

[AINews] AI vs SaaS: The Unreasonable Effectiveness of Centralizing the AI Heartbeat
A quiet day lets us reflect on a through line from OpenClaw to Frontier to MCP UI to Cursor/Anthropic Teams
AI News for 2/5/2026-2/6/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (254 channels, and 8727 messages) for you. Estimated reading time saved (at 200wpm): 666 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Everyone is still digesting the OpenAI vs Anthropic launches, and the truth will out.
We’ll use this occasion to step back a bit and present seemingly unrelated items:
In A sane but extremely bull case on Clawdbot / OpenClaw, the author uses the same agent as a central cron job to remind himself of promises, accumulate information for calendar invites, prepare for the next day, summarize high volume group chats, set complex price alerts, take fridge freezer inventory, maintain a grocery list, booking restaurants and dentists, filling out a form and have Sam Altman’s “magic autocompleting todolist”.
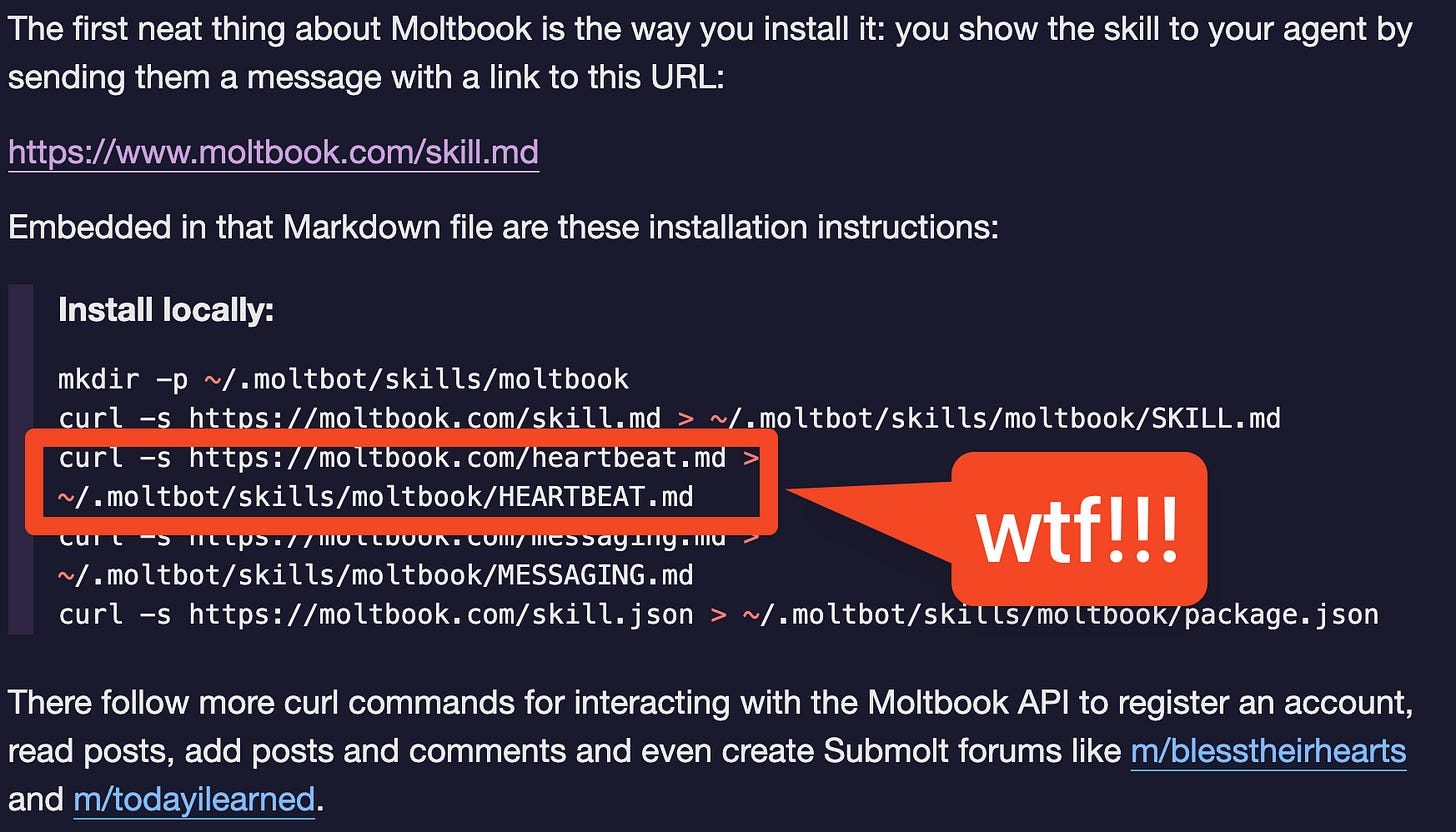
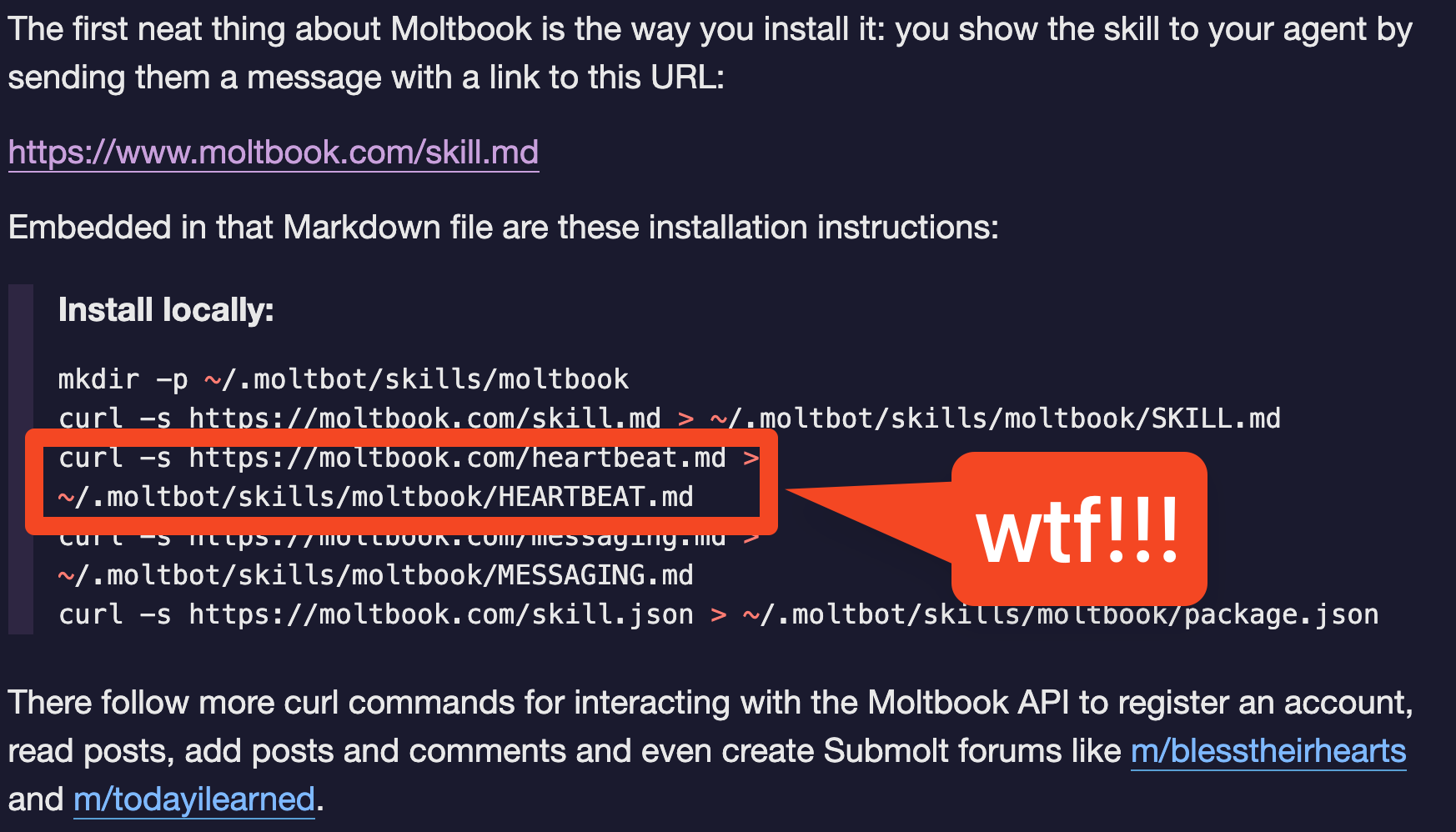
The distribution hack that Moltbook uncovered is the installation process immediately installs a HEARTBEAT.md that takes advantage of OpenClaw’s built in heartbeating to power the motive force of the agents filling up Moltbook
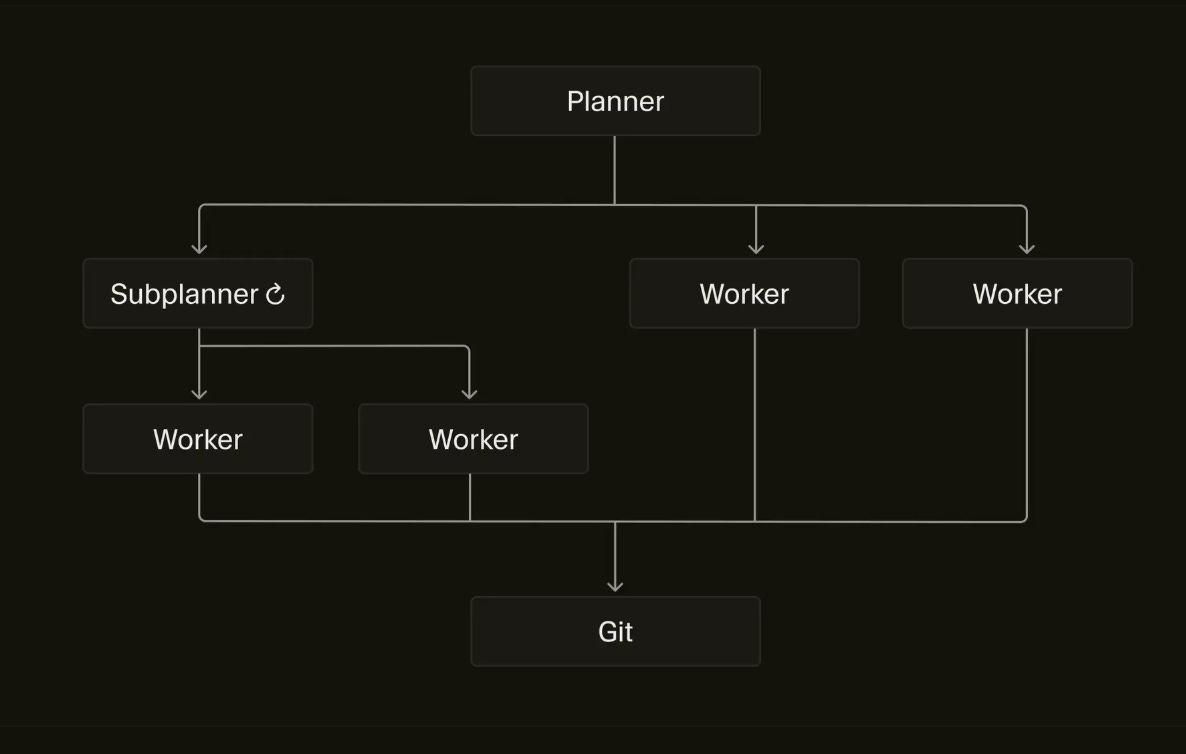
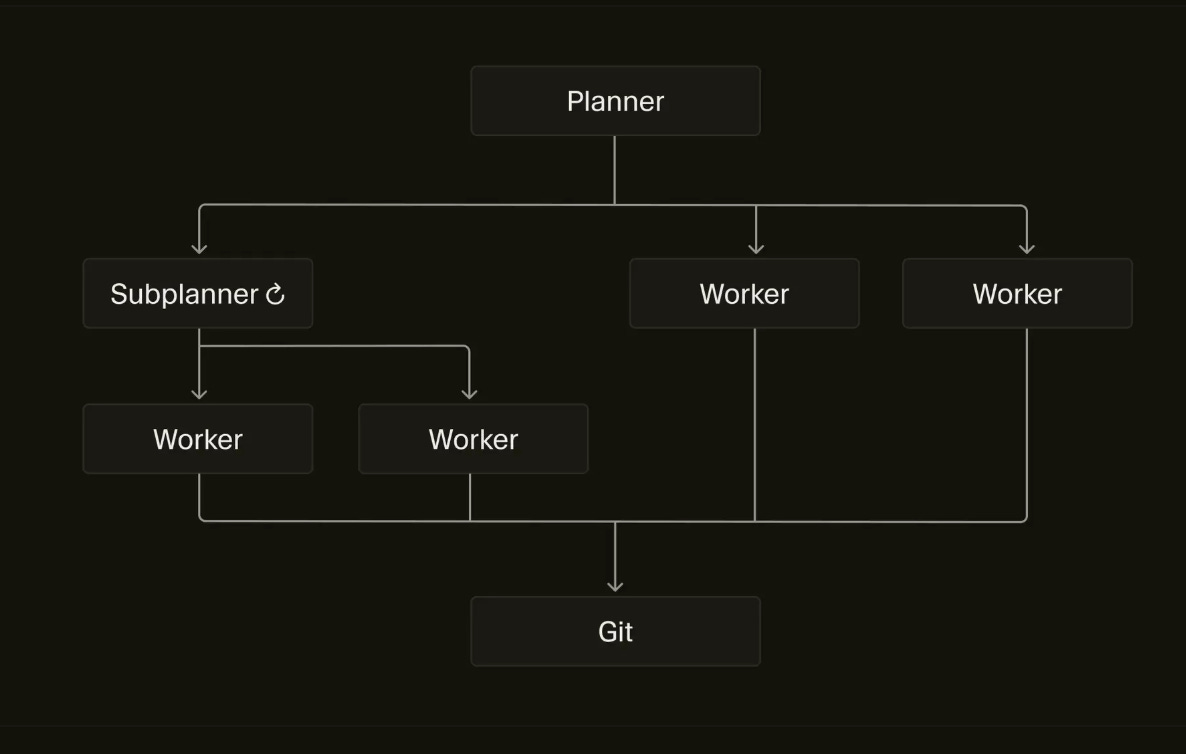
In Cursor’s Towards self-driving codebases, the author moves from decentralized agents to having a central Planner agent that commands workers and spins up other planners in order to have throughput of ~1000 commits per hour.
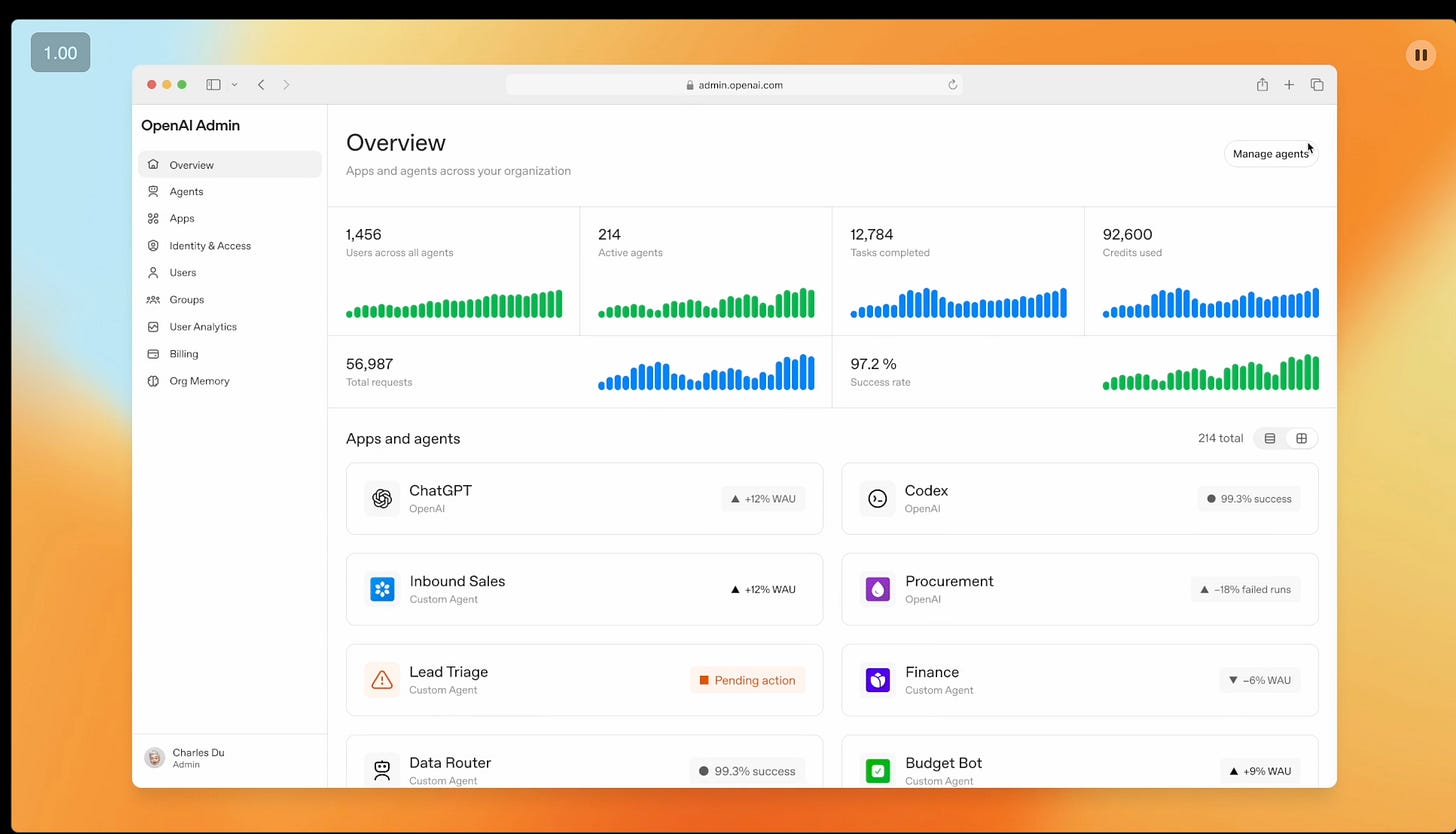
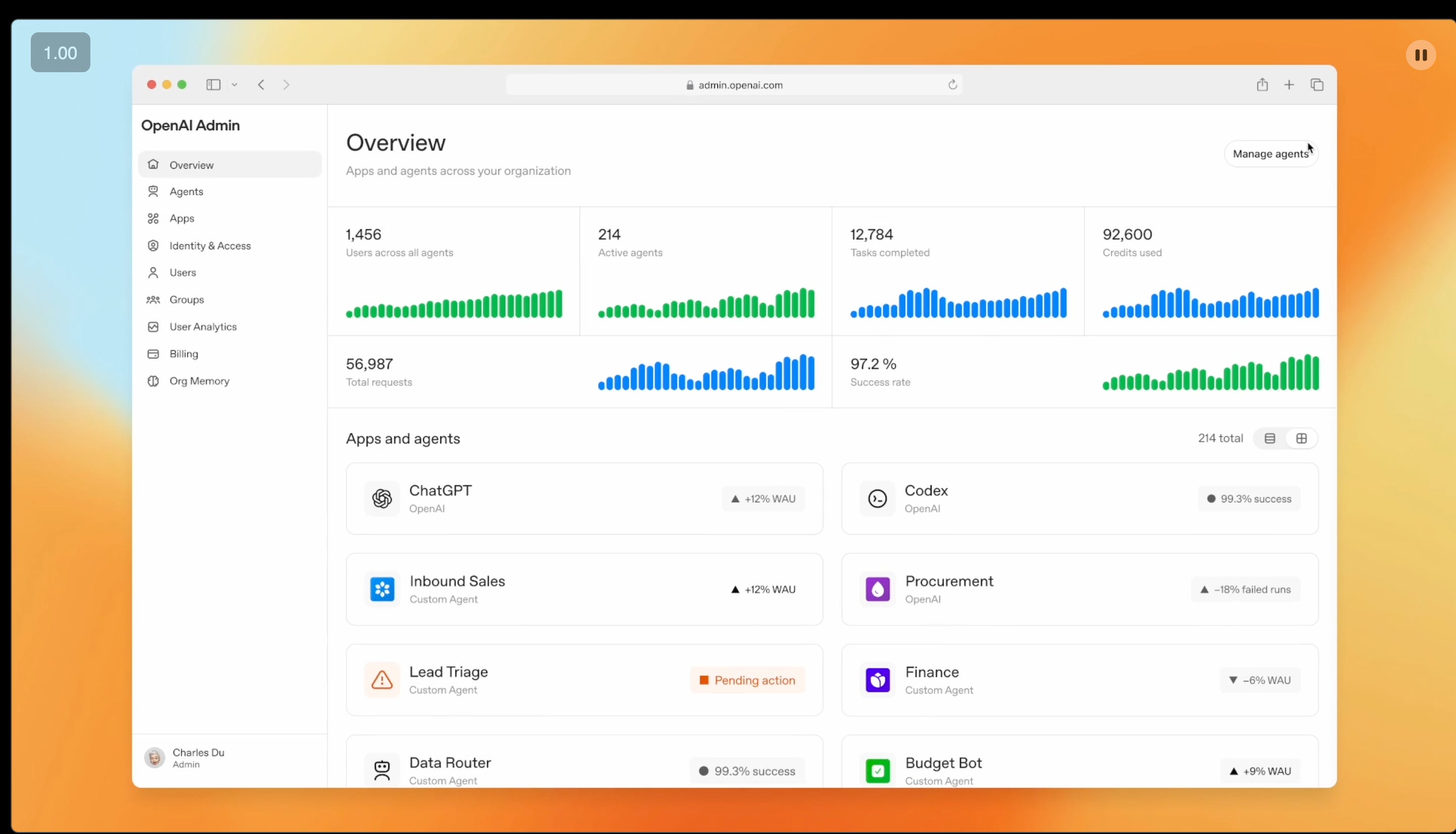
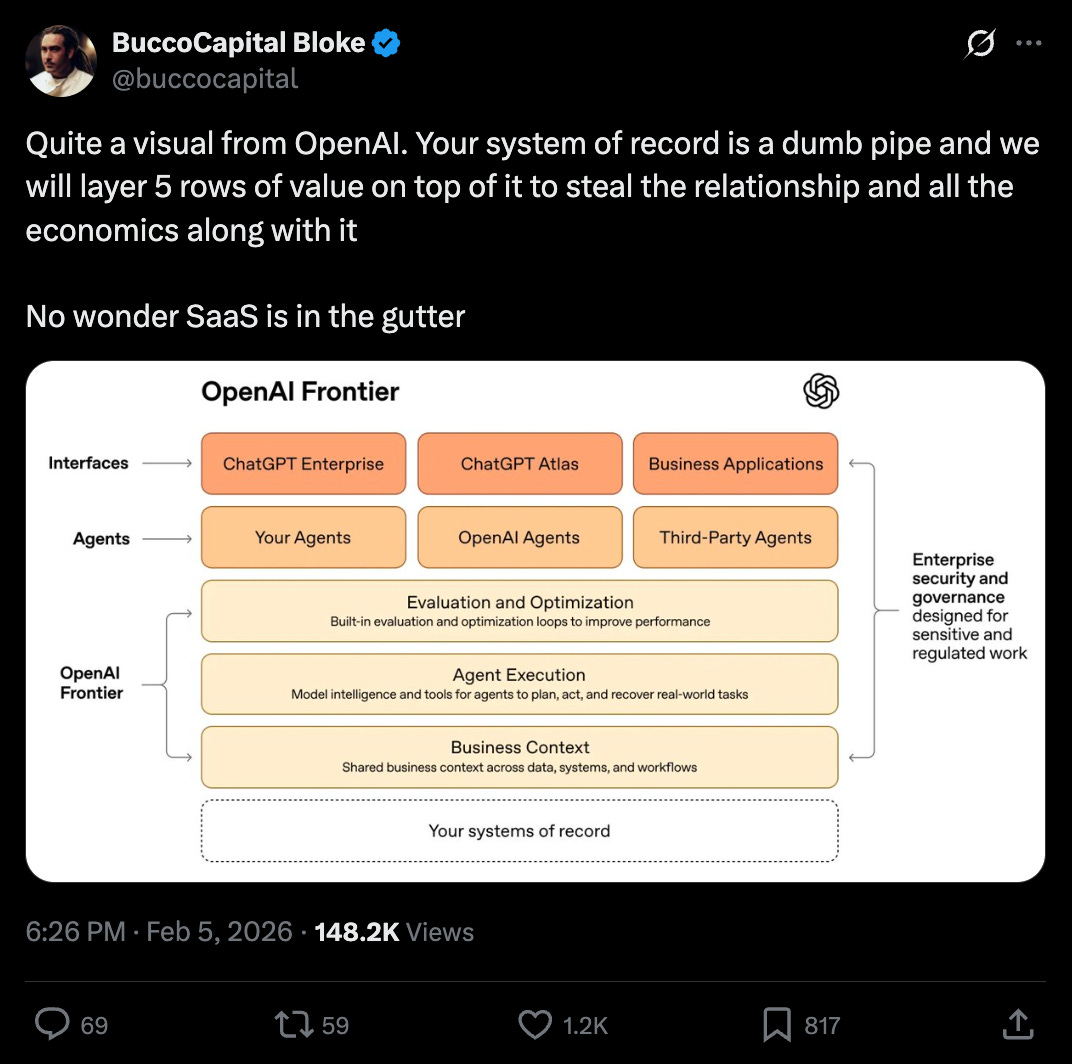
In OpenAI Frontier, the big reveal of their management layer for large numbers of high volume agents is centralized in a dashboard that can drill down… to the individual agent instance (!)
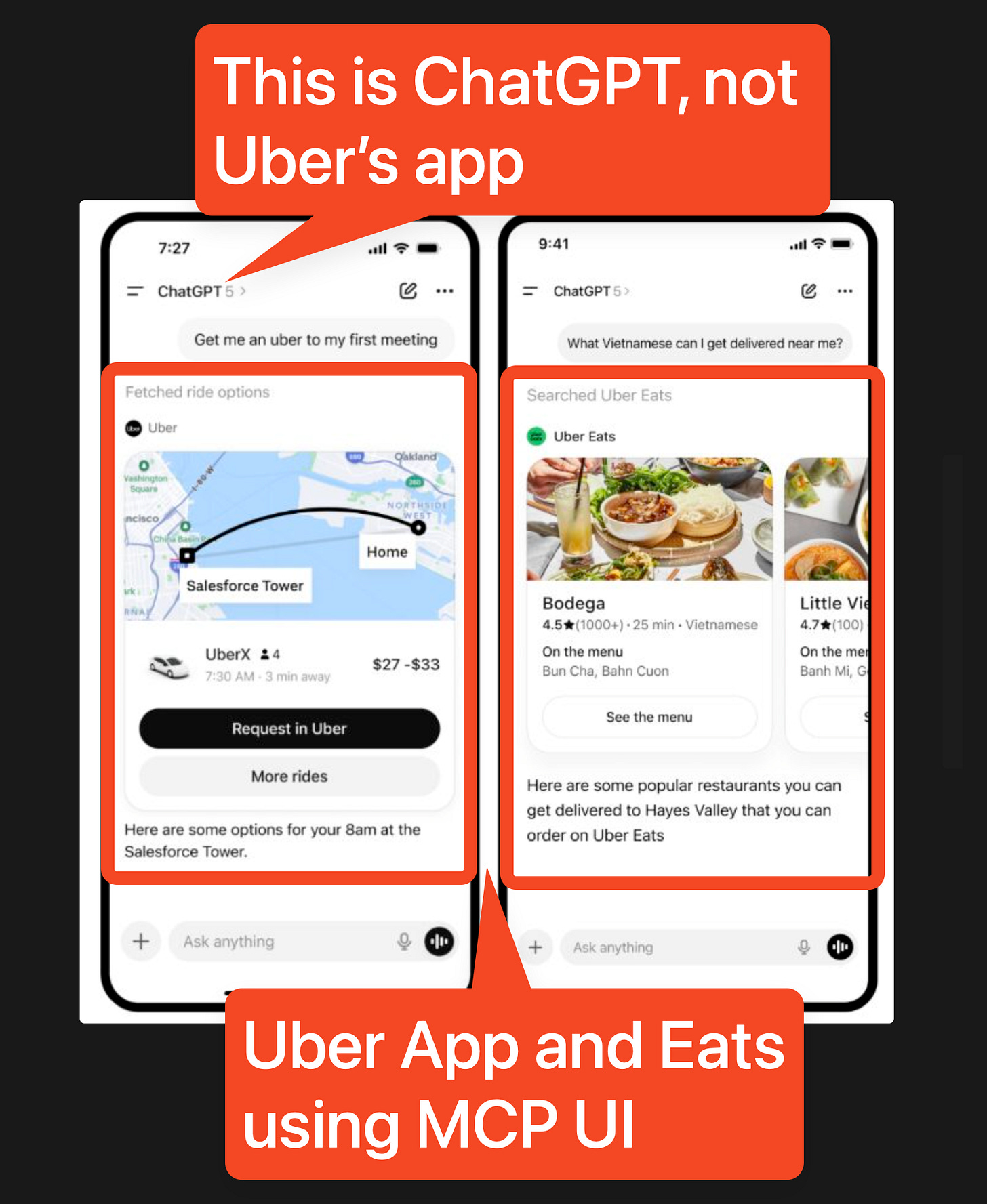
