


We are running an end of year survey for our listeners! Please let us know any feedback you have, what episodes resonated with you, and guest requests for 2024! Survey link here!
Listen to the end for a little surprise from Suhail.
Before language models became all the rage in November 2022, image generation was the hottest space in AI (it was the subject of our first piece on Latent Space!) In our interview with Sharif Shameem from Lexica we talked through the launch of StableDiffusion and the early days of that space. At the time, the toolkit was still pretty rudimentary: Lexica made it easy to search images1, you had the AUTOMATIC1111 Web UI to generate locally, some HuggingFace spaces that offered inference, and eventually DALL-E 2 through OpenAI’s platform, but not much beyond basic text-to-image workflows.
Today’s guest, Suhail Doshi, is trying to solve this with Playground AI, an image editor reimagined with AI in mind. Some of the differences compared to traditional text-to-image workflows:
Real-time preview rendering using consistency: as you change your prompt, you can see changes in real-time before doing a final rendering of it.
Style filtering: rather than having to prompt exactly how you’d like an image to look, you can pick from a whole range of filters both from Playground’s model as well as Stable Diffusion (like RealVis, Starlight XL, etc). We talk about this at 25:46 in the podcast.
Expand prompt: similar to DALL-E3, Playground will do some prompt tuning for you to get better results in generation. Unlike DALL-E3, you can turn this off at any time if you are a prompting wizard
Image editing: after generation, you have tools like a magic eraser, inpainting pencil, etc. This makes it easier to do a full workflow in Playground rather than switching to another tool like Photoshop.

Outside of the product, they have also trained a new model from scratch, Playground v2, which is fully open source and open weights and allows for commercial usage.

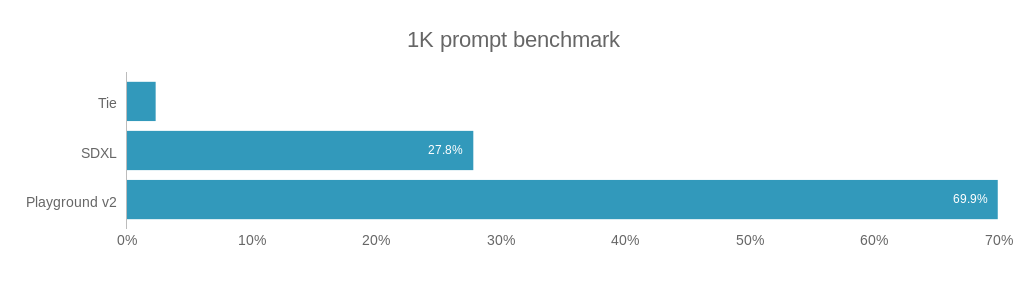
They benchmarked the model against SDXL across 1,000 prompts and found that humans preferred the Playground generation 70% of the time. They had similar results on PartiPrompts:

They also created a new benchmark, MJHQ-30K, for “aesthetic quality”:
We introduce a new benchmark, MJHQ-30K, for automatic evaluation of a model’s aesthetic quality. The benchmark computes FID on a high-quality dataset to gauge aesthetic quality.
We curate the high-quality dataset from Midjourney with 10 common categories, each category with 3K samples. Following common practice, we use aesthetic score and CLIP score to ensure high image quality and high image-text alignment. Furthermore, we take extra care to make the data diverse within each category.

Suhail was pretty open with saying that Midjourney is currently the best product for imagine generation out there, and that’s why they used it as the base for this benchmark.
I think it's worth comparing yourself to maybe the best thing and try to find like a really fair way of doing that. So I think more people should try to do that. I definitely don't think you should be kind of comparing yourself on like some Google model or some old SD, Stable Diffusion model and be like, look, we beat Stable Diffusion 1.5. I think users ultimately want care, how close are you getting to the thing that people mostly agree with? [00:23:47]
We also talked a lot about Suhail’s founder journey from starting Mixpanel in 2009, then going through YC again with Mighty, and eventually sunsetting that to pivot into Playground. Enjoy!
Show Notes
Timestamps
[00:00:00] Intros
[00:02:59] Being early in ML at Mixpanel
[00:04:16] Pivoting from Mighty to Playground and focusing on generative AI
[00:07:54] How DALL-E 2 inspired Mighty
[00:09:19] Reimagining the graphics editor with AI
[00:17:34] Training the Playground V2 model from scratch to advance generative graphics
[00:21:11] Techniques used to improve Playground V2 like data filtering and model tuning
[00:25:21] Releasing the MJHQ30K benchmark to evaluate generative models
[00:30:35] The limitations of current models for detailed image editing tasks
[00:34:06] Using post-generation user feedback to create better benchmarks
[00:38:28] Concerns over potential misuse of powerful generative models
[00:41:54] Rethinking the graphics editor user experience in the AI era
[00:45:44] Integrating consistency models into Playground using preview rendering
[00:47:23] Interacting with the Stable Diffusion LoRAs community
[00:51:35] Running DevOps on A100s
[00:53:12] Startup ideas?
Transcript
Alessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI. [00:00:15]
Swyx: Hey, and today in the studio we have Suhail Doshi, welcome. [00:00:18]
Suhail: Yeah, thanks. Thanks for having me. [00:00:20]
Swyx: So among many things, you're a CEO and co-founder of Mixpanel, and I think about three years ago you left to start Mighty, and more recently, I think about a year ago, transitioned into Playground, and you've just announced your new round. How do you like to be introduced beyond that? [00:00:34]
Suhail: Just founder of Playground is fine, yeah, prior co-founder and CEO of Mixpanel. [00:00:40]
Swyx: Yeah, awesome. I'd just like to touch on Mixpanel a little bit, because it's obviously one of the more successful analytics companies we previously had amplitude on, and I'm curious if you had any reflections on the interaction of that amount of data that people would want to use for AI. I don't know if there's still a part of you that stays in touch with that world. [00:00:59]
Suhail: Yeah, I mean, the short version is that maybe back in like 2015 or 2016, I don't really remember exactly, because it was a while ago, we had an ML team at Mixpanel, and I think this is when maybe deep learning or something really just started getting kind of exciting, and we were thinking that maybe given that we had such vast amounts of data, perhaps we could predict things. So we built two or three different features, I think we built a feature where we could predict whether users would churn from your product. We made a feature that could predict whether users would convert, we built a feature that could do anomaly detection, like if something occurred in your product, that was just very surprising, maybe a spike in traffic in a particular region, can we tell you that that happened? Because it's really hard to like know everything that's going on with your data, can we tell you something surprising about your data? And we tried all of these various features, most of it boiled down to just like, you know, using logistic regression, and it never quite seemed very groundbreaking in the end. And so I think, you know, we had a four or five person ML team, and I think we never expanded it from there. And I did all these Fast AI courses trying to learn about ML. And that was the- That's the first time you did fast AI. Yeah, that was the first time I did fast AI. Yeah, I think I've done it now three times, maybe. [00:02:12]
Swyx: Oh, okay. [00:02:13]
Suhail: I didn't know it was the third. No, no, just me reviewing it, it's maybe three times, but yeah. [00:02:16]
Swyx: You mentioned prediction, but honestly, like it's also just about the feedback, right? The quality of feedback from users, I think it's useful for anyone building AI applications. [00:02:25]
Suhail: Yeah. Yeah, I think I haven't spent a lot of time thinking about Mixpanel because it's been a long time, but sometimes I'm like, oh, I wonder what we could do now. And then I kind of like move on to whatever I'm working on, but things have changed significantly since. [00:02:39]
Swyx: And then maybe we'll touch on Mighty a little bit. Mighty was very, very bold. My framing of it was, you will run our browsers for us because everyone has too many tabs open. I have too many tabs open and slowing down your machines that you can do it better for us in a centralized data center. [00:02:51]
Suhail: Yeah, we were first trying to make a browser that we would stream from a data center to your computer at extremely low latency, but the real objective wasn't trying to make a browser or anything like that. The real objective was to try to make a new kind of computer. And the thought was just that like, you know, we have these computers in front of us today and we upgrade them or they run out of RAM or they don't have enough RAM or not enough disk or, you know, there's some limitation with our computers, perhaps like data locality is a problem. Why do I need to think about upgrading my computer ever? And so, you know, we just had to kind of observe that like, well, actually it seems like a lot of applications are just now in the browser, you know, it's like how many real desktop applications do we use relative to the number of applications we use in the browser? So it's just this realization that actually like, you know, the browser was effectively becoming more or less our operating system over time. And so then that's why we kind of decided to go, hmm, maybe we can stream the browser. Fortunately, the idea did not work for a couple of different reasons, but the objective is try to make sure new computer. [00:03:50]
Swyx: Yeah, very, very bold. [00:03:51]
