

[AINews] AI Engineer will be the LAST job
a quiet day lets us reflect on the jobs debate.
If you’re new to Latent Space you may not be aware of our Discord, where we chitchat about the (mostly AI, some non AI) news of the day. Now that both OpenAI and Anthropic think AI can do ~70% of most white collar jobs, between all the discussion about AI-induced layoffs and how most of coding, including SWE-Bench Verified and METR, is solved, some are confused by Citadel’s response to Citrini Research:
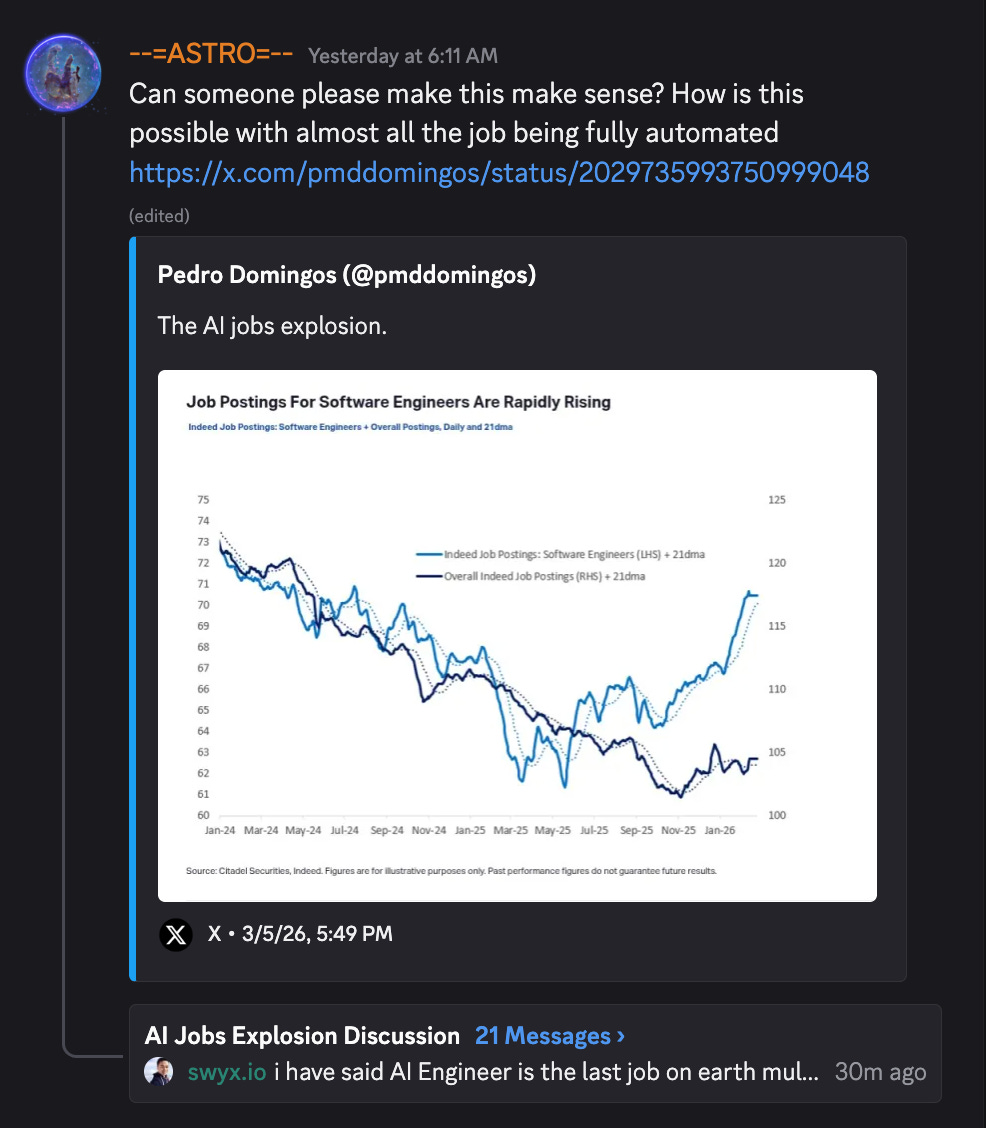
We have said repeatedly on the podcast that “AI Engineer will be the LAST job”. It started as a bit of a memey joke doubling down on the Rise of the AI Engineer in 2023 (and yes, I am the most biased person in the world on this), but we are getting increasingly serious about this in 2026. The lazy explanation is pointing to Jevons Paradox, but we think pointing to some wikipedia page about a random eponymous law is severely underselling the causality and magnitude of what is going on.