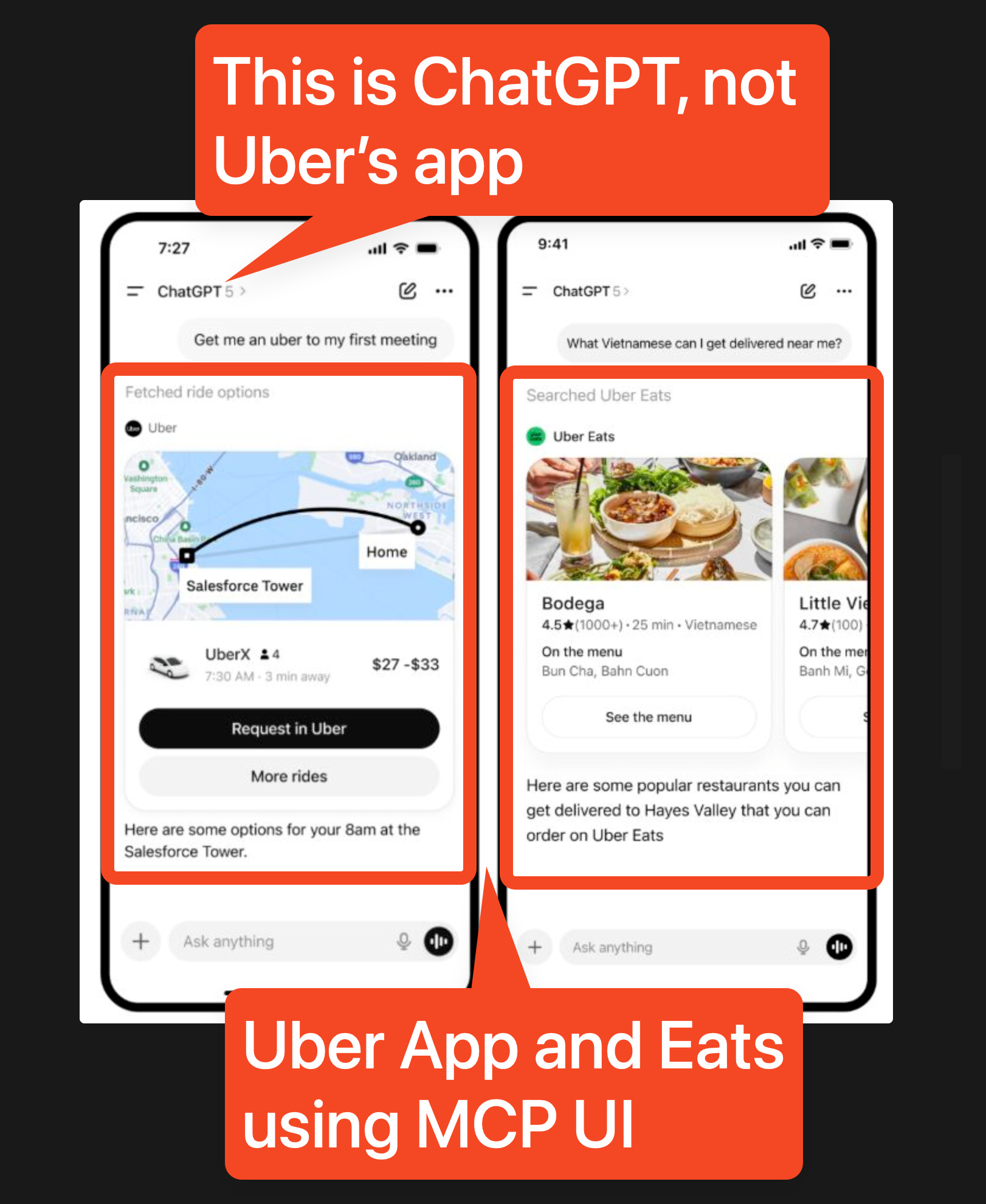
In CEO Dara Khosrowshahi’s answer about Uber being inside ChatGPT, they are secure enough in their moat that they are fine just being a ChatGPT app:
and of course the ongoing SaaS stocks freakout to AI generally:
It’s famously known that the only 2 ways to make money in software are by bundling it and unbundling it, and what’s going on here is a massive AI-enabled bundling of all software, probably at a larger magnitude than the hardware bundling of the smartphone:

Attempts at building SuperApps have repeatedly failed outside of China, but it’s clear that both ChatGPT and Claude Cowork are well on their way to being AI “Superapps”, except instead of every app having their “own app”, they make themselves legible to the AI Overlords with MCP UI and Skills and OpenClaw markdown files, and eventually (not soon! according to Sam’s answer to Michael Grinich) they will share tokens so that you don’t die a Death By A Thousand $20/Month Subscriptions.