Alessio: Yeah, and I was there at YC Demo Day when you first announced it. It was, I think, the last or one of the last in-person ones, at Pier34 in Mission Bay. How do you think about that now when everybody wants to put some of these models in people's machines and some of them want to stream them in, do you think there's maybe another wave of the same problem before it was like browser apps too slow, now it's like models too slow to run on device? [00:04:16]
Suhail: Yeah. I mean, I've obviously pivoted away from Mighty, but a lot of what I somewhat believed at Mighty, maybe why I'm so excited about AI and what's happening, a lot of what Mighty was about was like moving compute somewhere else, right? Right now, applications, they get limited quantities of memory, disk, networking, whatever your home network has, et cetera. You know, what if these applications could somehow, if we could shift compute, and then these applications have vastly more compute than they do today. Right now it's just like client backend services, but you know, what if we could change the shape of how applications could interact with things? And it's changed my thinking. In some ways, AI has like a bit of a continuation of my belief that like perhaps we can really shift compute somewhere else. One of the problems with Mighty was that JavaScript is single-threaded in the browser. And what we learned, you know, the reason why we kind of abandoned Mighty was because I didn't believe we could make a new kind of computer. We could have made some kind of enterprise business, probably it could have made maybe a lot of money, but it wasn't going to be what I hoped it was going to be. And so once I realized that most of a web app is just going to be single-threaded JavaScript, then the only thing you could do largely withstanding changing JavaScript, which is a fool's errand most likely, make a better CPU, right? And there's like three CPU manufacturers, two of which sell, you know, big ones, you know, AMD, Intel, and then of course like Apple made the M1. And it's not like single-threaded CPU core performance, single-core performance was increasing very fast, it's plateauing rapidly. And even these different companies were not doing as good of a job, you know, sort of with the continuation of Moore's law. But what happened in AI was that you got like, if you think of the AI model as like a computer program, like just like a compiled computer program, it is literally built and designed to do massive parallel computations. And so if you could take like the universal approximation theorem to its like kind of logical complete point, you know, you're like, wow, I can get, make computation happen really rapidly and parallel somewhere else, you know, so you end up with these like really amazing models that can like do anything. It just turned out like perhaps the new kind of computer would just simply be shifted, you know, into these like really amazing AI models in reality. Yeah. [00:06:30]
Swyx: Like I think Andrej Karpathy has always been, has been making a lot of analogies with the LLMOS. [00:06:34]
Suhail: I saw his video and I watched that, you know, maybe two weeks ago or something like that. I was like, oh man, this, I very much resonate with this like idea. [00:06:41]
Swyx: Why didn't I see this three years ago? [00:06:43]
Suhail: Yeah. I think, I think there still will be, you know, local models and then there'll be these very large models that have to be run in data centers. I think it just depends on kind of like the right tool for the job, like any engineer would probably care about. But I think that, you know, by and large, like if the models continue to kind of keep getting bigger, you're always going to be wondering whether you should use the big thing or the small, you know, the tiny little model. And it might just depend on like, you know, do you need 30 FPS or 60 FPS? Maybe that would be hard to do, you know, over a network. [00:07:13]
Swyx: You tackled a much harder problem latency wise than the AI models actually require. Yeah. [00:07:18]
Suhail: Yeah. You can do quite well. You can do quite well. You definitely did 30 FPS video streaming, did very crazy things to make that work. So I'm actually quite bullish on the kinds of things you can do with networking. [00:07:30]
Swyx: Maybe someday you'll come back to that at some point. But so for those that don't know, you're very transparent on Twitter. Very good to follow you just to learn your insights. And you actually published a postmortem on Mighty that people can read up on and willing to. So there was a bit of an overlap. You started exploring the AI stuff in June 2022, which is when you started saying like, I'm taking fast AI again. Maybe, was there more context around that? [00:07:54]
Suhail: Yeah. I think I was kind of like waiting for the team at Mighty to finish up, you know, something. And I was like, okay, well, what can I do? I guess I will make some kind of like address bar predictor in the browser. So we had, you know, we had forked Chrome and Chromium. And I was like, you know, one thing that's kind of lame is that like this browser should be like a lot better at predicting what I might do, where I might want to go. It struck me as really odd that, you know, Chrome had very little AI actually or ML inside this browser. For a company like Google, you'd think there's a lot. Code is actually just very, you know, it's just a bunch of if then statements is more or less the address bar. So it seemed like a pretty big opportunity. And that's also where a lot of people interact with the browser. So, you know, long story short, I was like, hmm, I wonder what I could build here. So I started to take some AI courses and review the material again and get back to figuring it out. But I think that was somewhat serendipitous because right around April was, I think, a very big watershed moment in AI because that's when Dolly 2 came out. And I think that was the first truly big viral moment for generative AI. [00:08:59]
Swyx: Because of the avocado chair. [00:09:01]
Suhail: Yeah, exactly. [00:09:02]
Swyx: It wasn't as big for me as Stable Diffusion. [00:09:04]
Suhail: Really? [00:09:05]
Swyx: Yeah, I don't know. Dolly was like, all right, that's cool. [00:09:07]
Suhail: I don't know. Yeah. [00:09:09]
Swyx: I mean, they had some flashy videos, but it didn't really register. [00:09:13]
Suhail: That moment of images was just such a viral novel moment. I think it just blew people's mind. Yeah. [00:09:19]
Swyx: I mean, it's the first time I encountered Sam Altman because they had this Dolly 2 hackathon and they opened up the OpenAI office for developers to walk in back when it wasn't as much of a security issue as it is today. I see. Maybe take us through the journey to decide to pivot into this and also choosing images. Obviously, you were inspired by Dolly, but there could be any number of AI companies and businesses that you could start and why this one, right? [00:09:45]
Suhail: Yeah. So I think at that time, Mighty and OpenAI was not quite as popular as it is all of a sudden now these days, but back then they had a lot more bandwidth to kind of help anybody. And so we had been talking with the team there around trying to see if we could do really fast low latency address bar prediction with GPT-3 and 3.5 and that kind of thing. And so we were sort of figuring out how could we make that low latency. I think that just being able to talk to them and kind of being involved gave me a bird's eye view into a bunch of things that started to happen. Latency first was the Dolly 2 moment, but then stable diffusion came out and that was a big moment for me as well. And I remember just kind of like sitting up one night thinking, I was like, you know, what are the kinds of companies one could build? Like what matters right now? One thing that I observed is that I find a lot of inspiration when I'm working in a field in something and then I can identify a bunch of problems. Like for Mixpanel, I was an intern at a company and I just noticed that they were doing all this data analysis. And so I thought, hmm, I wonder if I could make a product and then maybe they would use it. And in this case, you know, the same thing kind of occurred. It was like, okay, there are a bunch of like infrastructure companies that put a model up and then you can use their API, like Replicate is a really good example of that. There are a bunch of companies that are like helping you with training, model optimization, Mosaic at the time, and probably still, you know, was doing stuff like that. So I just started listing out like every category of everything, of every company that was doing something interesting. I started listing out like weights and biases. I was like, oh man, weights and biases is like this great company. Do I want to compete with that company? I might be really good at competing with that company because of Mixpanel because it's so much of like analysis. But I was like, no, I don't want to do anything related to that. That would, I think that would be too boring now at this point. So I started to list out all these ideas and one thing I observed was that at OpenAI, they had like a playground for GPT-3, right? All it was is just like a text box more or less. And then there were some settings on the right, like temperature and whatever. [00:11:41]
