02] Is there room for an open standard that everyone agrees to? That we all say like, okay, just adopt this one vendor neutral thing, and then we all consume from it.
[01:05:13] Raza Habib: Maybe. I think I think it could happen. We're not there yet. I think things are moving too fast for that to be the case for people to have clarity on that.
[01:05:25] So maybe maybe in the fullness of time, there will be my suspicion is that both will happen, right, that there will be some open standard that some people like to use. But Once you come to working on serious production use cases, you often actually want the peace of mind of knowing that you're paying a real company that's going to be around to support you, that is focused on this you.
[01:05:47] That has the knowledge and expertise. And so, as we've seen in many other spaces, I suspect that there'll be a bit of both. A bit of both.
[01:05:53] swyx: Yeah, so the model I have in mind is Datadog versus the OpenTelemetry
[01:05:58] Raza Habib: crew. And Datadog's doing fine, and the OpenTelemetry crew's doing great as well.
[01:06:03] swyx: So, last question on the market.
[01:06:05] Did GPT4 Get Dumber?
[01:06:05] swyx: Did GPT 4 get dumber this year?
[01:06:07] Raza Habib: I don't think so. We've seen a lot of, like, conversation about this having happened. I think GPT 4 changed. I think that they are regularly updating it. And you certainly see that both in sort of people's attempts to, you know, papers being written about this, and people are trying to do evaluations over time.
[01:06:23] I think that the, the main takeaway shouldn't be like, did GPT 4 get dumber, right? But the interesting question is like, did GPT 4 change? To which the answer I think is definitely yes. There's no question about that. And it's, it's something that if you're a developer building products on top of GPT 4, it's something that you should think about a lot.
[01:06:40] Because you're building on a platform that will evolve and change over time. And you can pin the base model, but not forever. And so I think you need to, at the very least, have really good... testing frameworks to be able to run regression tests and know, like, have things gotten worse over time, right? If you can't answer that for yourself, you're going to be scratching your head, like, did we make the prompts worse?
[01:06:59] Did the retrieval system get worse? Did something else change? Did the user inputs distribution change? Or did the model get worse? And being able to disentangle those things easily, I think the importance of that's going to go up. But I also think that it should, like, give us pause for thought about kind of the balance between What gets built on top of third party providers and APIs in a closed world and what we might want to do, you know, more open source, and I suspect there'll be a mixture of both depending on the use case.
[01:07:23] But you are, you are building on shifting sand whenever you're building on someone else's platform. Yeah,
[01:07:28] swyx: totally.
[01:07:29] Europe's AI Scene
[01:07:29] swyx: And then one local specific question before we go to the, the takeaway questions. You went through IC. Yeah, and you are very very familiar with the American tech scene, but also you built your company here in London What should and I'm very US focused most of our audience is very US centric.
[01:07:46] What should People know about the European tech scene.
[01:07:50] Raza Habib: Yes, I think that London's one of the best places in the world, and Paris, for AI focused folks. With the Hugging Face, I don't know Hugging Face in Paris, where we're sitting right now. We're probably less than 200 meters from the offices of DeepMind.
[01:08:03] Facebook AI Research is here as well. UCL's AI center is here, which is where, you know, Geoff Hinton was and where a lot of great research is, where DeepMind spun out of, actually. So Shane Legg and Demis met at UCL. So there's an amazing, and there's many more, you know, I can't list everything that's, that's great.
[01:08:18] But there's many great AI institutions. What I would say is that I think that Europe is being amazing on research and continues to be like a fantastic place for researchers, but has been less good in my experience on productizing and trying to productize AI. And so the difference that I feel being here versus being in the U S I think a good example of this is just the number of, like, if I go to San Francisco, the density of people who are trying to build useful things with large language models or with AI and butting their head up against it and discovering what works and what doesn't work and trying great ideas or trying stupid ideas and just learning together, is much richer than what we have here.
[01:08:59] I think the pure like research labs. Very competitive, you know, Anthropics just opened an office here, OpenAI is opening an office here. When you're hiring for talent, you'll find as many or better people, you know, like equal quality people in both places. But less so once you move towards productization.
[01:09:16] And I suspect it's also to do with the investor ecosystem. So we're sitting in the offices of LocalGlobe. LocalGlobe and Index were our first investors, and they're both great. But the number of investors that you have of that quality in Europe is not the same as the U. S., and the type of people you interact with are very different.