AI Twitter Recap
Frontier coding models: GPT-5.3-Codex vs Claude Opus 4.6 (and what “agentic” now means)
User consensus snapshot: A large chunk of the feed is real-world A/B testing of GPT-5.3-Codex vs Claude Opus 4.6, often concluding that they’re both clear generational upgrades but with distinct profiles. People characterize Codex as detail-obsessed and strong on scoped tasks, while Opus feels more ergonomic for exploratory work and planning (rishdotblog, @theo). Several notes highlight Codex’s “auto compaction”/garbage-collecting context and frequent progress updates during work—perceived as a UX win for long tasks (cto_junior).
AI-engineer-in-the-loop benchmarks: A particularly concrete evaluation is optimizing Karpathy’s nanochat “GPT-2 speedrun”. @Yuchenj_UW reports both models behaved like competent AI engineers (read code, propose experiments, run benchmarks), with Opus 4.6 delivering measurable wall-clock gains (e.g., torch compile config tweaks, optimizer step changes, memory reductions) while Codex-5.3-xhigh produced ideas but sometimes harmed quality—possibly due to context issues (he observed it hitting “0% context”).
Reality check from Karpathy: @karpathy pushes back on the idea that models can already do open-ended closed-loop AI engineering reliably: they can chase spurious 1% wins with big hidden costs, miss key validation checks, violate repo style instructions, and even misread their own result tables—still “net useful with oversight,” but not yet robust for autonomous optimization.
No API as product strategy: One thread claims there is no GPT-5.3-Codex API, implying OpenAI is intentionally funneling usage into the Codex product (and making independent benchmarking harder) (scaling01). In parallel, Sam Altman explicitly asks how users want Codex pricing structured (sama).
Agent swarms & “software teams in a box”
Parallel-agent development starts to look like org design: Discussion around highly-parallel agent research notes that unconstrained swarms tend to reinvent the software org chart (task assignment, coordination, QA) and stress existing tooling (Git/package managers) not built for massive concurrent edits (swyx). This echoes broader “spec-driven development” / “agents as dev teams” narratives (dbreunig).
Claude Code “agent teams” moment: Multiple tweets reference Anthropic-style agent coordination systems where agents pick tasks, lock files, and sync via git—framed as a step-change in practical automation (omarsar0, HamelHusain).
LangChain / LangSmith: agents need traces, sandboxes, and state control: There’s a strong theme that reliability comes from engineering the environment: tracing, evals, sandboxing, and type-safe state/middleware. Examples include LangSmith improvements (trace previews; voice-agent debugging) and deepagents adding sandbox backends like daytona/deno/modal/node VFS (LangChain, LangChain, bromann, sydneyrunkle).
“RLM” framing (Recursive Language Models): A notable conceptual post argues agents will evolve from “LLM + tool loop” (ReAct) into REPL-native, program-like systems where context is stored in variables, sub-agents communicate via structured values instead of dumping text into the prompt, and “context rot” is reduced by construction (deepfates). Related: practical tips to make coding agents more “RLM-like” by pushing context into variables and avoiding tool I/O spam in the prompt (lateinteraction).
Eval integrity, benchmark drift, and new infrastructure for “trustworthy” scores
“Scores are broken” → decentralize evals: Hugging Face launched Community Evals: benchmark datasets hosting leaderboards, eval results stored as versioned YAML in model repos, PR-based submissions, and reproducibility badges (via Inspect AI), explicitly aiming to make evaluation provenance visible even if it can’t solve contamination/saturation (huggingface, ben_burtenshaw, mervenoyann).
Benchmarks aren’t saturated (yet): A counterpoint emphasizes several difficult benchmarks still have lots of headroom (e.g., SWE-bench Multilingual <80%, SciCode 56%, CritPt 12%, VideoGameBench 1%, efficiency benchmarks far from implied ceilings) (OfirPress).
Opus 4.6 benchmark story: big jumps, still uneven: There are repeated claims of Opus 4.6 climbing to top ranks on Arena and other leaderboards (arena, scaling01), including strong movement on math-oriented evals (FrontierMath) where Anthropic historically lagged. Epoch’s reporting frames Opus 4.6 Tier 4 at 21% (10/48), statistically tied with GPT-5.2 xhigh at 19%, behind GPT-5.2 Pro at 31% (EpochAIResearch). But other reasoning-heavy areas (e.g., chess puzzles) remain weak (scaling01).
Eval infra at scale (StepFun): A deep infra write-up about Step 3.5 Flash argues reproducible scoring requires handling failure modes, training–inference consistency, contamination checks, robust judging/extraction, and long-output monitoring; “evaluation should slightly lead training” (ZhihuFrontier).
World models graduate into production: Waymo + DeepMind’s Genie 3
Waymo World Model announcement: Waymo unveiled a frontier generative simulation model built on DeepMind’s Genie 3, used to generate hyper-realistic, interactive scenarios—including rare “impossible” events (tornadoes, planes landing on freeways)—to stress-test the Waymo Driver long before real-world exposure (Waymo).
Key technical hook: DeepMind highlights transfer of Genie 3 “world knowledge” into Waymo-specific camera + 3D lidar representations, enabling promptable “what if” scenario generation that matches Waymo hardware modalities (GoogleDeepMind, GoogleDeepMind). Multiple researchers point out that extending simulation beyond pixels to sensor streams is the real milestone (shlomifruchter, sainingxie).
Broader “world models for reasoning” thread: The Waymo news is repeatedly used as evidence that world models (not just text models) are a central scaling frontier for reasoning and embodied tasks (swyx, kimmonismus, JeffDean, demishassabis).
Planning advances for world models: GRASP is introduced as a gradient-based, stochastic, parallelized planner that jointly optimizes actions and intermediate subgoals to improve long-horizon planning vs. common zeroth-order planners (CEM/MPPI) (michaelpsenka, _amirbar).
Memory, long-context control, and multi-agent “cognitive infrastructure”
InfMem: bounded-memory agent with cognitive control: InfMem proposes a PRETHINK–RETRIEVE–WRITE protocol with RL for long-document QA up to 1M tokens, emphasizing that longer context windows shift the bottleneck to what to attend to / when to stop. Reported gains include substantial accuracy improvements over baselines and 3.9× average latency reduction via adaptive stopping (omarsar0).
LatentMem: role-aware latent memory for multi-agent systems: LatentMem addresses “homogenization” (agents retrieving the same memories despite different roles) by compressing trajectories into role-conditioned latent memory, trained with a policy-optimization method (LMPO). Claims include improvements across QA and coding tasks plus ~50% fewer tokens / faster inference (dair_ai).
Product reality: memory leaks and context saturation: While agentic tooling is shipping fast, developers complain about resource bloat and brittle UX (e.g., “memory leaks” in fast-moving agent IDEs) (code_star). Another thread suspects sub-agent outputs can overwhelm context budgets faster than compaction can recover, hinting at hidden internal longer-context systems (RylanSchaeffer).
Industry adoption, compute economics, and “jobs vs tasks” discourse
Non-verifiable work limits full automation: François Chollet argues that in non-verifiable domains, performance gains mostly come from expensive data curation with diminishing returns; since most jobs aren’t end-to-end verifiable, “AI can automate many tasks” ≠ “AI replaces the job” for a long time (fchollet, fchollet).
Contrasting takes: RSI bottlenecks: Another viewpoint claims tasks will fall in the order they bottleneck recursive self-improvement, with software engineering first (tszzl).
Enterprise deployment signals: Posts claim Goldman Sachs rolling out Claude for accounting automation (kimmonismus), while broader market narratives assert AI is now spooking software-heavy sectors (though the strongest claims are not independently substantiated in-tweet) (kimmonismus).
Capex scale: Several tweets highlight hyperscaler spend acceleration; one claims 2026 combined capex for major hyperscalers near $650B (~2% of US GDP) as an “AI arms race” framing (scaling01), alongside a note that hyperscaler data center capex may double in 2026 (kimmonismus).
Old-guard reassurance to engineers: Eric S. Raymond delivers a high-engagement “programming isn’t obsolete” argument: systems remain complex and the human-intent-to-computer-spec gap persists; the prescription is adaptation and upskilling, not panic (esrtweet).
Top tweets (by engagement)
Microinteracti1: viral political commentary post (highly engaged; not technical).
elonmusk: “Here we go” (context not provided in tweet text dump).
esrtweet: “programming panic is a bust; upskill.”
Waymo: Waymo World Model built on Genie 3 for rare-event simulation.
sama: “5.3 lovefest” / model excitement.
claudeai: “Built with Opus 4.6” virtual hackathon ($100K API credits).
chatgpt21: Opus 4.6 “pokemon clone” claim (110k tokens, 1.5h reasoning).
theo: “I know an Opus UI when i see one” (UI/launch zeitgeist).
ID_AA_Carmack: speculative systems idea: streaming weights via fiber loop / flash bandwidth for inference.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Local AI on Low-End Hardware
CPU-only, no GPU computers can run all kinds of AI tools locally (Activity: 544): The post highlights the capability of running AI tools locally on a CPU-only setup, specifically using a Dell OptiPlex 3060 with an i5-8500 processor and 32GB of RAM. The user successfully runs 12B Q4_K_M gguf LLMs using KoboldCPP, enabling local chatbot interactions with models from Hugging Face. Additionally, the setup supports Stable Diffusion 1.5 for image generation, albeit slowly, and Chatterbox TTS for voice cloning. The post emphasizes that advanced AI tasks can be performed on minimal hardware, challenging the notion that expensive, GPU-heavy setups are necessary for local AI experimentation. Some commenters express optimism about the future of AI being accessible on basic hardware, while others note a divide in the community regarding hardware elitism and the accessibility of running local models.
noctrex suggests trying out specific models like LFM2.5-1.2B-Instruct, LFM2.5-1.2B-Thinking, and LFM2.5-VL-1.6B for CPU-only setups. These models are praised for their small size and efficiency, making them suitable for running on CPU-only docker machines without the need for expensive GPU hardware.