Swyx: Top K. [00:11:42]
Suhail: Yeah, top K. You know, what's your end stop sequence? I mean, that was like their product before GPT, you know, really difficult to use, but fun if you're like an engineer. And I just noticed that their product kind of was evolving a little bit where the interface kind of was getting a little bit more complex. They had like a way where you could like generate something in the middle of a sentence and all those kinds of things. And I just thought to myself, I was like, everything is just like this text box and you generate something and that's about it. And stable diffusion had kind of come out and it was all like hugging face and code. Nobody was really building any UI. And so I had this kind of thing where I wrote prompt dash like question mark in my notes and I didn't know what was like the product for that at the time. I mean, it seems kind of trite now, but I just like wrote prompt. What's the thing for that? Manager. Prompt manager. Do you organize them? Like, do you like have a UI that can play with them? Yeah. Like a library. What would you make? And so then, of course, then you thought about what would the modalities be given that? How would you build a UI for each kind of modality? And so there are a couple of people working on some pretty cool things. And I basically chose graphics because it seemed like the most obvious place where you could build a really powerful, complex UI. That's not just only typing a box. It would very much evolve beyond that. Like what would be the best thing for something that's visual? Probably something visual. Yeah. I think that just that progression kind of happened and it just seemed like there was a lot of effort going into language, but not a lot of effort going into graphics. And then maybe the very last thing was, I think I was talking to Aditya Ramesh, who was the co-creator of DALL-E 2 and Sam. And I just kind of went to these guys and I was just like, hey, are you going to make like a UI for this thing? Like a true UI? Are you going to go for this? Are you going to make a product? For DALL-E. Yeah. For DALL-E. Yeah. Are you going to do anything here? Because if you are going to do it, just let me know and I will stop and I'll go do something else. But if you're not going to do anything, I'll just do it. And so we had a couple of conversations around what that would look like. And then I think ultimately they decided that they were going to focus on language primarily. And I just felt like it was going to be very underinvested in. Yes. [00:13:46]
Swyx: There's that sort of underinvestment from OpenAI, but also it's a different type of customer than you're used to, presumably, you know, and Mixpanel is very good at selling to B2B and developers will figure on you or not. Yeah. Was that not a concern? [00:14:00]
Suhail: Well, not so much because I think that, you know, right now I would say graphics is in this very nascent phase. Like most of the customers are just like hobbyists, right? Yeah. Like it's a little bit of like a novel toy as opposed to being this like very high utility thing. But I think ultimately, if you believe that you could make it very high utility, the probably the next customers will end up being B2B. It'll probably not be like a consumer. There will certainly be a variation of this idea that's in consumer. But if your quest is to kind of make like something that surpasses human ability for graphics, like ultimately it will end up being used for business. So I think it's maybe more of a progression. In fact, for me, it's maybe more like Mixpanel started out as SMB and then very much like ended up starting to grow up towards enterprise. So for me, I think it will be a very similar progression. But yeah, I mean, the reason why I was excited about it is because it was a creative tool. I make music and it's AI. It's like something that I know I could stay up till three o'clock in the morning doing. Those are kind of like very simple bars for me. [00:14:56]
Alessio: So you mentioned Dolly, Stable Diffusion. You just had Playground V2 come out two days ago. Yeah, two days ago. [00:15:02]
Suhail: Two days ago. [00:15:03]
Alessio: This is a model you train completely from scratch. So it's not a cheap fine tune on something. You open source everything, including the weights. Why did you decide to do it? I know you supported Stable Diffusion XL in Playground before, right? Yep. What made you want to come up with V2 and maybe some of the interesting, you know, technical research work you've done? [00:15:24]
Suhail: Yeah. So I think that we continue to feel like graphics and these foundation models for anything really related to pixels, but also definitely images continues to be very underinvested. It feels a little like graphics is in like this GPT-2 moment, right? Like even GPT-3, even when GPT-3 came out, it was exciting, but it was like, what are you going to use this for? Yeah, we'll do some text classification and some semantic analysis and maybe it'll sometimes like make a summary of something and it'll hallucinate. But no one really had like a very significant like business application for GPT-3. And in images, we're kind of stuck in the same place. We're kind of like, okay, I write this thing in a box and I get some cool piece of artwork and the hands are kind of messed up and sometimes the eyes are a little weird. Maybe I'll use it for a blog post, you know, that kind of thing. The utility feels so limited. And so, you know, and then we, you sort of look at Stable Diffusion and we definitely use that model in our product and our users like it and use it and love it and enjoy it, but it hasn't gone nearly far enough. So we were kind of faced with the choice of, you know, do we wait for progress to occur or do we make that progress happen? So yeah, we kind of embarked on a plan to just decide to go train these things from scratch. And I think the community has given us so much. The community for Stable Diffusion I think is one of the most vibrant communities on the internet. It's like amazing. It feels like, I hope this is what like Homebrew Club felt like when computers like showed up because it's like amazing what that community will do and it moves so fast. I've never seen anything in my life and heard other people's stories around this where an academic research paper comes out and then like two days later, someone has sample code for it. And then two days later, there's a model. And then two days later, it's like in nine products, you know, they're all competing with each other. It's incredible to see like math symbols on an academic paper go to well-designed features in a product. So I think the community has done so much. So I think we wanted to give back to the community kind of on our way. Certainly we would train a better model than what we gave out on Tuesday, but we definitely felt like there needs to be some kind of progress in these open source models. The last kind of milestone was in July when Stable Diffusion Excel came out, but there hasn't been anything really since. Right. [00:17:34]
Swyx: And there's Excel Turbo now. [00:17:35]
Suhail: Well, Excel Turbo is like this distilled model, right? So it's like lower quality, but fast. You have to decide, you know, what your trade off is there. [00:17:42]
Swyx: It's also a consistency model. [00:17:43]
Suhail: I don't think it's a consistency model. It's like it's they did like a different thing. Yeah. I think it's like, I don't want to get quoted for this, but it's like something called ad like adversarial or something. [00:17:52]
Swyx: That's exactly right. [00:17:53]
Suhail: I've read something about that. Maybe it's like closer to GANs or something, but I didn't really read the full paper. But yeah, there hasn't been quite enough progress in terms of, you know, there's no multitask image model. You know, the closest thing would be something called like EmuEdit, but there's no model for that. It's just a paper that's within meta. So we did that and we also gave out pre-trained weights, which is very rare. Usually you just get the aligned model and then you have to like see if you can do anything with it. So we actually gave out, there's like a 256 pixel pre-trained stage and a 512. And we did that for academic research because we come across people all the time in academia, they have access to like one A100 or eight at best. And so if we can give them kind of like a 512 pre-trained model, our hope is that there'll be interesting novel research that occurs from that. [00:18:38]
Swyx: What research do you want to happen? [00:18:39]
Suhail: I would love to see more research around things that users care about tend to be things like character consistency. [00:18:45]
Swyx: Between frames? [00:18:46]