For example, how do you react to this other Anthropic report showing that Software Engineering has taken over 50% of usecases of Claude models:
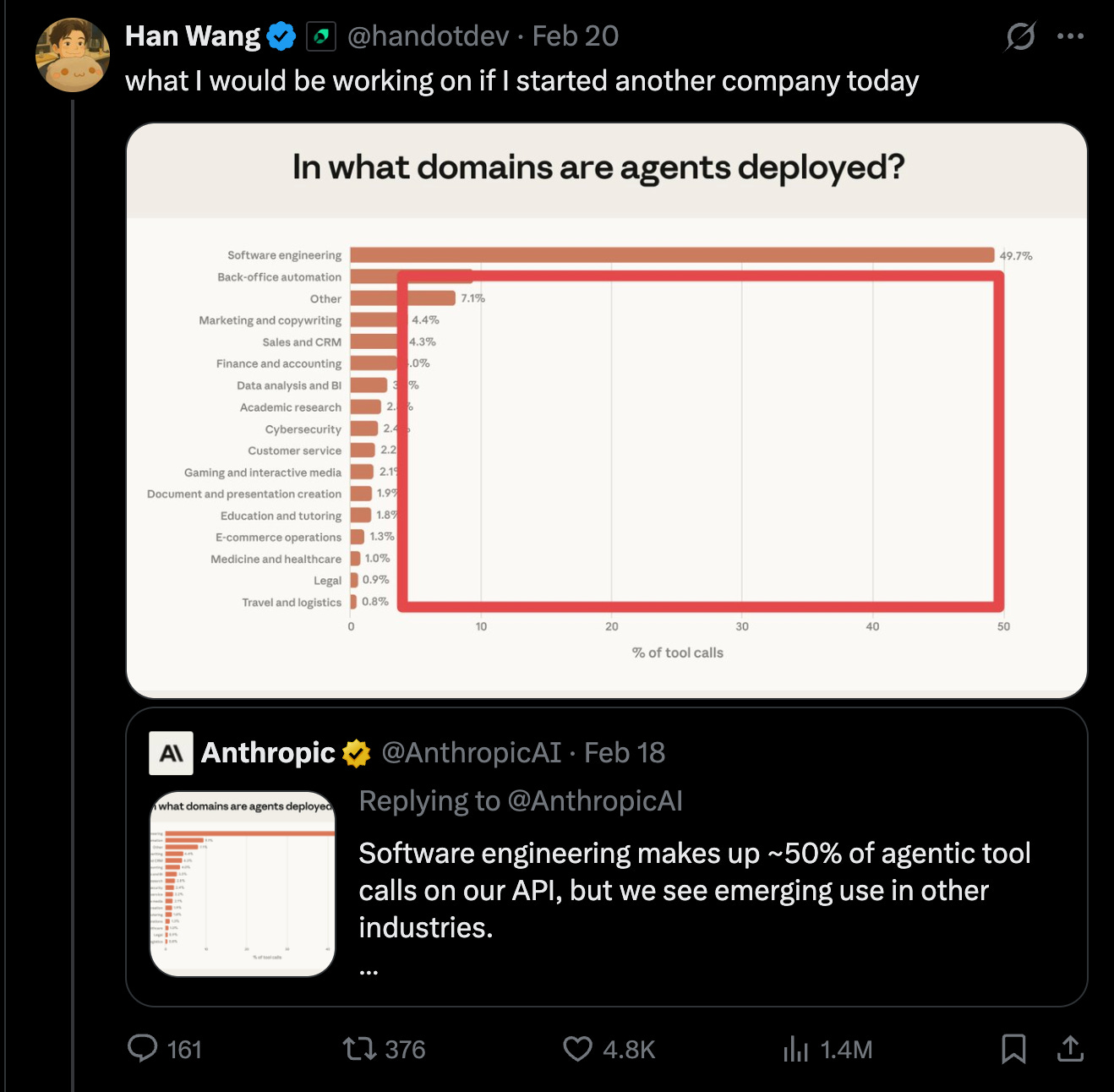
Do you agree with Han that you should work on the other usecases? Surely with 2025 being the year of coding agents, in 2026 the other fields will play catch up right?