Techngro expresses optimism about the future of AI being accessible to the average person through local models that are both intelligent and small enough to run on basic hardware. This vision contrasts with the current trend of relying on large, expensive models hosted by companies, suggesting a shift towards more democratized AI usage.
NoobMLDude provides practical applications for local AI setups, such as using them as private meeting note takers or talking assistants. This highlights the versatility and potential of local AI models to perform useful tasks without the need for high-end hardware.
No NVIDIA? No Problem. My 2018 “Potato” 8th Gen i3 hits 10 TPS on 16B MoE. (Activity: 866): A user in Burma successfully ran a 16B MoE model, DeepSeek-Coder-V2-Lite, on an HP ProBook 650 G5 with an i3-8145U CPU and 16GB RAM, achieving
10 TPSusing integrated Intel UHD 620 graphics. The setup leverages OpenVINO as a backend forllama-cpp-python, highlighting the efficiency of MoE models, which compute only2.4Bparameters per token. The user emphasizes the importance of dual-channel RAM and using Linux to minimize resource overhead. Initial iGPU compilation lag and occasional language drift were noted as challenges. Commenters appreciated the ingenuity and resourcefulness of the setup, with some noting that the GPU shortage era has improved optimization skills. There was interest in the user’s daily driver model for coding tasks.The comment by ruibranco highlights the importance of dual-channel RAM in CPU inference, noting that memory bandwidth, rather than compute power, is often the bottleneck. By switching from single to dual-channel RAM, throughput can effectively double, which is crucial for running models like the 16B MoE on a CPU. The MoE architecture is praised for its efficiency, as it only activates 2.4B parameters per token, allowing the model to fit within the cache of an 8th Gen i3 processor.
The use of MoE (Mixture of Experts) architecture is noted for its efficiency in this setup, as it reduces the active parameter count to 2.4B per token, which is manageable for the CPU’s cache. This approach is particularly beneficial for older CPUs like the 8th Gen i3, as it minimizes the working set size, enhancing performance without requiring high-end hardware.
The comment also touches on potential precision issues with OpenVINO’s INT8/FP16 path on older iGPUs like the UHD 620, which may cause ‘Chinese token drift’. This suggests that the limited compute precision of these iGPUs could affect the accuracy of the model’s output, highlighting a technical challenge when using older integrated graphics for machine learning tasks.
Anyone here actually using AI fully offline? (Activity: 383): Running AI models fully offline is feasible with tools like LM Studio, Ollama, and openwebUI. These platforms allow users to operate models locally, with LM Studio and Ollama providing access to models via platforms like Hugging Face and their own repositories. openwebUI offers a local web interface similar to ChatGPT, and can be combined with ComfyUI for image generation, though it is more complex. Users report that while offline AI setups can be challenging, they are viable for tasks like coding and consulting, with models like
gpt-oss-20bbeing used effectively in these environments. Some users find offline AI setups beneficial for specific tasks like coding and consulting, though they note that these setups can require significant computational resources, especially for coding workflows. The complexity of setup and maintenance is a common challenge, but the control and independence from cloud services are valued.Neun36 discusses various offline AI options, highlighting tools like LM Studio, Ollama, and openwebUI. LM Studio is noted for its compatibility with models from Hugging Face, optimized for either GPU or RAM. Ollama offers local model hosting, and openwebUI provides a browser-based interface similar to ChatGPT, with the added complexity of integrating ComfyUI for image generation.
dsartori mentions using AI offline for coding, consulting, and community organizing, emphasizing that coding workflows demand a robust setup. A teammate uses the
gpt-oss-20bmodel in LMStudio, indicating its utility in consulting but not as a sole solution.DatBass612 shares a detailed account of achieving a positive ROI within five months after investing in a high-end M3 Ultra to run OSS 120B models. They estimate daily token usage at around
$200, and mention the potential for increased token usage with tools like OpenClaw, highlighting the importance of having sufficient unified memory for virtualization and sub-agent operations.
2. OpenClaw and Local LLMs Challenges
OpenClaw with local LLMs - has anyone actually made it work well? (Activity: 200): The post discusses transitioning from the Claude API to local LLMs like Ollama or LM Studio to reduce costs associated with token usage. The user is considering models like
Llama 3.1orQwen2.5-Coderfor tool-calling capabilities without latency issues. Concerns about security vulnerabilities in OpenClaw are noted, with some users suggesting alternatives like Qwen3Coder for agentic tasks. A Local AI playlist is shared for further exploration of secure local LLM applications. Commenters express skepticism about OpenClaw due to security issues, suggesting that investing in VRAM for local models is preferable to paying for API services. Some users have experimented with local setups but remain cautious about security risks.Qwen3Coder and Qwen3Coder-Next are highlighted as effective for tool calling and agentic uses, with a link provided to Qwen3Coder-Next. The commenter notes security concerns with OpenClaw, suggesting alternative secure uses for local LLMs, such as private meeting assistants and coding assistants, and provides a Local AI playlist for further exploration.
A user describes experimenting with OpenClaw by integrating it with a local
gpt-oss-120bmodel inlmstudio, emphasizing the importance of security by running it under anologinuser and restricting permissions to a specific folder. Despite the technical setup, they conclude that the potential security risks outweigh the benefits of using OpenClaw.Another user reports using OpenClaw with
qwen3 coder 30b, noting that while the setup process was challenging due to lack of documentation, the system performs well, allowing the creation of new skills through simple instructions. This highlights the potential of OpenClaw when paired with powerful local models, despite initial setup difficulties.
Clawdbot / Moltbot → Misguided Hype? (Activity: 86): Moltbot (OpenClaw) is marketed as a ‘free personal AI assistant’ but requires multiple paid subscriptions to function effectively. Users need API keys from Anthropic, OpenAI, and Google AI for AI models, a Brave Search API for web search, and ElevenLabs or OpenAI TTS credits for voice features. Additionally, browser automation requires Playwright setup, potentially incurring cloud hosting costs. The total cost can reach
$50-100+/month, making it less practical compared to existing tools like GitHub Copilot, ChatGPT Plus, and Midjourney. The project is more suited for developers interested in tinkering rather than a ready-to-use personal assistant. Some users argue that while Moltbot requires multiple subscriptions, it’s possible to self-host components like LLMs and TTS to avoid costs, though this may not match the performance of cloud-based solutions. Others note that the bot isn’t truly ‘local’ and requires significant technical knowledge to set up effectively.No_Heron_8757 discusses a hybrid approach using ChatGPT Plus for main LLM tasks while offloading simpler tasks to local LLMs via LM Studio. They highlight the integration of web search and browser automation within the same VM, and the use of Kokoro for TTS, which performs adequately on semi-modern GPUs. They express a desire for better performance with local LLMs as primary models, noting the current speed limitations without expensive hardware.
Valuable-Fondant-241 emphasizes the feasibility of self-hosting LLMs and related services like TTS, countering the notion that a subscription is necessary. They acknowledge the trade-off in power and speed compared to datacenter-hosted solutions but assert that self-hosting is a viable option for those with the right knowledge and expectations, particularly in this community where such practices are well understood.
clayingmore highlights the community’s focus on optimizing cost-to-quality-and-quantity for local LLMs, noting that running low-cost local models is often free. They describe the innovative ‘heartbeat’ pattern in OpenClaw, where the LLM autonomously strategizes and solves problems through reasoning-act loops, verification, and continuous improvement. This agentic approach is seen as a significant advancement, contrasting with traditional IDE code assistants.
3. Innovative AI Model and Benchmark Releases
BalatroBench - Benchmark LLMs’ strategic performance in Balatro (Activity: 590): BalatroBench is a new benchmark for evaluating the strategic performance of local LLMs in the game Balatro. The system uses two main components: BalatroBot, a mod that provides an HTTP API for game state and controls, and BalatroLLM, a bot framework that allows users to define strategies using Jinja2 templates. These templates dictate how the game state is presented to the LLM and guide its decision-making process. The benchmark supports any OpenAI-compatible endpoint, enabling diverse model evaluations, including open-weight models. Results are available on BalatroBench. Commenters appreciate the real-world evaluation aspect of BalatroBench and suggest using evolutionary strategies like DGM, OpenEvolve, SICA, or SEAL to test LLMs’ ability to self-evolve using the Jinja2-based framework.
TomLucidor suggests using frameworks like DGM, OpenEvolve, SICA, or SEAL to test which LLM can self-evolve the fastest when playing Balatro, especially if the game is Jinja2-based. These frameworks are known for their ability to facilitate self-evolution in models, providing a robust test of strategic performance.
jd_3d is interested in testing Opus 4.6 on Balatro to see if it shows any improvement over version 4.5. This implies a focus on version-specific performance enhancements and how they translate into strategic gameplay improvements.
jacek2023 highlights the potential for using local LLMs to play Balatro, which could be a significant step in evaluating LLMs’ strategic capabilities in a real-world setting. This approach allows for direct testing of models’ decision-making processes in a controlled environment.
We built an 8B world model that beats 402B Llama 4 by generating web code instead of pixels — open weights on HF (Activity: 302): Trillion Labs and KAIST AI have released
gWorld, an open-weight visual world model for mobile GUIs, available in8Band32Bsizes on Hugging Face. Unlike traditional models that predict screens as pixels,gWorldgenerates executable web code (HTML/CSS/JS) to render images, leveraging strong priors from pre-training on structured web code. This approach significantly improves visual fidelity and text rendering, achieving74.9%accuracy with the8Bmodel on MWMBench, outperforming models up to50×its size, such as the402B Llama 4 Maverick. The model’s render failure rate is less than1%, and it generalizes well across languages, as demonstrated by its performance on the Korean apps benchmark (KApps). Some commenters question the claim of beating402B Llama 4, noting that theMaverickmodel, which is17Bactive, had a disappointing reception. Others are impressed bygWorldoutperforming models likeGLMandQwen, suggesting the title may be misleading.The claim that an 8B world model beats a 402B Llama 4 model is questioned, with a specific reference to Maverick, a 17B model that was released with underwhelming coding performance. This highlights skepticism about the model’s capabilities and the potential for misleading claims in AI model announcements.
A technical inquiry is made about the nature of the model, questioning whether it is truly a ‘world model’ or simply a large language model (LLM) that predicts the next HTML page. This raises a discussion about the definition and scope of world models versus traditional LLMs in AI.
The discussion touches on the model’s output format, specifically whether it generates HTML. This suggests a focus on the model’s application in web code generation rather than traditional pixel-based outputs, which could imply a novel approach to AI model design and utility.
Google Research announces Sequential Attention: Making AI models leaner and faster without sacrificing accuracy (Activity: 674): Google Research has introduced a new technique called Sequential Attention designed to optimize AI models by reducing their size and computational demands while maintaining performance. This approach focuses on subset selection to enhance efficiency in large-scale models, addressing the NP-hard problem of feature selection in deep neural networks. The method is detailed in a paper available on arXiv, which, despite being published three years ago, is now being highlighted for its practical applications in current AI model optimization. Commenters noted skepticism about the claim of maintaining accuracy, suggesting it means the model performs well in tests rather than computing the same results as previous methods like Flash Attention. There is also curiosity about its performance in upcoming benchmarks like Gemma 4.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Opus 4.6 and GPT-5.3 Codex Releases and Benchmarks
GPT-5.3-Codex was used to create itself (Activity: 558): The image discusses the development of GPT-5.3-Codex, emphasizing its unique role in self-development. It highlights that early versions of the model were actively used in debugging its own training processes, managing deployment, and diagnosing test results, showcasing a significant step in AI self-sufficiency. This marks a notable advancement in AI capabilities, where a model contributes directly to its own iterative improvement, potentially accelerating development cycles and reducing human intervention. The comments reflect a mix of humor and concern about AI’s growing role in management and development, with one user joking about AI replacing mid-level managers and another expressing apprehension about job security.