Suhail: More like if you have like a face. Yeah, yeah. Basically between frames, but more just like, you know, you have your face and it's in one image and then you want it to be like in another. And users are very particular and sensitive to faces changing because we know we're trained on faces as humans. Not seeing a lot of innovation, enough innovation around multitask editing. You know, there are two things like instruct pics to pics and then the EmuEdit paper that are maybe very interesting, but we certainly are not pushing the fold on that in that regard. All kinds of things like around that rotation, you know, being able to keep coherence across images, style transfer is still very limited. Just even reasoning around images, you know, what's going on in an image, that kind of thing. Things are still very, very underpowered, very nascent. So therefore the utility is very, very limited. [00:19:32]
Alessio: On the 1K Prompt Benchmark, you are 2.5x prefer to Stable Diffusion XL. How do you get there? Is it better images in the training corpus? Can you maybe talk through the improvements in the model? [00:19:44]
Suhail: I think they're still very early on in the recipe, but I think it's a lot of like little things and you know, every now and then there are some big important things like certainly your data quality is really, really important. So we spend a lot of time thinking about that. But I would say it's a lot of things that you kind of clean up along the way as you train your model. Everything from captions to the data that you align with after pre-train to how you're picking your data sets, how you filter your data sets. I feel like there's a lot of work in AI that doesn't really feel like AI. It just really feels like just data set filtering and systems engineering and just like, you know, and the recipe is all there, but it's like a lot of extra work to do that. I think we plan to do a Playground V 2.1, maybe either by the end of the year or early next year. And we're just like watching what the community does with the model. And then we're just going to take a lot of the things that they're unhappy about and just like fix them. You know, so for example, like maybe the eyes of people in an image don't feel right. They feel like they're a little misshapen or they're kind of blurry feeling. That's something that we already know we want to fix. So I think in that case, it's going to be about data quality. Or maybe you want to improve the kind of the dynamic range of color. You know, we want to make sure that that's like got a good range in any image. So what technique can we use there? There's different things like offset noise, pyramid noise, terminal zero, SNR, like there are all these various interesting things that you can do. So I think it's like a lot of just like tricks. Some are tricks, some are data, and some is just like cleaning. [00:21:11]
Swyx: Specifically for faces, it's very common to use a pipeline rather than just train the base model more. Do you have a strong belief either way on like, oh, they should be separated out to different stages for like improving the eyes, improving the face or enhance or whatever? Or do you think like it can all be done in one model? [00:21:28]
Suhail: I think we will make a unified model. Yeah, I think it will. I think we'll certainly in the end, ultimately make a unified model. There's not enough research about this. Maybe there is something out there that we haven't read. There are some bottlenecks, like for example, in the VAE, like the VAEs are ultimately like compressing these things. And so you don't know. And then you might have like a big informational information bottleneck. So maybe you would use a pixel based model, perhaps. I think we've talked to people, everyone from like Rombach to various people, Rombach trained stable diffusion. I think there's like a big question around the architecture of these things. It's still kind of unknown, right? Like we've got transformers and we've got like a GPT architecture model, but then there's this like weird thing that's also seemingly working with diffusion. And so, you know, are we going to use vision transformers? Are we going to move to pixel based models? Is there a different kind of architecture? We don't really, I don't think there have been enough experiments. Still? Oh my God. [00:22:21]
Swyx: Yeah. [00:22:22]
Suhail: That's surprising. I think it's very computationally expensive to do a pipeline model where you're like fixing the eyes and you're fixing the mouth and you're fixing the hands. [00:22:29]
Swyx: That's what everyone does as far as I understand. [00:22:31]
Suhail: I'm not exactly sure what you mean, but if you mean like you get an image and then you will like make another model specifically to fix a face, that's fairly computationally expensive. And I think it's like not probably not the right way. Yeah. And it doesn't generalize very well. Now you have to pick all these different things. [00:22:45]
Swyx: Yeah. You're just kind of glomming things on together. Yeah. Like when I look at AI artists, like that's what they do. [00:22:50]
Suhail: Ah, yeah, yeah, yeah. They'll do things like, you know, I think a lot of ARs will do control net tiling to do kind of generative upscaling of all these different pieces of the image. Yeah. And I think these are all just like, they're all hacks ultimately in the end. I mean, it just to me, it's like, let's go back to where we were just three years, four years ago with where deep learning was at and where language was that, you know, it's the same thing. It's like we were like, okay, well, I'll just train these very narrow models to try to do these things and kind of ensemble them or pipeline them to try to get to a best in class result. And here we are with like where the models are gigantic and like very capable of solving huge amounts of tasks when given like lots of great data. [00:23:28]
Alessio: You also released a new benchmark called MJHQ30K for automatic evaluation of a model's aesthetic quality. I have one question. The data set that you use for the benchmark is from Midjourney. Yes. You have 10 categories. How do you think about the Playground model, Midjourney, like, are you competitors? [00:23:47]
Suhail: There are a lot of people, a lot of people in research, they like to compare themselves to something they know they can beat, right? Maybe this is the best reason why it can be helpful to not be a researcher also sometimes like I'm not trained as a researcher, I don't have a PhD in anything AI related, for example. But I think if you care about products and you care about your users, then the most important thing that you want to figure out is like everyone has to acknowledge that Midjourney is very good. They are the best at this thing. I'm happy to admit that. I have no problem admitting that. Just easy. It's very visual to tell. So I think it's incumbent on us to try to compare ourselves to the thing that's best, even if we lose, even if we're not the best. At some point, if we are able to surpass Midjourney, then we only have ourselves to compare ourselves to. But on First Blush, I think it's worth comparing yourself to maybe the best thing and try to find like a really fair way of doing that. So I think more people should try to do that. I definitely don't think you should be kind of comparing yourself on like some Google model or some old SD, Stable Diffusion model and be like, look, we beat Stable Diffusion 1.5. I think users ultimately want care, how close are you getting to the thing that people mostly agree with? So we put out that benchmark for no other reason to say like, this seems like a worthy thing for us to at least try, for people to try to get to. And then if we surpass it, great, we'll come up with another one. [00:25:06]
Alessio: Yeah, no, that's awesome. And you killed Stable Diffusion Excel and everything. In the benchmark chart, it says Playground V2 1024 pixel dash aesthetic. Do you have kind of like, yeah, style fine tunes or like what's the dash aesthetic for? [00:25:21]
Suhail: We debated this, maybe we named it wrong or something, but we were like, how do we help people realize the model that's aligned versus the models that weren't? Because we gave out pre-trained models, we didn't want people to like use those. So that's why they're called base. And then the aesthetic model, yeah, we wanted people to pick up the thing that makes things pretty. Who wouldn't want the thing that's aesthetic? But if there's a better name, we're definitely open to feedback. No, no, that's cool. [00:25:46]
Alessio: I was using the product. You also have the style filter and you have all these different styles. And it seems like the styles are tied to the model. So there's some like SDXL styles, there's some Playground V2 styles. Can you maybe give listeners an overview of how that works? Because in language, there's not this idea of like style, right? Versus like in vision model, there is, and you cannot get certain styles in different [00:26:11]
Suhail: models. [00:26:12]
Alessio: So how do styles emerge and how do you categorize them and find them? [00:26:15]