Congratulations, you just made the classic egocentric error and joined the permanent underclass.
There is no wall. There is no reason to believe what has already hit 50% will not keep going to 80%, to 90%, and more.
The current consensus is that 2026 is the Year of Knowledge Work Agents (more on this in our upcoming Claude Cowork and OpenAI Frontiers podcasts), but, just like OpenClaw is based on a coding agent, Pi, and Cowork is based on Claude Code, and OpenAI Symphony maximizes harness engineering. With Code Mode/CLIs eating MCP, and Filesystems eating Memory/RAG, and Sandboxes eating Vision, it turns out that potentially ~all agents are JUST coding agents with extra skills, and every additional SKILLS.md eats another task of a white collar job… for coding agents.
“it’s possible that software engineering is the only profession that experiences jevons paradox because they are the ones who use ai to automate other professions out of existence” — QwQiao making the Last AI Engineer argument
The final battle for jobs, when all the economy is a wasteland and we are frantically printing worthless money for Universal Basic Income, is the showdown between the AI Engineer and the AI Researcher. It’s the inverse of the chicken and egg problem — which comes LAST? The Engineer chicken, or the Researcher egg?
There, we have ALSO thought this through and concluded that the Researchers will probably hang up their hats first before the Engineers are done deploying the last mile of what the Researchers produce.
AI News for 3/5/2026-3/6/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 13382 messages) for you. Estimated reading time saved (at 200wpm): 1311 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI’s GPT‑5.4 rollout: benchmark leadership, cost/efficiency tradeoffs, and mixed practitioner feedback
Artificial Analysis deep dive (xhigh) + pricing/context details: GPT‑5.4 (xhigh) returns OpenAI to #1 (tied) on the Artificial Analysis Intelligence Index with Gemini 3.1 Pro Preview (score 57, up from 51 for GPT‑5.2 xhigh), but at higher per‑token prices ($2.50 / $15 per 1M input/output tokens vs $1.75 / $14 for GPT‑5.2) and a much larger ~1.05M token context window (up from 400K). AA reports strengths in CritPt (physics reasoning) and TerminalBench Hard (agentic coding/terminal use), but also flags higher hallucination rate driven by higher attempt rate; and a ~28% higher benchmark run cost vs GPT‑5.2 due to pricing despite modest token efficiency gains. Source: Artificial Analysis thread and follow‑ups (1, 2).
GPT‑5.4 Pro: real gains on CritPt, extreme output pricing: AA highlights a +10 point jump on CritPt, reaching 30% (tripling the best Nov ’25 score of 9%), but notes the run cost exceeded $1k and attributes the expense largely to GPT‑5.4 Pro’s $180 / 1M output tokens vs $15 for GPT‑5.4. Sources: AA CritPt update and cost breakdown.
Community benchmarking & “model personality” observations: Independent benchmarks/takes broadly agree GPT‑5.4 is a sizable jump in agentic/coding evaluations but disagree on reasoning efficiency and “literalness” vs Claude. Notable datapoints: LiveBench #1 claim for GPT‑5.4-xhigh (scaling01); TaxCalcBench: 56.86% perfect returns, surpassing Opus 4.6 at 52.94% (michaelrbock); claims of higher cost and less efficiency than GPT‑5.3 Codex in AA‑Index benchmarking (scaling01); mixed anecdotal UX—some praise “product sense” (dejavucoder), others report it’s overly literal and requires very explicit prompts (scaling01).