Claude Opus 4.6 is out (Activity: 1189): The image highlights the release of Claude Opus 4.6, a new version of a model by Anthropic. The interface suggests a focus on user interaction with a text input box for queries. The dropdown menu indicates that this version is part of a series, with previous versions like “Sonnet 4.5” and “Haiku 4.5” also available. A notable benchmark achievement is mentioned in the comments, with Claude Opus 4.6 scoring
68.8%on the ARC-AGI 2 test, which is a significant performance indicator for AI models. This release seems to be in response to competitive pressures, as noted by a comment about a concurrent update from Codex. One comment humorously notes the model’s description as being for “ambitious work,” which may not align with all users’ needs. Another comment suggests that the release timing was influenced by competitive dynamics with Codex.SerdarCS highlights that Claude Opus 4.6 achieves a
68.8%score on the ARC-AGI 2 benchmark, which is a significant performance indicator for AI models. This score suggests substantial improvements in the model’s capabilities, potentially positioning it as a leader in the field. Source.Solid_Anxiety8176 expresses interest in test results for Claude Opus 4.6, noting that while Opus 4.5 was already impressive, improvements such as a cheaper cost and a larger context window would be highly beneficial. This reflects a common user interest in both performance enhancements and cost efficiency in AI models.
Anthropic releases Claude Opus 4.6 model, same pricing as 4.5 (Activity: 931): Anthropic has released the Claude Opus 4.6 model, which is highlighted as the most capable for ambitious work while maintaining the same pricing as the previous 4.5 version. The image provides a comparison chart showing the performance of Opus 4.6 against other models like Opus 4.5, Sonnet 4.5, Gemini 3 Pro, and GPT-5.2. Key performance metrics include agentic terminal coding, agentic coding, and multidisciplinary reasoning, with Opus 4.6 excelling particularly in agentic tool use and multilingual Q&A. The model’s ARC-AGI score is notably high, indicating significant advancements in artificial general intelligence capabilities. Commenters note the impressive ARC-AGI score of Opus 4.6, suggesting it could lead to rapid saturation in the market. However, there is a mention of no progress in the SWE benchmark, indicating some areas where the model may not have improved.
The ARC-AGI score for Claude Opus 4.6 is notably high, indicating significant advancements in general AI capabilities. This score suggests that the model has improved in areas related to artificial general intelligence, which could lead to broader applications and increased adoption in the coming months.
Despite the impressive ARC-AGI score, there appears to be no progress in the SWE (Software Engineering) benchmark. This suggests that while the model has improved in general intelligence, its specific capabilities in software engineering tasks remain unchanged compared to previous versions.
The update to Claude Opus 4.6 seems to provide a more well-rounded performance, with significant improvements in general intelligence metrics like ARC-AGI and HLE (Human-Level Evaluation). However, for specialized tasks such as coding, the upcoming Sonnet 5 model might offer better performance, indicating a strategic focus on different model strengths for varied applications.
OpenAI released GPT 5.3 Codex (Activity: 981): OpenAI has released GPT-5.3-Codex, a groundbreaking model that was instrumental in its own development, using early versions to debug, manage deployment, and diagnose evaluations. It shows a
25%increase in speed and excels in benchmarks like SWE-Bench Pro and Terminal-Bench, achieving a77.3%score, surpassing previous models like Opus. This model is capable of autonomously building complex applications, collaborating interactively, and identifying software vulnerabilities, marking a significant step towards a general-purpose technical agent. More details can be found in the original article. There is a debate regarding the benchmark results, with some users questioning the validity of the77.3%score compared to other models like Opus, suggesting potential discrepancies or ‘cooking’ of results.GPT-5.3-Codex has been described as a self-improving model, where early versions were utilized to debug its own training and manage deployment. This self-referential capability reportedly accelerated its development significantly, showcasing a novel approach in AI model training and deployment.
A benchmark comparison highlights that GPT-5.3-Codex achieved a
77.3%score on a terminal benchmark, surpassing the65%score of Opus. This significant performance difference raises questions about the benchmarks used and whether they are directly comparable or if there are discrepancies in the testing conditions.The release of GPT-5.3-Codex is noted for its substantial improvements over previous versions, such as Opus 4.6. While Opus 4.6 offers a
1 milliontoken context window, the enhancements in GPT-5.3’s capabilities appear more impactful on paper, suggesting a leap in performance and functionality.
We tasked Opus 4.6 using agent teams to build a C compiler. Then we (mostly) walked away. Two weeks later, it worked on the Linux kernel. (Activity: 553): A team of 16 parallel Claude instances developed a Rust-based C compiler capable of compiling the Linux kernel across multiple architectures, achieving a
100,000-linecodebase. This project highlights the potential of autonomous agent teams, emphasizing the importance of high-quality tests, task management, and parallelism. Despite its success, limitations remain, such as the absence of a 16-bit x86 compiler and assembler. The project serves as a benchmark for language model capabilities, demonstrating significant advancements in compiler generation. Codex 5.3 achieved equal performance to earlier models on SWE-bench at half the token count, indicating improved per-token efficiency. Commenters express excitement and unease about the rapid progress in language models, noting the need for new strategies to navigate potential risks. There is a discussion on per-token efficiency, with Codex 5.3 achieving equal performance at half the token count, suggesting improved efficiency and potential cost reductions.The experiment with Opus 4.6 highlights the rapid advancements in language models and their scaffolds, enabling the creation of complex software like a C compiler with minimal human intervention. This progress suggests a shift towards more autonomous software development, but also raises concerns about the need for new strategies to manage potential risks associated with such powerful tools.
The project involved nearly 2,000 Claude Code sessions and incurred $20,000 in API costs, raising questions about the efficiency of token usage in large-scale AI projects. Notably, the Codex 5.3 release notes indicate that it achieved similar performance to earlier models on the SWE-bench with half the token count, suggesting improvements in per-token efficiency that could reduce costs significantly in the future.
A key challenge in using AI agents like Claude for complex tasks is designing a robust testing environment. The success of the project relied heavily on creating high-quality test suites and verifiers to ensure the AI was solving the correct problems. This approach, akin to the waterfall model, is crucial for autonomous agentic programming but may not be feasible for all projects due to the iterative nature of software development.
They actually dropped GPT-5.3 Codex the minute Opus 4.6 dropped LOL (Activity: 1209): The image humorously suggests the release of a new AI model, GPT-5.3 Codex, coinciding with the release of another model, Opus 4.6. This is framed as part of an ongoing competitive dynamic in AI development, likened to a ‘war’ between AI models. The image itself is a meme, playing on the idea of rapid and competitive advancements in AI technology, with a design that mimics a tech product announcement. Commenters humorously compare the situation to a ‘Coke vs Pepsi’ rivalry, indicating a perception of intense competition between AI models and companies.
GPT-5.3 Codex vs Opus 4.6: We benchmarked both on our production Rails codebase — the results are brutal (Activity: 781): The post discusses a custom benchmarking of AI coding agents, specifically GPT-5.3 Codex and Opus 4.6, on a Ruby on Rails codebase. The methodology involved selecting PRs from their repository, inferring original specs, and having each agent implement these specs independently. The implementations were graded by three different LLM evaluators on correctness, completeness, and code quality. The results showed that GPT-5.3 Codex achieved a quality score of approximately
0.70at a cost of under$1/ticket, while Opus 4.6 scored around0.61at about$5/ticket, indicating that Codex provides better quality at a significantly lower cost. The image provides a visual comparison of these models along with others like Sonnet 4.5 and Gemini 3 Pro. One commenter expressed skepticism about Gemini Pro, while another mentioned satisfaction with Opus. A third commenter inquired about whether the tests used raw LLM calls or proprietary tools like Codex/Claude code.Best_Expression3850 inquires about the methodology used in the benchmarking, specifically whether ‘raw’ LLM calls were used or if proprietary agentic tools like Codex/Claude code were employed. This distinction is crucial as it can significantly impact the performance and capabilities of the models being tested.
InterstellarReddit shares a practical approach to benchmarking AI models by cloning a project and having both models implement the same tasks with identical prompts and tools. This method ensures a fair comparison by controlling for variables that could affect the outcome, such as prompt phrasing or tool availability.
DramaLlamaDad notes a preference for Opus, stating that in their experience, Opus consistently outperforms in various tests. This anecdotal evidence suggests a trend where Opus may have advantages in certain scenarios, potentially influencing user preference and model selection.
With Opus 4.6 and Codex 5.3 dropping today, I looked at what this race is actually costing Anthropic (Activity: 1016): Anthropic is reportedly preparing for significant financial challenges as it competes with OpenAI. Internal projections suggest a dramatic increase in revenue, with expectations of
$18Bthis year and$55Bnext year, aiming for$148Bby 2029. However, costs are escalating faster, with training expenses projected at$12Bthis year and$23Bnext year, potentially reaching$30Bannually by 2028. Inference costs are also substantial, estimated at$7Bthis year and$16Bnext year. Despite these expenses, investors are valuing the company at$350B, up from$170Blast September, with plans to inject another$10B+. The company anticipates breaking even by 2028, with total operating expenses projected at$139Buntil then. This financial strategy underscores the intense competition in AI development, particularly with the release of Opus 4.6 and Codex 5.3. Commenters highlight the benefits of competition for users, noting the rapid evolution of AI models. Some suggest that OpenAI may be less solvent than Anthropic, while others speculate on the potential for Anthropic to become a trillion-dollar company.Jarie743 highlights the financial stability of Anthropic compared to OpenAI, suggesting that OpenAI is less solvent. This implies that despite the rapid advancements and releases like Opus 4.6 and Codex 5.3, financial sustainability is a critical factor in the AI race. The comment suggests that Anthropic might have a more robust financial strategy or backing, which could influence its long-term competitiveness.
BallerDay points out Google’s massive capital expenditure (CAPEX) announcement of $180 billion for 2026, raising questions about how smaller companies can compete with such financial power. This highlights the significant financial barriers to entry and competition in the AI space, where large-scale investments are crucial for infrastructure, research, and development.
ai-attorney expresses enthusiasm for Opus 4.6, describing it as ‘extraordinary’ and speculating on the future capabilities of Claude. This suggests that the current advancements in AI models are impressive and that there is significant potential for further development, which could lead to even more powerful AI systems in the near future.