Suhail: Yeah, I mean, it's so fun having a community where people are just trying a model. Like it's only been two days for Playground V2. And we actually don't know what the model's capable of and not capable of. You know, we certainly see problems with it. But we have yet to see what emergent behavior is. I mean, we've just sort of discovered that it takes about like a week before you start to see like new things. I think like a lot of that style kind of emerges after that week, where you start to see, you know, there's some styles that are very like well known to us, like maybe like pixel art is a well known style. Photorealism is like another one that's like well known to us. But there are some styles that cannot be easily named. You know, it's not as simple as like, okay, that's an anime style. It's very visual. And in the end, you end up making up the name for what that style represents. And so the community kind of shapes itself around these different things. And so if anyone that's into stable diffusion and into building anything with graphics and stuff with these models, you know, you might have heard of like Proto Vision or Dream Shaper, some of these weird names, but they're just invented by these authors. But they have a sort of je ne sais quoi that, you know, appeals to users. [00:27:26]
Swyx: Because it like roughly embeds to what you what you want. [00:27:29]
Suhail: I guess so. I mean, it's like, you know, there's one of my favorite ones that's fine tuned. It's not made by us. It's called like Starlight XL. It's just this beautiful model. It's got really great color contrast and visual elements. And the users love it. I love it. And it's so hard. I think that's like a very big open question with graphics that I'm not totally sure how we'll solve. I don't know. It's, it's like an evolving situation too, because styles get boring, right? They get fatigued. Like it's like listening to the same style of pop song. I try to relate to graphics a little bit like with music, because I think it gives you a little bit of a different shape to things. Like it's not as if we just have pop music, rap music and country music, like all of these, like the EDM genre alone has like sub genres. And I think that's very true in graphics and painting and art and anything that we're doing. There's just these sub genres, even if we can't quite always name them. But I think they are emergent from the community, which is why we're so always happy to work with the community. [00:28:26]
Swyx: That is a struggle. You know, coming back to this, like B2B versus B2C thing, B2C, you're going to have a huge amount of diversity and then it's going to reduce as you get towards more sort of B2B type use cases. I'm making this up here. So like you might be optimizing for a thing that you may eventually not need. [00:28:42]
Suhail: Yeah, possibly. Yeah, possibly. I think like a simple thing with startups is that I worry sometimes by trying to be overly ambitious and like really scrutinizing like what something is in its most nascent phase that you miss the most ambitious thing you could have done. Like just having like very basic curiosity with something very small can like kind of lead you to something amazing. Like Einstein definitely did that. And then he like, you know, he basically won all the prizes and got everything he wanted and then basically did like kind of didn't really. He can dismiss quantum and then just kind of was still searching, you know, for the unifying theory. And he like had this quest. I think that happens a lot with like Nobel Prize people. I think there's like a term for it that I forget. I actually wanted to go after a toy almost intentionally so long as that I could see, I could imagine that it would lead to something very, very large later. Like I said, it's very hobbyist, but you need to start somewhere. You need to start with something that has a big gravitational pull, even if these hobbyists aren't likely to be the people that, you know, have a way to monetize it or whatever, even if they're, but they're doing it for fun. So there's something, something there that I think is really important. But I agree with you that, you know, in time we will absolutely focus on more utilitarian things like things that are more related to editing feats that are much harder. And so I think like a very simple use case is just, you know, I'm not a graphics designer. It seems like very simple that like you, if we could give you the ability to do really complex graphics without skill, wouldn't you want that? You know, like my wife the other day was set, you know, said, I wish Playground was better. When are you guys going to have a feature where like we could make my son, his name's Devin, smile when he was not smiling in the picture for the holiday card. Right. You know, just being able to highlight his, his mouth and just say like, make him smile. Like why can't we do that with like high fidelity and coherence, little things like that, all the way to putting you in completely different scenarios. [00:30:35]
Swyx: Is that true? Can we not do that in painting? [00:30:37]
Suhail: You can do in painting, but the quality is just so bad. Yeah. It's just really terrible quality. You know, it's like you'll do it five times and it'll still like kind of look like crooked or just artifact. Part of it's like, you know, the lips on the face, there's such little information there. So small that the models really struggle with it. Yeah. [00:30:55]
Swyx: Make the picture smaller and you don't see it. That's my trick. I don't know. [00:30:59]
Suhail: Yeah. Yeah. That's true. Or, you know, you could take that region and make it really big and then like say it's a mouth and then like shrink it. It feels like you're wrestling with it more than it's doing something that kind of surprises you. [00:31:12]
Swyx: Yeah. It feels like you are very much the internal tastemaker, like you carry in your head this vision for what a good art model should look like. Do you find it hard to like communicate it to like your team and other people? Just because it's obviously it's hard to put into words like we just said. [00:31:26]
Suhail: Yeah. It's very hard to explain. Images have such high bitrate compared to just words and we don't have enough words to describe these things. It's not terribly difficult. I think everyone on the team, if they don't have good kind of like judgment taste or like an eye for some of these things, they're like steadily building it because they have no choice. Right. So in that realm, I don't worry too much, actually. Like everyone is kind of like learning to get the eye is what I would call it. But I also have, you know, my own narrow taste. Like I don't represent the whole population either. [00:31:59]
Swyx: When you benchmark models, you know, like this benchmark we're talking about, we use FID. Yeah. Input distance. OK. That's one measure. But like it doesn't capture anything you just said about smiles. [00:32:08]
Suhail: Yeah. FID is generally a bad metric. It's good up to a point and then it kind of like is irrelevant. Yeah. [00:32:14]
Swyx: And then so are there any other metrics that you like apart from vibes? I'm always looking for alternatives to vibes because vibes don't scale, you know. [00:32:22]
Suhail: You know, it might be fun to kind of talk about this because it's actually kind of fresh. So up till now, we haven't needed to do a ton of like benchmarking because we hadn't trained our own model and now we have. So now what? What does that mean? How do we evaluate it? And, you know, we're kind of like living with the last 48, 72 hours of going, did the way that we benchmark actually succeed? [00:32:43]
Swyx: Did it deliver? [00:32:44]
Suhail: Right. You know, like I think Gemini just came out. They just put out a bunch of benchmarks. But all these benchmarks are just an approximation of how you think it's going to end up with real world performance. And I think that's like very fascinating to me. So if you fake that benchmark, you'll still end up in a really bad scenario at the end of the day. And so, you know, one of the benchmarks we did was we kind of curated like a thousand prompts. And I think that's kind of what we published in our blog post, you know, of all these tasks that we a lot of some of them are curated by our team where we know the models all suck at it. Like my favorite prompt that no model is really capable of is a horse riding an astronaut, the inverse one. And it's really, really hard to do. [00:33:22]
Swyx: Not in data. [00:33:23]
Suhail: You know, another one is like a giraffe underneath a microwave. How does that work? Right. There's so many of these little funny ones. We do. We have prompts that are just like misspellings of things. Yeah. We'll figure out if the models will figure it out. [00:33:36]
Swyx: They should embed to the same space. [00:33:39]
Suhail: Yeah. And just like all these very interesting weirdo things. And so we have so many of these and then we kind of like evaluate whether the models are any good at it. And the reality is that they're all bad at it. And so then you're just picking the most aesthetic image. We're still at the beginning of building like the best benchmark we can that aligns most with just user happiness, I think, because we're not we're not like putting these in papers and trying to like win, you know, I don't know, awards at ICCV or something if they have awards. You could. [00:34:05]
Swyx: That's absolutely a valid strategy. [00:34:06]