[01:09:31] Just move to SF (in The Arena)
[01:09:31] Raza Habib: When I speak to VCs in the U. S., there's way more former founders, there's way more people who have done DevTools before. And there's way more support from the founders towards the ecosystem than there is in Europe. People are trying, but the culture is not quite the same. And, and that's why we're moving to SF, right?
[01:09:47] We want to be, every time I've been to SF, good things have happened to humans. Whether it's like bumping into you, or we get an introduction to an interesting investor or a customer, you know, or we just speak to someone who's been trying really hard to build something. And, you know, we share an office here in London with Bloop that does, you know, Bloop ai does code search with LLMs and we've tried our, you know, our very best to kind of aggregate a few other companies to us and we're doing AI tinkerers, you know, tomorrow. So there is some of it here, but you have to work so much harder. Resources, SIS, you can't move for hitting some AI. We had
[01:10:21] swyx: a Thursday recently with 10 AI meetups in one night.
[01:10:24] Yeah. It's almost too much. It is too much! I'll go there and say it, it is too much. You need some
[01:10:30] Raza Habib: time to build things too.
[01:10:31] swyx: And there is I would say actually in the ESF builder scene privilege that comes out of just having so much opportunity thrown at you and like that we like have this like, you know, arm's length, this taste for VC and I'm like, no, like they are partners in building your business.
[01:10:45] You know? Absolutely. Yeah. So, so I think it's, I think it's interesting contrast, but you know, as a person who I'm not American, I lived most of my adult life in America, but I, I feel for non U. S. Policymakers and VCs and people who care about their city who are like, okay, like we're not SF.
[01:11:03] What do we do?
[01:11:04] Raza Habib: I honestly think that it's you know, we think a lot about network effects and defensibility in startups I think it's like the mother of all network effects, right? The reason I'm going is not because I love the city, I mean SF's fine as a city. I like it, but I'm going because Everyone else is going and everyone else is going because we're going right and it's once you've attracted a certain talent density I think it's really hard to compete with that
[01:11:26] swyx: Okay It is true.
[01:11:28] This is the honest truth. Yeah, I do want to work out a path for non tech hub cities because that I mean That's that's where I'm from right?
[01:11:35] Raza Habib: Yeah, and me too as well. All right but I also I also think there's something to be said for The most driven, most ambitious people like finding a way to get to where the center for their thing is.
[01:11:46] And like right now today for like AI focused products, I think it's San Francisco. But for different things, the center is, you know, different places. If you're a, you know, Hollywood is the place to go if you're an actor or whatever. And there are different hubs for different areas. It's a, it's a Paul Graham
[01:11:58] swyx: thing.
[01:11:59] You know, different cities breathe different ambitions into you. And in San Francisco, apparently it's power. It's not actually tech, it's power. Okay, interesting. And tech is a means to power.
[01:12:09] Raza Habib: Interesting. There's a lesson in that for those of us who think about AGI safety. And
[01:12:16] swyx: also, you know, not anywhere in San Francisco, specific two square miles in San Francisco called the arena.
[01:12:21] You have to get in the arena and build. Okay.
[01:12:23] Lightning Round - Acceleration
[01:12:23] swyx: So so that broader takeaway questions. So we always ask three of all our guests acceleration, what has already happened in AI that you would, you thought would take much
[01:12:31] Raza Habib: longer? So this has been, since I started my PhD, like Every year, things have happened that I thought would take much longer.
[01:12:37] So when I started my PhD, it was at a time when like, deep learning had just sort of started working, and transfer learning, even for like, vision hadn't been figured out yet. And people were talking about like, oh, it's going to, you know, how long before we can train models that don't need millions of annotated data examples?
[01:12:51] How long, you know, so AlphaGo was happening just at that point in time, the first version. I've made predictions and been wrong again and again and again. I've just been consistently too pessimistic. And I think I'm quite an optimistic person. You know, when would... You know, like, Dota surprised me when it happened.
[01:13:05] The first, like, vision trans first transfer learning working in vision surprised me when it happened. The continued success of scale and deep learning and then finally, like, you know, although I believed that LLMs were going to be enormous and I thought GPT 3 was going to be the future, like, just how good ChatGPT turned out to be did surprise me.
[01:13:23] The first time I actually saw Claude before I saw chat GPT. But the first time I saw Claude, and I like kept pushing the limits of it with tasks that I knew were kind of at the frontier of what was currently possible and just saw it like blasting through these one after another. That was a mind blowing moment for me.
[01:13:40] And I think it was for a lot of the rest of us. I think we're going to have a lot more of those. I think that's going to keep happening.
[01:13:45] swyx: Yeah, we are accelerating as we speak.