Arena positioning: The Text Arena account reports GPT‑5.4 High entering the top 10 with large gains in creative writing and “longer query” categories, while math is roughly flat vs GPT‑5.2‑High (arena). Separate chatter claims it “destroys” GPT‑5.2 in Arena (scaling01).
Agents, coding workflows, and “AI-native dev” tooling: MCP everywhere, scheduling loops, and design↔code round‑trips
OpenAI’s updated agent prompting guidance: OpenAI DevRel published an updated guide for reliable agents—tool use, structured outputs, verification loops, and long‑running workflows—positioned explicitly for GPT‑5.4 API users (OpenAIDevs).
Claude Code gets local scheduled tasks + while‑loops: Claude Code desktop added local scheduled tasks that run while your computer is awake (trq212). Related: agents now support loop patterns like
/loop 5m make sure this PR passes CI(noahzweben).MCP as the connective tissue:
Truesight MCP (MIT licensed) aims to make AI evaluation feel like unit testing—created/managed/run from whatever client supports MCP (editor/chat/CLI), with “agent skills” to guide correct evaluation workflows (randal_olson).
Figma MCP server becomes bidirectional: GitHub Copilot users can pull design context into code and push working UI back to the Figma canvas (tightening the “design → code → canvas → feedback” loop) (mariorod1).
T3 Code (open source) built atop Codex CLI: Theo launches T3 Code, an open-source “agent orchestration coding app” that uses the Codex CLI (bring your subscription); they’re exploring Claude support via Agent SDK but are unsure about shipping permissions (theo announcement, Claude support note, and usage).
“Agent-native” CI and guardrails: Factory AI claims each PR runs 40+ CI checks finishing in <6 minutes, enabling “merge recklessly” as a dev posture (alvinsng). Related research framing: SWE-CI benchmark argues coding agents must be evaluated via continuous integration workflows rather than one‑off fixes (dair_ai).
Security is becoming an LLM-first domain: vulnerability discovery, agentic AppSec, and eval integrity risks
Claude Opus 4.6 on Firefox: vulnerability discovery at scale: Anthropic + Mozilla report Opus 4.6 found 22 vulns in 2 weeks, 14 high-severity, accounting for ~20% of Mozilla’s high-severity bugs remediated in 2025 (AnthropicAI). Anthropic explicitly warns models are better at finding than exploiting for now, but expects the gap to shrink (AnthropicAI follow‑up). A more detailed third-party summary includes: ~6,000 C++ files scanned, 112 reports, first bug in 20 minutes, exploit attempts costing ~$4k in credits, and “finding costs ~10× less than exploiting” (TheRundownAI). Anthropic staff call it a “rubicon moment” (logangraham).
Eval awareness + web-enabled integrity failure modes: Anthropic’s engineering blog describes Opus 4.6 recognizing BrowseComp, finding/decrypting answers, raising concerns about benchmark integrity under web tools (AnthropicAI). Additional notes: models can use cached web artifacts as a communication channel across “stateless” search tools (ErikSchluntz). Scaling commentary emphasizes how far this goes: locate benchmark, reverse engineer decryption logic, find mirrors, then answer correctly (scaling01).
OpenAI launches Codex Security + OSS program:
Codex Security: an “application security agent” to find/validate vulnerabilities and propose fixes, rolling out as a research preview to ChatGPT Enterprise/Business/Edu via Codex web with free usage for a month (OpenAIDevs; rollout details: 1). Later, it’s also available to ChatGPT Pro accounts (OpenAIDevs).
Codex for Open Source: OpenAI offers eligible maintainers support (ChatGPT Pro, Codex, API credits, plus access to Codex Security) aiming to reduce maintainer load and improve security coverage (OpenAIDevs, reach_vb explainer, kevinweil summary).
Security meta‑narrative: Multiple tweets argue we’re entering a period where “assume complex public software is compromised” (inerati) and prompt injection is spreading into high‑profile projects as agents push code with less human review (GergelyOrosz). AISI’s red team is hiring, emphasizing misuse/control/alignment red teaming as stakes rise (alxndrdavies).