Suhail: Yeah, you could. But I don't think it could correlate necessarily with the impact we want to have on humanity. I think we're still evolving whatever our benchmarks are. So the first benchmark was just like very difficult tasks that we know the models are bad at. Can we come up with a thousand of these, whether they're hand rated and some of them are generated? And then can we ask the users, like, how do we do? And then we wanted to use a benchmark like party prompts. We mostly did that so people in academia could measure their models against ours versus others. But yeah, I mean, fit is pretty bad. And I think in terms of vibes, it's like you put out the model and then you try to see like what users make. And I think my sense is that we're going to take all the things that we notice that the users kind of were failing at and try to find like new ways to measure that, whether that's like a smile or, you know, color contrast or lighting. One benefit of Playground is that we have users making millions of images every single day. And so we can just ask them for like a post generation feedback. Yeah, we can just ask them. We can just say, like, how good was the lighting here? How was the subject? How was the background? [00:35:06]
Swyx: Like a proper form of like, it's just like you make it, you come to our site, you make [00:35:10]
Suhail: an image and then we say, and then maybe randomly you just say, hey, you know, like, how was the color and contrast of this image? And you say it was not very good, just tell us. So I think I think we can get like tens of thousands of these evaluations every single day to truly measure real world performance as opposed to just like benchmark performance. I would like to publish hopefully next year. I think we will try to publish a benchmark that anyone could use, that we evaluate ourselves on and that other people can, that we think does a good job of approximating real world performance because we've tried it and done it and noticed that it did. Yeah. I think we will do that. [00:35:45]
Swyx: I personally have a few like categories that I consider special. You know, you know, you have like animals, art, fashion, food. There are some categories which I consider like a different tier of image. Top among them is text in images. How do you think about that? So one of the big wow moments for me, something I've been looking out for the entire year is just the progress of text and images. Like, can you write in an image? Yeah. And Ideogram came out recently, which had decent but not perfect text and images. Dolly3 had improved some and all they said in their paper was that they just included more text in the data set and it just worked. I was like, that's just lazy. But anyway, do you care about that? Because I don't see any of that in like your sample. Yeah, yeah. [00:36:27]
Suhail: The V2 model was mostly focused on image quality versus like the feature of text synthesis. [00:36:33]
Swyx: Well, as a business user, I care a lot about that. [00:36:35]
Suhail: Yeah. Yeah. I'm very excited about text synthesis. And yeah, I think Ideogram has done a good job of maybe the best job. Dolly has like a hit rate. Yes. You know, like sometimes it's Egyptian letters. Yeah. I'm very excited about text synthesis. You know, I don't have much to say on it just yet. You know, you don't want just text effects. I think where this has to go is it has to be like you could like write little tiny pieces of text like on like a milk carton. That's maybe not even the focal point of a scene. I think that's like a very hard task that, you know, if you could do something like that, then there's a lot of other possibilities. Well, you don't have to zero shot it. [00:37:09]
Swyx: You can just be like here and focus on this. [00:37:12]
Suhail: Sure. Yeah, yeah. Definitely. Yeah. [00:37:16]
Swyx: Yeah. So I think text synthesis would be very exciting. I'll also flag that Max Wolf, MiniMaxxier, which you must have come across his work. He's done a lot of stuff about using like logo masks that then map onto food and vegetables. And it looks like text, which can be pretty fun. [00:37:29]
Suhail: That's the wonderful thing about like the open source community is that you get things like control net and then you see all these people do these just amazing things with control net. And then you wonder, I think from our point of view, we sort of go that that's really wonderful. But how do we end up with like a unified model that can do that? What are the bottlenecks? What are the issues? The community ultimately has very limited resources. And so they need these kinds of like workaround research ideas to get there. But yeah. [00:37:55]
Swyx: Are techniques like control net portable to your architecture? [00:37:58]
Suhail: Definitely. Yeah. We kept the Playground V2 exactly the same as SDXL. Not because not out of laziness, but just because we knew that the community already had tools. You know, all you have to do is maybe change a string in your code and then, you know, retrain a control net for it. So it was very intentional to do that. We didn't want to fragment the community with different architectures. Yeah. [00:38:16]
Swyx: So basically, I'm going to go over three more categories. One is UIs, like app UIs, like mock UIs. Third is not safe for work, and then copyrighted stuff. I don't know if you care to comment on any of those. [00:38:28]
Suhail: I think the NSFW kind of like safety stuff is really important. I kind of think that one of the biggest risks kind of going into maybe the U.S. election year will probably be very interrelated with like graphics, audio, video. I think it's going to be very hard to explain, you know, to a family relative who's not kind of in our world. And our world is like sometimes very, you know, we think it's very big, but it's very tiny compared to the rest of the world. Some people like there's still lots of humanity who have no idea what chat GPT is. And I think it's going to be very hard to explain, you know, to your uncle, aunt, whoever, you know, hey, I saw President Biden say this thing on a video, you know, I can't believe, you know, he said that. I think that's going to be a very troubling thing going into the world next year, the year after. [00:39:12]
Swyx: That's more like a risk thing, like deepfakes, faking, political faking. But there's a lot of studies on how for most businesses, you don't want to train on not safe for work images, except that it makes you really good at bodies. [00:39:24]
Suhail: Personally, we filter out NSFW type of images in our data set so that it's, you know, so our safety filter stuff doesn't have to work as hard. [00:39:32]
Swyx: But you've heard this argument that not safe for work images are very good at human anatomy, which you do want to be good at. [00:39:38]
Suhail: It's not like necessarily a bad thing to train on that data. It's more about like how you go and use it. That's why I was kind of talking about safety, you know, in part, because there are very terrible things that can happen in the world. If you have an extremely powerful graphics model, you know, suddenly like you can kind of imagine, you know, now if you can like generate nudes and then there's like you could do very character consistent things with faces, like what does that lead to? Yeah. And so I tend to think more what occurs after that, right? Even if you train on, let's say, you know, new data, if it does something to kind of help, there's nothing wrong with the human anatomy, it's very valid for a model to learn that. But then it's kind of like, how does that get used? And, you know, I won't bring up all of the very, very unsavory, terrible things that we see on a daily basis on the site, but I think it's more about what occurs. And so we, you know, we just recently did like a big sprint on safety. It's very difficult with graphics and art, right? Because there is tasteful art that has nudity, right? They're all over in museums, like, you know, there's very valid situations for that. And then there's the things that are the gray line of that, you know, what I might not find tasteful, someone might be like, that is completely tasteful, right? And then there are things that are way over the line. And then there are things that maybe you or, you know, maybe I would be okay with, but society isn't, you know? So where does that kind of end up on the spectrum of things? I think it's really hard with art. Sometimes even if you have like things that are not nude, if a child goes to your site, scrolls down some images, you know, classrooms of kids, you know, using our product, it's a really difficult problem. And it stretches mostly culture, society, politics, everything. [00:41:14]
Alessio: Another favorite topic of our listeners is UX and AI. And I think you're probably one of the best all-inclusive editors for these things. So you don't just have the prompt, images come out, you pray, and now you do it again. First, you let people pick a seed so they can kind of have semi-repeatable generation. You also have, yeah, you can pick how many images and then you leave all of them in the canvas. And then you have kind of like this box, the generation box, and you can even cross between them and outpaint. There's all these things. How did you get here? You know, most people are kind of like, give me text, I give you image. You know, you're like, these are all the tools for you. [00:41:54]