[01:13:48] Continual Learning
[01:13:48] swyx: Exploration. What do you think is the most interesting unsolved question in
[01:13:51] Raza Habib: AI? I think there's actually some like Obvious kind of elephant in the room, unsolved problems that for some reason don't seem to get the amount of airtime that they kind of obviously should.
[01:14:00] So continual learning to me is one of these, oh God. Yeah. Like we all walk around as if it's just completely normal that these models never learn anything new .
[01:14:07] swyx: Yeah. 2021 is when
[01:14:08] Raza Habib: history ended. You just think, yeah. 2021 is when history ended and you, you know, you do retrieval augmentation with a vector database and like you're done.
[01:14:14] Right? Like why would the system keep learning after training ? And, and, and I think everyone knows that this is a problem, but somehow it doesn't seem to me to get the amount of like, like, like the, I think this field in research is called continual learning or life, like life, lifelong learning. And it doesn't seem to get the airtime that it used to.
[01:14:31] It seems to be like an obviously enormous problem. Yeah. The other one. That I think will happen naturally, but just hasn't happened yet, is is just like more multimodality, right? Like it's kind of obvious that these models should be plugged in to vision, audio, speech, etc. And have shared representations because there's so much to be gained from that.
[01:14:49] And I think it's just like gonna happen with time, but hasn't happened yet.
[01:14:53] swyx: Yeah. Well, I think that the cost is just token space, I guess. I don't know how much more you need to add every single modality.
[01:15:02] DeepMind Gato Explanation
[01:15:02] Raza Habib: Although I think Facebook released like six modalities. We have some examples of this, right? So like Gato from DeepMind was a transformer model that they trained across.
[01:15:10] They just did policy distillation. So they trained a whole bunch of different RL agents. And they took the outputs of that, which is like observation, action, reward, triples, and trained a single transformer model on all of that. And then that one model could do any of those tasks. Actually, okay. We're also in exploration mode.
[01:15:24] There's a paper from DeepMind, very same time, came out at the same time as Gato, that I think is massively underrated. And I don't understand why it didn't get more attention, which it was, it was at the same NeurIPS conference and I forget the exact title, but I think it's called like in context reinforcement learning or something like that.
[01:15:40] And they do something really similar to Gato. They take an RL agent, they train it. And then they distill that into a transformer model. But what they do that's different is they don't take the trained RL agent. Instead, they take an untrained RL agent, and they record the full trajectory of its learning.
[01:15:57] So early on in the data, the model's kind of crappy, and by the end of the data, the model's been good at this task. And then they train a transformer model to predict that. And in order to be good at predicting that sequence, you have to predict that the sub agent, like the RL agent that generated the data, gets better at the task over time.
[01:16:16] And the only way that I can see to do that and in fact this seems to be what the model is doing, is that you have to simulate a learning algorithm. You have, the transformer has to simulate in context reinforcement learning. And so they take all of these tasks, they train on the learning trajectories, and then they take a completely new task that that transformer model has never seen before.
[01:16:34] And it learns to do that task. And so it's learning from reward signals in context to achieve a new task. And to me, that's huge. It's a, it's a demonstration of like inner optimization within a transformer model. And it's also a demonstration of like in context continuous learning that's limited only by the length of the context window.
[01:16:52] If the context window was really long, you could make this work practically. I don't really know why that wasn't a bigger deal.
[01:16:59] swyx: I don't know either. This sounds fantastic.
[01:17:01] Raza Habib: Yeah, and, and Gato, I think the reason maybe it wasn't a bigger deal is it came out exactly the same time as Gato, and I think Gato just took all the, took all the attention.
[01:17:08] swyx: So we just got done talking a lot about focus, but if, given that you see potential in this, and this would be huge for literally training anything, Yeah. Would you be interested in exploring it at some point?
[01:17:19] Raza Habib: As in trying to train it myself?
[01:17:21] swyx: Put this in production. Some, some form of continuous learning.
[01:17:24] Obviously that's on your radar. Yeah,
[01:17:27] Raza Habib: I would love to, but I think you have to decide what kind of company you want to be. Yeah. And this is, this is something for like OpenAI or Anthropic to focus on. I feel like you have to be thinking about the fundamentals of like, this is the kind of research I used to do as a PhD student.
[01:17:40] Motivations from Academia to Startup
[01:17:40] swyx: So I'll put it this way, right? Like you have the research background to do this. And you're choosing not to. And you're building a company that doesn't use your research. Specifically that part. I
[01:17:53] Raza Habib: mean, you know. Reasonable, reasonable question. But I think that... I'm excited about getting things useful into people's hands very quickly.