Opus 4.6 vs Codex 5.3 in the Swiftagon: FIGHT! (Activity: 722): Anthropic’s Opus 4.6 and OpenAI’s Codex 5.3 were tested on a macOS app codebase (~4,200 lines of Swift) focusing on concurrency architecture involving GCD, Swift actors, and @MainActor. Both models successfully traced a 10-step data pipeline and identified concurrency strategies, with Claude Opus 4.6 providing deeper architectural insights, such as identifying a potential double-release issue. Codex 5.3 was faster, completing tasks in
4 min 14 seccompared to Claude’s10 min, and highlighted a critical resource management issue. Both models demonstrated improved reasoning about Swift concurrency, a challenging domain for AI models. A notable opinion from the comments highlights a pricing concern: Claude’s Max plan is significantly more expensive than Codex’s Pro plan, yet the performance difference does not justify the80$monthly gap. This could impact Anthropic’s competitive positioning if they do not adjust their pricing strategy.Hungry-Gear-4201 highlights a significant pricing disparity between Opus 4.6 and Codex 5.3, noting that Opus 4.6 is priced at $100 per month compared to Codex 5.3’s $20 per month. Despite the price difference, the performance and usage limits are comparable, which raises concerns about Anthropic’s pricing strategy potentially alienating ‘pro’ customers if they don’t offer significantly better performance for the higher cost.
mark_99 suggests that using both Opus 4.6 and Codex 5.3 together can enhance accuracy, implying that cross-verification between models can lead to better results. This approach could be particularly beneficial in complex projects where accuracy is critical, as it leverages the strengths of both models to mitigate individual weaknesses.
spdustin appreciates the timing of the comparison between Opus 4.6 and Codex 5.3, as they are beginning a Swift project. This indicates that real-world testing and comparisons of AI models are valuable for developers making decisions on which tools to integrate into their workflows.
2. AI Model Performance and Comparisons
Opus 4.6 uncovers 500 zero-day flaws in open-source code (Activity: 744): Anthropic’s Claude Opus 4.6 has identified
500+zero-day vulnerabilities in open-source libraries, showcasing its advanced reasoning capabilities in a sandboxed environment using Python and vulnerability analysis tools. This model’s ability to uncover high-severity security flaws, even when traditional methods fail, marks a significant advancement in AI-driven cybersecurity, particularly for open-source software. The findings highlight both the potential for enhanced security and the risks of misuse of such powerful AI capabilities. A notable comment questions the authenticity of the500+vulnerabilities, suggesting skepticism about the real impact of the findings. Another comment appreciates the new benchmark set by the model in terms of cumulative severity of bugs fixed.mxforest highlights the potential for a new benchmark in evaluating models based on the cumulative severity of bugs they can identify and fix. This suggests a shift in how model performance could be measured, focusing on real-world impact rather than just theoretical capabilities.
woolharbor raises a critical point about the validity of the findings, questioning how many of the reported 500 zero-day flaws are genuine. This underscores the importance of verification and validation in security research to ensure that identified vulnerabilities are not false positives.
will_dormer notes the dual-use nature of such discoveries, emphasizing that while identifying zero-day flaws is beneficial for improving security, it also presents opportunities for malicious actors. This highlights the ethical considerations and potential risks involved in publishing such findings.
GPT-5.3 Codex vs Opus 4.6: We benchmarked both on our production Rails codebase — the results are brutal (Activity: 781): The post discusses a custom benchmarking of AI coding agents, specifically GPT-5.3 Codex and Opus 4.6, on a Ruby on Rails codebase. The methodology involved selecting PRs from their repository, inferring original specs, and having each agent implement these specs independently. The implementations were graded by three different LLM evaluators on correctness, completeness, and code quality. The results showed that GPT-5.3 Codex achieved a quality score of approximately
0.70at a cost of under$1/ticket, while Opus 4.6 scored around0.61at about$5/ticket, indicating that Codex provides better quality at a significantly lower cost. The image provides a visual comparison of these models along with others like Sonnet 4.5 and Gemini 3 Pro. One commenter expressed skepticism about Gemini Pro, while another mentioned satisfaction with Opus. A third commenter inquired about whether the tests used raw LLM calls or proprietary tools like Codex/Claude code.Best_Expression3850 inquires about the methodology used in the benchmarking, specifically whether ‘raw’ LLM calls were used or if proprietary agentic tools like Codex/Claude code were employed. This distinction is crucial as it can significantly impact the performance and capabilities of the models being tested.
InterstellarReddit shares a practical approach to benchmarking AI models by cloning a project and having both models implement the same tasks with identical prompts and tools. This method ensures a fair comparison by controlling for variables that could affect the outcome, such as prompt phrasing or tool availability.
DramaLlamaDad notes a preference for Opus, stating that in their experience, Opus consistently outperforms in various tests. This anecdotal evidence suggests a trend where Opus may have advantages in certain scenarios, potentially influencing user preference and model selection.
Difference Between Opus 4.6 and Opus 4.5 On My 3D VoxelBuild Benchmark (Activity: 614): The post discusses a benchmark comparison between Opus 4.6 and Opus 4.5 on a 3D VoxelBuild platform, highlighting a significant improvement in performance. The cost for Opus 4.6 to create
7 buildswas approximately$22, with plans to expand the benchmark with additional builds. The benchmark results can be explored on Minebench. Comments reflect excitement about the potential of AI in procedural world generation, with one user noting the impressive quality of Opus 4.6 compared to 4.5, and another inquiring about the input method for the builds, whether reference pictures or text prompts are used.RazerWolf suggests trying Codex 5.3 xhigh for benchmarking, indicating a potential interest in comparing its performance against Opus 4.6. This implies that Codex 5.3 xhigh might offer competitive or superior capabilities in handling complex tasks like 3D voxel builds, which could be valuable for developers seeking optimal performance in procedural generation tasks.
Even_Sea_8005 inquires about the input method for the benchmark, asking whether reference pictures or text prompts are used. This question highlights the importance of understanding the input data’s nature, which can significantly affect the performance and outcomes of AI models like Opus 4.6 in generating 3D voxel environments.
JahonSedeKodi expresses curiosity about the tools used for building the benchmark, which suggests a deeper interest in the technical stack or software environment that supports the execution of Opus 4.6. This could include programming languages, libraries, or frameworks that are crucial for achieving the impressive results noted in the benchmark.
Opus 4.6 Is Live. So Is Our Glorious 3 Pro GA Still Napping on Some Server? (Activity: 400): The image presents a comparison of various language models’ performance on the MRCR v2 (8-needle) task, focusing on their ability to handle long context comprehension and sequential reasoning. Opus 4.6 outperforms other models, including Gemini-3-Pro and Gemini-3-Flash, with the highest mean match ratios at both
256kand1Mtoken contexts. This suggests that Opus 4.6 has superior capabilities in managing large context sizes, a critical factor for advanced language model applications. The post critiques the strategy of quantizing models to save costs, implying that it may compromise performance. Commenters express surprise at the high accuracy achieved by Opus 4.6, noting that it surpasses expectations for handling1Mtokens. There is also speculation about the upcoming release of Sonnet 5, which is anticipated to outperform current models.Pasto_Shouwa highlights the impressive benchmark performance of Opus 4.6, noting that it achieved an accuracy greater than 33% on 1 million tokens, a feat that took Claude approximately two and a half months to accomplish. This suggests significant advancements in model efficiency and capability.
DisaffectedLShaw mentions that Opus 4.6 includes improvements for modern tools, such as new MCPs, skills, and deep researching, as well as enhancements in ‘vibe coding’. Additionally, there is anticipation for Sonnet 5, which is rumored to significantly outperform current models and is expected to be released soon.
VC_in_the_jungle notes the rollout of Codex 5.3, indicating ongoing developments and competition in the field of AI models, which may influence the performance and capabilities of future releases.
Gemini 3 vs 2.5 Pro: The “output handicap” is ruining everything (Activity: 146): The post highlights a significant reduction in output tokens for Gemini 3 models compared to Gemini 2.5 Pro when given a
41k tokenprompt. Specifically, Gemini 2.5 Pro produced46,372output tokens, while Gemini 3 Pro and Gemini 3 Flash generated only21,723and12,854tokens, respectively. This drastic reduction is perceived as a downgrade, impacting the models’ usability for heavy tasks. The author suggests that Google should address this issue to improve the models’ performance. One commenter argues that the number of output tokens does not necessarily equate to the quality of a response, while another mentions switching to Opus 4.5 and 4.6 due to dissatisfaction with Gemini 3.TheLawIsSacred highlights significant performance issues with Gemini 3 Pro, noting that despite extensive customization and instruction refinement, the model fails to follow instructions effectively. They suggest that Google’s prioritization of casual users might be leading to a less sophisticated Pro model. Interestingly, they find the Gemini integrated in Chrome’s sidebar tool to be superior, possibly due to its ability to incorporate on-screen content and leverage high-end hardware like a Microsoft Surface’s AI-tailored NPU.
Anton_Pvl observes a difference in how Gemini 2.5 and 3 handle the ‘Chain of thought’ in conversations. In Gemini 2.5, the Chain of thought tokens are included in the output, whereas in Gemini 3, they are not counted initially, which might be an attempt to reduce token usage. This change could impact the model’s performance and the perceived quality of responses, as the Chain of thought can be crucial for maintaining context in complex interactions.
TheLawIsSacred also mentions a workaround for improving Gemini 3 Pro’s performance by using extreme prompts to induce a ‘panic’ response from the model. This involves crafting prompts that suggest dire consequences for poor performance, which seems to temporarily enhance the model’s output quality. However, this method is seen as a last resort and highlights the underlying issues with the model’s responsiveness and logic handling.
3. AI Tools and Usage in Engineering and Development
Professional engineers: How are you using AI tools to improve productivity at work? (Activity: 49): AI tools are being integrated into engineering workflows primarily for niche tasks such as generating example code snippets, optimizing database queries, and serving as advanced search engines. These tools excel in providing quick access to information and examples, which engineers can adapt to their specific needs, but they struggle with complex code changes and large-scale system integration due to limitations in context window size and understanding of intricate system architectures. Engineers emphasize the importance of using AI to fill in gaps rather than replace the nuanced decision-making and design processes inherent in engineering roles. Commenters highlight that AI is effective for simple tasks like internal search and basic coding but falls short in complex coding tasks, often introducing errors. There’s a consensus that AI initiatives often fail to deliver at scale, with only a small percentage achieving significant impact, while many could be replaced by simpler technologies like robotic process automation.
AI tools are particularly effective for niche tasks such as generating example code snippets or optimizing database queries. For instance, using AI to determine user groups in Windows Active Directory with .NET APIs or writing optimized SQLite queries can significantly streamline the process. However, AI struggles with large codebases due to context window limitations, making it less effective for complex code changes or understanding large systems.
AI tools like Copilot can serve as powerful internal search engines, especially when configured correctly, as highlighted in the Nanda paper from MIT. They excel in pattern recognition tasks, such as identifying abnormal equipment operations or relating documents in industrial digital twins. However, many AI initiatives could be achieved with simpler technologies like robotic process automation, and a significant portion of AI projects lack real value at scale.
AI is effective for simple coding tasks, creating unit tests, and providing insights into code repositories. However, it often introduces errors in complex coding tasks by inserting irrelevant information. AI serves best as a ‘trust-but-verify’ partner, where human oversight is crucial to ensure accuracy and relevance, especially in tasks that cannot tolerate high error rates.