Suhail: Even though we were trying to make a graphics foundation model, I think we think that we're also trying to like re-imagine like what a graphics editor might look like given the change in technology. So, you know, I don't think we're trying to build Photoshop, but it's the only thing that we could say that people are largely familiar with. Oh, okay, there's Photoshop. What would Photoshop compare itself to pre-computer? I don't know, right? It's like, or kind of like a canvas, but you know, there's these menu options and you can use your mouse. What's a mouse? So I think that we're trying to re-imagine what a graphics editor might look like, not just for the fun of it, but because we kind of have no choice. Like there's this idea in image generation where you can generate images. That's like a super weird thing. What is that in Photoshop, right? You have to wait right now for the time being, but the wait is worth it often for a lot of people because they can't make that with their own skills. So I think it goes back to, you know, how we started the company, which was kind of looking at GPT-3's Playground, that the reason why we're named Playground is a homage to that actually. And, you know, it's like, shouldn't these products be more visual? These prompt boxes are like a terminal window, right? We're kind of at this weird point where it's just like MS-DOS. I remember my mom using MS-DOS and I memorized the keywords, like DIR, LS, all those things, right? It feels a little like we're there, right? Prompt engineering, parentheses to say beautiful or whatever, waits the word token more in the model or whatever. That's like super strange. I think a large portion of humanity would agree that that's not user-friendly, right? So how do we think about the products to be more user-friendly? Well, sure, you know, sure, it would be nice if I wanted to get rid of, like, the headphones on my head, you know, it'd be nice to mask it and then say, you know, can you remove the headphones? You know, if I want to grow, expand the image, you know, how can we make that feel easier without typing lots of words and being really confused? I don't even think we've nailed the UI UX yet. Part of that is because we're still experimenting. And part of that is because the model and the technology is going to get better. And whatever felt like the right UX six months ago is going to feel very broken now. So that's a little bit of how we got there is kind of saying, does everything have to be like a prompt in a box? Or can we do things that make it very intuitive for users? [00:44:03]
Alessio: How do you decide what to give access to? So you have things like an expand prompt, which Dally 3 just does. It doesn't let you decide whether you should or not. [00:44:13]
Swyx: As in, like, rewrites your prompts for you. [00:44:15]
Suhail: Yeah, for that feature, I think once we get it to be cheaper, we'll probably just give it up. We'll probably just give it away. But we also decided something that might be a little bit different. We noticed that most of image generation is just, like, kind of casual. You know, it's in WhatsApp. It's, you know, it's in a Discord bot somewhere with Majorny. It's in ChatGPT. One of the differentiators I think we provide is at the expense of just lots of users necessarily. Mainstream consumers is that we provide as much, like, power and tweakability and configurability as possible. So the only reason why it's a toggle, because we know that users might want to use it and might not want to use it. There's some really powerful power user hobbyists that know what they're doing. And then there's a lot of people that just want something that looks cool, but they don't know how to prompt. And so I think a lot of Playground is more about going after that core user base that, like, knows, has a little bit more savviness and how to use these tools. You know, the average Dell user is probably not going to use ControlNet. They probably don't even know what that is. And so I think that, like, as the models get more powerful, as there's more tooling, hopefully you'll imagine a new sort of AI-first graphics editor that's just as, like, powerful and configurable as Photoshop. And you might have to master a new kind of tool. [00:45:28]
Swyx: There's so many things I could go bounce off of. One, you mentioned about waiting. We have to kind of somewhat address the elephant in the room. Consistency models have been blowing up the past month. How do you think about integrating that? Obviously, there's a lot of other companies also trying to beat you to that space as well. [00:45:44]
Suhail: I think we were the first company to integrate it. Ah, OK. [00:45:47]
Swyx: Yeah. I didn't see your demo. [00:45:49]
Suhail: Oops. Yeah, yeah. Well, we integrated it in a different way. OK. There are, like, 10 companies right now that have kind of tried to do, like, interactive editing, where you can, like, draw on the left side and then you get an image on the right side. We decided to kind of, like, wait and see whether there's, like, true utility on that. We have a different feature that's, like, unique in our product that is called preview rendering. And so you go to the product and you say, you know, we're like, what is the most common use case? The most common use case is you write a prompt and then you get an image. But what's the most annoying thing about that? The most annoying thing is, like, it feels like a slot machine, right? You're like, OK, I'm going to put it in and maybe I'll get something cool. So we did something that seemed a lot simpler, but a lot more relevant to how users already use these products, which is preview rendering. You toggle it on and it will show you a render of the image. And then graphics tools already have this. Like, if you use Cinema 4D or After Effects or something, it's called viewport rendering. And so we try to take something that exists in the real world that has familiarity and say, OK, you're going to get a rough sense of an early preview of this thing. And then when you're ready to generate, we're going to try to be as coherent about that image that you saw. That way, you're not spending so much time just like pulling down the slot machine lever. I think we were the first company to actually ship a quick LCM thing. Yeah, we were very excited about it. So we shipped it very quick. Yeah. [00:47:03]
Swyx: Well, the demos I've been seeing, it's not like a preview necessarily. They're almost using it to animate their generations. Like, because you can kind of move shapes. [00:47:11]
Suhail: Yeah, yeah, they're like doing it. They're animating it. But they're sort of showing, like, if I move a moon, you know, can I? [00:47:17]
Swyx: I don't know. To me, it unlocks video in a way. [00:47:20]
Suhail: Yeah. But the video models are already so much better than that. Yeah. [00:47:23]
Swyx: There's another one, which I think is general ecosystem of Loras, right? Civit is obviously the most popular repository of Loras. How do you think about interacting with that ecosystem? [00:47:34]
Suhail: The guy that did Lora, not the guy that invented Loras, but the person that brought Loras to Stable Diffusion actually works with us on some projects. His name is Simu. Shout out to Simu. And I think Loras are wonderful. Obviously, fine tuning all these Dreambooth models and such, it's just so heavy. And it's obvious in our conversation around styles and vibes, it's very hard to evaluate the artistry of these things. Loras give people this wonderful opportunity to create sub-genres of art. And I think they're amazing. Any graphics tool, any kind of thing that's expressing art has to provide some level of customization to its user base that goes beyond just typing Greg Rakowski in a prompt. We have to give more than that. It's not like users want to type these real artist names. It's that they don't know how else to get an image that looks interesting. They truly want originality and uniqueness. And I think Loras provide that. And they provide it in a very nice, scalable way. I hope that we find something even better than Loras in the long term, because there are still weaknesses to Loras, but I think they do a good job for now. Yeah. [00:48:39]
Swyx: And so you would never compete with Civit? You would just kind of let people import? [00:48:43]
Suhail: Civit's a site where all these things get kind of hosted by the community, right? And so, yeah, we'll often pull down some of the best things there. I think when we have a significantly better model, we will certainly build something that gets closer to that. Again, I go back to saying just I still think this is very nascent. Things are very underpowered, right? Loras are not easy to train. They're easy for an engineer. It sure would be nicer if I could just pick five or six reference images, right? And they might even be five or six different reference images that are not... They're just very different. They communicate a style, but they're actually like... It's like a mood board, right? And you have to be kind of an engineer almost to train these Loras or go to some site and be technically savvy, at least. It seems like it'd be much better if I could say, I love this style. Here are five images and you tell the model, like, this is what I want. And the model gives you something that's very aligned with what your style is, what you're talking about. And it's a style you couldn't even communicate, right? There's no word. You know, if you have a Tron image, it's not just Tron. It's like Tron plus like four or five different weird things. Even cyberpunk can have its like sub-genre, right? But I just think training Loras and doing that is very heavy. So I hope we can do better than that. [00:49:50]