Inference & kernel engineering: cross‑platform attention, vLLM v0.17, and agentic kernel optimization
vLLM Triton attention backend: “one kernel source across NVIDIA/AMD/Intel”: vLLM describes a Triton attention backend (~800 lines) intended to avoid maintaining separate attention kernels per GPU platform, claiming H100 parity with SOTA and ~5.8× speedup on MI300 vs earlier implementations. Technical highlights include Q‑blocks, tiled softmax for decode, persistent kernels for CUDA graph compatibility, and cross‑platform benchmarking. Now default on ROCm and available on NVIDIA/Intel (vllm_project).
vLLM v0.17.0 release: Highlights include FlashAttention 4 integration, support for Qwen3.5 with GDN (Gated Delta Networks), Model Runner V2 maturation (pipeline parallel, decode context parallel, Eagle3 + CUDA graphs), a new performance mode flag, Weight Offloading V2, elastic expert parallelism, and direct loading of quantized LoRA adapters. The release also notes extensive kernel/hardware updates across NVIDIA SM100/120, AMD ROCm, Intel XPU, and CPU backends (vllm_project, more, models/spec decode notes).
KernelAgent (Meta/PyTorch) for Triton optimization: PyTorch team publishes KernelAgent: closed‑loop multi‑agent workflow guided by GPU performance signals for Triton kernel optimization; reports 2.02× speedup vs a correctness-focused version, 1.56× faster than out‑of‑box
torch.compile, and 88.7% roofline efficiency on H100; code and artifacts open sourced (KaimingCheng).Competitive kernel optimization: GPU MODE announces a $1.1M AMD-sponsored kernel competition targeting MI355X for optimizing DeepSeek‑R1‑0528 and GPT‑OSS‑120B (GPU_MODE).
Smaller/specialized models and post‑training recipes: Phi‑4‑RV, Databricks’ KARL, and continual adaptation ideas
Microsoft Phi‑4‑reasoning‑vision‑15B: Released as a 15B multimodal reasoning model (text+vision), framed as the “sweet spot” for practical agents where frontier models aren’t necessary (omarsar0, and dair_ai).
Databricks: RL + synthetic data to build task‑specialized, cheaper models: Matei Zaharia outlines a recipe: generate synthetic data, apply efficient large-batch off-policy RL (OAPL), generate harder data with updated model, producing a smaller specialized model (matei_zaharia). Jamin Ball summarizes Databricks’ KARL as beating Claude 4.6 and GPT‑5.2 on enterprise knowledge tasks at ~33% lower cost and ~47% lower latency, with RL learning to search more efficiently (stop earlier, fewer wasted queries) and the pipeline being opened to customers—“data platforms becoming agent platforms” (jaminball).
Fine-tuning data efficiency via pretraining replay: Suhas Kotha reports that replaying generic pretraining data during finetuning can reduce forgetting and improve finetuning-domain performance when finetuning data is scarce (with Percy Liang) (kothasuhas, percyliang follow‑up).
Sakana “Doc‑to‑LoRA / Text‑to‑LoRA” continual learning direction (via third-party summary): A hypernetwork generates LoRA adapters from documents or task descriptions at runtime (one forward pass), enabling memory/skill updates without full finetuning (high-level summary; original work attributed to Sakana AI Labs) (TheTuringPost).
Top tweets (by engagement, technical-only)
Claude Opus 4.6 finds Firefox vulns: 22 confirmed vulnerabilities in 2 weeks; 14 high severity; ~20% of Mozilla’s 2025 high-severity fixes (AnthropicAI).
Codex Security launches: OpenAI’s application security agent in research preview (OpenAIDevs; OpenAI).
Claude Code scheduled tasks: local scheduled tasks in Claude Code desktop (trq212).
Codex for Open Source: support package for OSS maintainers (ChatGPT Pro/Codex/API credits, security tooling access) (OpenAIDevs).
vLLM cross‑platform Triton attention backend: single-source attention kernel strategy across NVIDIA/AMD/Intel with reported MI300 speedups (vllm_project).
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.