[01:18:03] Like I like seeing, we talked about this earlier, right? We've moved from the research phase to the engineering phase of AI. It's the first time after having been in this field for maybe seven years, where stuff goes beyond like just kind of a graph, right? Like, like the output of my work before would always be like, Oh, look, there's a graph and like the number is better now, versus we actually get to see, you know, we have a customer.
[01:18:26] Between Duolingo and two or three of our other customers, we've got three or four customers working on, like, better versions of, like, teaching students, right, tutors or language learning or whatever it might be. And to be able to make that incrementally better and accelerate the time it takes to get there, it just feels to be so much closer to it, to be on the engineering space right now.
[01:18:44] Whereas I think there's an alternative universe in which I stayed in research and I went to an open AI or, you know, almost everyone from my research, PhD research group apart from Peter, now works at DeepMind. And I think I would have enjoyed that as well. But I really wanted to start a company that built something, like, useful and in production.
[01:19:02] And I don't even think those companies do that much right now, right? Like, it's only recently that OpenAI has sort of become a product company. They're more of a research company. They're building AGI. And I think that's true of the others. And I think that's amazing and fascinating. And if I had multiple lives, I would love to do that too.
[01:19:17] But at least right now, I want to be building products and putting them in people's hands. And it just feels a little bit far removed. Yeah.
[01:19:22] swyx: Yeah, makes sense. You know, I think the world's better because you're actually coming at it with a full knowledge of what came before. Yeah,
[01:19:30] Raza Habib: I do think it's a huge advantage.
[01:19:32] I do think like having a good conceptual understanding, like, like, there's been a lot of people have pivoted into, as you said, LLM ops earlier. And I do think that actually knowing how it works, having a sense of what's going to come next and being able to project forwards and build for it is difficult to do if you don't have a good conceptual understanding of the machine learning.
[01:19:50] Yeah, yeah, yeah,
[01:19:51] swyx: agreed.
[01:19:52] Lightning Round - The Takeaway
[01:19:52] swyx: Okay, well I, I feel like this, this is a leading question, but what's one message you want everyone to take away
[01:19:56] Raza Habib: today? Oh wow, that's a great question. Really, if you're building, you know, if you're building a serious LLM application and you're trying to do, find the right prompts, optimize them, evaluate your models.
[01:20:07] Then I really would encourage you to try out HumanLoop. Like, that's the use case that we really solve well for. Especially if you're kind of having to collaborate with non technical people. Then HumanLoop will probably solve a lot of pain for you. Yeah,
[01:20:18] swyx: excellent. Well, thanks so much for doing this. I had a real joy getting to know you and debugging real life issues with you.
[01:20:24] But that's the fun of latent space, so thank you so much.
[01:20:27] Raza Habib: No, thanks for having me. It's been an absolute pleasure to get to spend some time with you, Shawn.
[01:20:30] AI Anna: In this episode of the Latent Space Podcast, we delved into the world of LLM Ops, and had a wide ranging conversation with Dr. Raza Habib, co founder of HumanLoop. We covered what is HumanLoop, the three stages of prompt evals, the three types of human feedback, HumanLoop's new free tier and pricing, the competitive landscape and graduation risk of HumanLoop, PromptOps versus MLops, PromptEngineer versus AI Engineer.
[01:21:00] Did GPT 4 get dumber? Europe's AI scene versus San Francisco. And don't sleep on Rasa's in depth explanations of LLM cascades and DeepMind's work on continuous learning. If you are interested in Human Loop, definitely check out their hiring page and new pricing and vote for them on the state of AI engineering survey.
[01:21:19] Thank you for tuning into the Latent Space Podcast. Don't forget to like, subscribe and tweet your takes at Latent Space Pod. Now go build.
For frontend/JAMstack devs, this was a three way battle between startups building metaframeworks, cloud infra, and content management systems, and various combinations of each. Arguably round 1 won by Nextjs/Vercel and Contentful.
In data engineering, a similar battle ensued between data catalogs, semantic layers, and business intelligence, though we are still in very early days of category collapse.
Even in fintech, you see Deel/Rippling/Ramp/Brex building each other’s features as fast as they can between the trio of contractor, payroll, and corporate spending products.
There are many ways to draw the stool, and arguably the Foundation Model Ops stool perches atop the much larger *Ops stool, which consists of LLMOps vs MLOps vs Data stores, which is why you see Weights & Biases build a Prompts offering, Scale build Spellbook, and Databricks buying Mosaic.