Alessio: We have Sharif from Lexica on the podcast before. Both of you have like a landing page with just a bunch of images where you can like explore things. [00:50:01]
Suhail: Yeah, we have a feed. [00:50:02]
Alessio: Yeah, is that something you see more and more often in terms of like coming up with these styles? Is that why you have that as the starting point versus a lot of other products you just go in, you have the generation prompt, you don't see a lot of examples. [00:50:14]
Suhail: Our feed is a little different than their feed. Our feed is more about community. So we have kind of like a Reddit thing going on where it's a kind of a competition like every day, loose competition, mostly fun competition of like making things. And there's just this wonderful community of people where they're liking each other's images and just showing their like genuine interest in each other. And I think we definitely learn about styles that way. One of the funniest polls, if you go to the mid-journey polls, they'll sometimes put these polls out and they'll say, you know, what do you wish you could like learn more from? And like one of the things that people vote the most for is like learning how to prompt, right? And so I think like if you put away your research hat for a minute and you just put on like your product hat for a second, you're kind of like, well, why do people want to learn how to prompt, right? It's because they want to get higher quality images. Well, what's higher quality? Composition, lighting, aesthetics, so on and so forth. And I think that the community on our feed, I think we might have the biggest community. And it gives all of the users a way to learn how to prompt because they're just seeing this huge rising tide of all these images that are super cool and interesting. And they can kind of like take each other's prompts and like kind of learn how to do that. I think that'll be short-lived because I think the complexity of these things is going to get higher. But that's more about why we have that feed, is to help each other, help teach users and then also just celebrate people's art. You run your own infra. We do. [00:51:30]
Swyx: Yeah, that's unusual. [00:51:31]
Suhail: It's necessary. It's necessary. [00:51:35]
Swyx: What have you learned running DevOps for GPUs? You had a tweet about like how many A100s you have, but I feel like it's out of date probably. [00:51:42]
Suhail: I mean, it just comes down to cost. These things are very expensive. So we just want to make it as affordable for everybody as possible. I find the DevOps for inference to be relatively easy. It doesn't feel that different than, you know, I think we had thousands and thousands of servers at Mixpanel just for dealing with the API. It had such huge quantities of volume that I don't find it particularly very different. I do find model optimization performance is very new to me. So I think that I find that very difficult at the moment. So that's very interesting. But scaling inference is not terrible. Scaling a training cluster is much, much harder than I perhaps anticipated. Why is that? Well, it's just like a very large distributed system with, you know, if you have like a node that goes down, then your training running crashes and then you have to somehow be resilient to that. And I would say training infra software is very early. It feels very broken. I can tell in 10 years it would be a lot better. [00:52:37]
Swyx: Like a mosaic or whatever. [00:52:39]
Suhail: Yeah, we don't even know. We don't think we use very basic tools like, you know, Slurm for scheduling and just normal PyTorch, PyTorch Lightning, that kind of thing. I think our tooling is nascent. I think I talked to a friend that's over at XAI. They just built their own scheduler, you know, and doing things with Kubernetes. Like when people are building out tools because the existing open source stuff doesn't work and everyone's doing their own bespoke thing, you know, there's a valuable company to be formed. [00:53:01]
Swyx: Yeah, I think it's mosaic. [00:53:03]
Suhail: I don't know. It might be worth like wondering like why not everyone is going to mosaic and perhaps it's still, I just think it's nascent and perhaps mosaic will come through. [00:53:12]
Alessio: Just to wrap, we talked about some of the pivotal moments in your mind with like DALI and whatnot. If you were not doing this, what's the most interesting unsolved question in AI that you would try and build in? [00:53:25]
Suhail: Oh man, coming up with startup ideas is very hard on the spot. You have to have them. [00:53:31]
Swyx: I mean, you're a founder, you're a repeat founder. I'm very picky about my startup ideas. [00:53:35]
Suhail: I don't have an idea per se as much as a curiosity. Suppose I'll pose it to you guys. Right now we sort of think that a lot of the modalities just kind of feel like they're vision, language, audio, that's roughly it. And somehow all this will like turn into something, it'll be multimodal and then we'll end up with AGI. And I just think that there are probably far more modalities than meets the eye. And it just seems hard for us to see it right now because it's sort of like we have tunnel vision on the moment. [00:54:08]
Swyx: We're just like code, image, audio, video. [00:54:11]
Suhail: Yeah, I think- [00:54:11]
Swyx: Very, very broad categories. [00:54:13]
Suhail: I think we are lacking imagination as a species in this regard. Yeah, I see it. I don't know what company would form as a result of this, but there's some very difficult problems, like a true actual, not a meta world model, but an actual world model that truly maps everything that's going in terms of like physics and fluids and all these various kinds of interactions. And what does that kind of model, like a true physics foundation model of sorts that represents earth. And that in of itself seems very difficult, but we're kind of stuck on like thinking that we can approximate everything with like a word or a token, if you will. You know, I had a dinner last night where we were kind of debating this philosophically. And I think someone said something that I also believe in, which is like at the end of the day, it doesn't really matter that it's like a token or a byte, at the end of the day, it's just like some unit of information that it emits. But I do wonder if there are far more modalities than meets the eye. And if you could create that, what would that company become? What problems could you solve? So I don't know yet, so I don't have a great company for it. I don't know. [00:55:15]
Alessio: Maybe you just inspire somebody to try. [00:55:17]
Suhail: Yeah, hopefully. [00:55:18]
Swyx: My personal response to that is I'm less interested in physics and more interested in people. Like how do I mind upload? Because that is teleportation, that is immortality, that is everything. Yeah. [00:55:29]
Suhail: Rather than trying to create consciousness, could we model our own? Even if it was lossy to some extent, yeah. We won't solve that here. [00:55:35]
Swyx: If I were to take a Bill Gates book trip and had a week, what should I take with me to learn AI? [00:55:42]
Suhail: Oh gosh, you shouldn't take a book. You should just go to YouTube and visit Kaparthy's class. [00:55:49]
Swyx: Zero to Hero. [00:55:50]
Suhail: And just do it, grind through it. [00:55:52]
Swyx: Was that actually the most useful thing for you? [00:55:53]
Suhail: I wish it came out when I started. Wow. Back last year. I was bummed that I didn't get to take it at the beginning, but I did do a few of his classes regardless. Every time I buy a programming book, I never read it. Or an AI book. I always find that just writing code helps cement my internal understanding. Yeah. [00:56:10]
Swyx: So more generally, advice for founders who are not PhDs and are effectively self-taught like you are. Like what should they do? What should they avoid? Same thing that I would advise [00:56:18]
Suhail: if you're programming. Pick a project that seems very exciting to you. You know, it doesn't have to be too serious. And build it and learn every detail of it while you do it. [00:56:27]
Swyx: Should you train? Or can you go far enough not training, just fine-tuning? I would just follow your curiosity. [00:56:32]
Suhail: If what you want to do is something that requires fundamental understanding of training models, then you should learn it. You don't have to get to become a five-year, whatever, PhD. But if that's necessary, I would do it. If it's not necessary, then go as far as you need to go. But I would learn, pick something that motivates. I think most people tap out on motivation, but they're deeply curious. Cool. [00:56:51]
Alessio: Thank you so much for coming out, man. [00:56:53]
Suhail: Thank you for having me. Appreciate it. [00:57:07]
Lexica also has their own text-to-image model, Aperture, which is now at v3.5.