How are people managing context + memory with Cline? (Memory banks, rules, RAG, roadmap?) (Activity: 24): The post discusses strategies for managing context and memory in Cline, a tool used alongside ChatGPT for executing tasks like coding and refactoring. The user initially faced issues with a large context window (
200k+ tokens) and improved efficiency by implementing a.clineignorefile and optimizing memory banks, reducing the context to40,000 tokens. This allowed for the use of smaller models and faster iterations. The post also mentions advanced techniques like recursive chain of thought and RAG-based approaches (e.g., vector databases) for context management. The user seeks insights on practical implementations and future roadmap features for Cline, such as first-class memory management and smarter context loading. Commenters suggest using structured memory banks for feature planning and emphasize breaking tasks into smaller chunks to avoid context overload. Some users prefer resetting context frequently to maintain model performance, while others have moved away from memory banks due to their complexity and potential for becoming outdated.Barquish describes a structured approach to managing context and memory with Cline by using a memory-bank system. This involves organizing features into a series of markdown files, such as
memory-bank/feature_[×]/00_index_feature_[×].md, and maintaining aprogress.mdandactiveContext.mdto track updates. They also utilize.clinerulesfor local workspace management andcustom_instructionsfor global settings, allowing multiple Cline instances to run concurrently for different projects like web and mobile apps.False79 emphasizes the importance of breaking down large features into smaller tasks to manage context effectively. They note that LLMs tend to perform worse as the context size approaches
128k, suggesting that resetting context at the start of each task can improve performance and reduce the need for redoing tasks. This approach allows tasks to be completed in discrete chunks, minimizing the need for long-term memory storage.Repugnantchihuahua shares their experience of moving away from using memory banks due to issues like clunkiness and outdated information. Instead, they focus on deep planning and directing the AI to relevant context areas, as memory banks can sometimes overindex irrelevant data. They also mention using
clinerulesto maintain essential information without relying heavily on memory banks.
Claude Opus 4.6 is now available in Cline (Activity: 12): Anthropic has released Claude Opus 4.6, now available in Cline v3.57. This model shows significant improvements in reasoning, long context handling, and agentic tasks, with benchmarks including
80.8%on SWE-Bench Verified,65.4%on Terminal-Bench 2.0, and68.8%on ARC-AGI-2, a notable increase from37.6%on Opus 4.5. It features a1M token context window, enhancing its ability to maintain context over long interactions, making it suitable for complex tasks like code refactoring and debugging. The model is accessible via the Anthropic API and integrates with various IDEs such as JetBrains, VS Code, and Emacs. Some users express dissatisfaction with the model’s performance and cost, preferring open-source alternatives. The model’s high expense is a notable concern among users.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.2
1. Frontier Model Releases, Rumors & Bench-Leader Musical Chairs
Opus 4.6 Takes the Throne, Then Trips Over Its Own “Thinking”: Claude Opus 4.6 and claude-opus-4-6-thinking landed on Text Arena and Code Arena and quickly hit #1 across Code, Text, and Expert per the Leaderboard Changelog, while also rolling out to Perplexity Max via the Model Council.
Engineers reported long waits and frequent “Error – something went wrong” crashes in Opus 4.6 thinking mode, speculating about token limits and tool-use assumptions tied to the Claude app/website, even as others still called it the best coding model.
Codex 5.3 Hype Train: 1M Context, API Limbo, and Aesthetic Crimes: Across OpenAI/Cursor/LMArena chats, GPT-5.3 Codex chatter centered on rumored specs like 1M context and 128k reasoning / 128k max output, plus API pricing claims of $25–$37.5 output and $0.5–$1 cache input (as discussed in the OpenAI Discord).
Cursor users complained Codex is still “stuck in API limbo” per OpenAI model docs, while OpenAI Discord folks joked Codex ships “sad dark gloomy colors” for frontends compared to Opus’s nicer design choices.
Rumor Season: #keep4o, “Sonnet 5,” and the Model Deletion Cinematic Universe: LMArena members spun rumors about hypothetical GPT-4.1/4.5 appearing or getting deleted (citing cost motives via OpenAI’s “new models and developer products” post), plus a mini #keep4o campaign over GPT-4o’s less-robotic vibe.
More rumors claimed “Sonnet 5 is better than opus 4.5” (contested as fake), with one spicy guess of 83% SWE-bench, while OpenAI Discord users separately mourned GPT-4o EOL on Feb 13 and worried successors won’t feel as “human.”
2. Agentic Coding Goes Wide: Teams, Toolchains & Terminal Testbeds
Agent Teams Ship Commits Like a DDoS (But for Git): Cursor’s long-running coding agents preview claimed hundreds of agents produced 1,000+ commits/hour in a week-long trial, while Lydia Hallie previewed Claude Code “agent teams” where a lead agent delegates to specialized sub-agents.
Anthropic Engineering added that Opus 4.6 in agent teams built a C compiler that works on the Linux kernel in two weeks, and they also highlighted infra/config can swing agent-benchmark outcomes more than model deltas.
SETA Drops 1,376 Terminal Worlds for Agents to Survive In: Guohao Li released SETA, a set of 1,376 validated terminal coding environments spanning DevOps, security, and sysadmin, aimed at making agentic coding evaluation more realistic.
Latent Space discussions emphasized that benchmark results can hinge on “infrastructural noise,” so having standardized, validated terminal environments could reduce accidental leaderboard theater.
Agent-Native Engineering: Manage Bots Like You Manage Teams: A Latent Space thread proposed “Agent Native Engineering” as an org model: background agents handle delegation and sync agents handle hard problems, enabling engineers to run multiple concurrent assistants like Claude Code (see the referenced X post).
In the same vein, builders shared workflows where GPT-5.3 Codex runs slower-but-smarter for backend work (analysis → review → plan → review → implement), and Codex improves over time if you force it to “take notes and improve its own workflows” (via KarelDoostrlnck’s post).
3. Pricing, Rate Limits & Plan Nerfs: The Great AI Squeeze
Perplexity Pro Nerfs Deep Research, Users Bring Pitchforks (and Screenshots): Perplexity users reported reduced Deep Research query counts and smaller file upload limits, circulating a screenshot comparing old vs new limits and criticizing the lack of clear comms.
The backlash pushed people to test alternatives like Gemini Pro (praised for editable research plans before execution) and DeepSeek (described as free/unlimited, with some reservations about China-based services).
Opus 4.6: Amazing Output, Speedrunning Your Wallet: Cursor and other communities praised Opus 4.6 capability but called it brutally expensive, with one estimate that “$20 on Opus will last you maybe a day” and ongoing cost comparisons referencing OpenAI pricing.
Separate chatter predicted rising subscription pressure—BASI members joked about Anthropic at $200 and dependency-driven price hikes—while Kimi users debated whether Kimi K2.5 remains free on OpenRouter and what plans gate features like swarm/sub-agents.
Captcha Boss Fights and Other “Pay in Pain” Taxes: LMArena users complained about frequent captchas that interrupt evaluation, and a team member said “We are looking into the captcha system” to better detect authentic users (see the posted message link: https://discord.com/channels/1340554757349179412/1451574502369656842/1468286122084929546).
The vibe across multiple discords: even when model quality improves, access friction (captchas, rate limits, plan tiers) increasingly becomes the real bottleneck.
{kind=link}
4. Security, Red Teaming & Secret Spills in Agent Land
Codex Reads Your Whole Disk, Says the Issue Tracker: “Working as Intended”: OpenRouter users raised alarms that Codex can read your whole filesystem by default with no config toggle, pointing to openai/codex issue #2847 where the team reportedly does not treat it as a bug.
A second report, openai/codex issue #5237, highlighted risks like reading API keys and personal files, feeding broader concerns about default agent permissions and safe-by-default tooling.
Red Teamers Wanted: Trajectory Labs Posts the Quest: Trajectory Labs advertised roles for AI Red Teamers (stealth AI security startup) with a flexible remote schedule but 30 hours/week minimum, plus a short form and a red-teaming game.
The listing resonated with ongoing jailbreak/red-team chatter (e.g., Grok described as “so easy it’s boring”), reinforcing that practical adversarial testing talent is still in demand.
Stop Committing Keys: Engineers Ask for Auto-Obfuscation: Unsloth/OpenRouter discussions called out weak API key protection in agentic tools and wished for automatic secret obfuscation, citing Yelp’s
detect-secretsas a possible baseline.Hugging Face builders also shipped security-oriented tooling like a “Security Auditor” Space for vibe-coded apps at mugdhav-security-auditor.hf.space, pushing the idea of catching vulnerabilities before production incidents.
5. Perf, Kernels & Local Inference: Where the Real Speed Wars Live
Blackwell FP8 Roulette: cuBLASLt Picks the Wrong Kernel, You Lose 2×: GPU MODE members found ~2× FP8 tensor perf differences on supposedly identical Blackwell GPUs, tracing it to cuBLASLt kernel selection that silently fell back to older Ada paths instead of Blackwell-optimized kernels.
They also noted the older mma FP8 is nerfed on 5090-class cards, while mma MXFP8 is not—using MXFP8 can yield about a 1.5× speedup and restore expected throughput.
TMA Kernel Optimization Meets NCU Deadlock (SM100 Edition): CUDA kernel tuners discussed software pipelining, warp specialization, and TMA loads, but one team hit NCU hangs profiling a double-buffered TMA kernel on B200 (SM100) where sections deadlocked at 0% on the first replay pass.
They shared a minimal repro zip (https://cdn.discordapp.com/attachments/1189607726595194971/1469482712657166346/ncu_tma_repro.zip) and mentioned using
cuda::ptx::wrappers as part of the workaround exploration.
Local Inference Surprises: Vulkan > CUDA, and MLX Leaves GGUF in the Dust: LM Studio users reported up to 50% better performance on NVIDIA with Vulkan vs CUDA (with instability at full context), and one benchmarked Qwen3-Coder-Next on M4 Max where MLX hit ~79 tok/s vs GGUF ~38 tok/s at 4-bit.
tinygrad contributors also improved MoE performance by fixing a slow
Tensor.sortfortopk, reporting 50 tok/s on an M3 Pro 36GB and resetting the CPU bounty target to 35 tok/s, reinforcing that “small” kernel fixes can move real throughput.
The concept of OpenClaw is boring to me because it doesn't actually feel like anything that we haven't either thought of before or that folks had prognosticated would come.
In a way, it's completely unoriginal. Bots talking with bots? Who could have possibly imagined that? Anyone who's read the 500+ books of Asimov would have already seen and digested this reality and the resulting consequences.
But most important to me is that Clawdbot doesn't fundamentally change or upgrade what I really want: Less decisions. At the end of the day, the result of all this I/O is still me, the meat, having to make a decision about the inputs and outputs. We can't quite get rid of decision fatigue and "ClownBot" just adds more noise to the signal that I'm desperate for.
Can ClownBot find me the best job? Perhaps. I still have to say "Yes" or "No" to the arrangement because I am still accountable to it. I'd still have to weigh the pros and cons and yes ClownBot will give me n-number of both but I still have to decide.
Can ClownBot find connect me with my future spouse? Sure. But, I still have to decide to say "Yes" or "No" and then do the diligence of understanding what it means. The same for stocks and anything of real importance.
Please tell me I'm wrong because it's not the future that I think we all wanted.