

[AINews] Context Drought
a quiet day lets us reflect on Anthropic's belated GA of 1M context windows after Gemini and OpenAI.
Anthropic is rightfully being celebrated today for releasing their 1M context models in GA, with SOTA MRCR results that fight Context Rot for as long as possible:
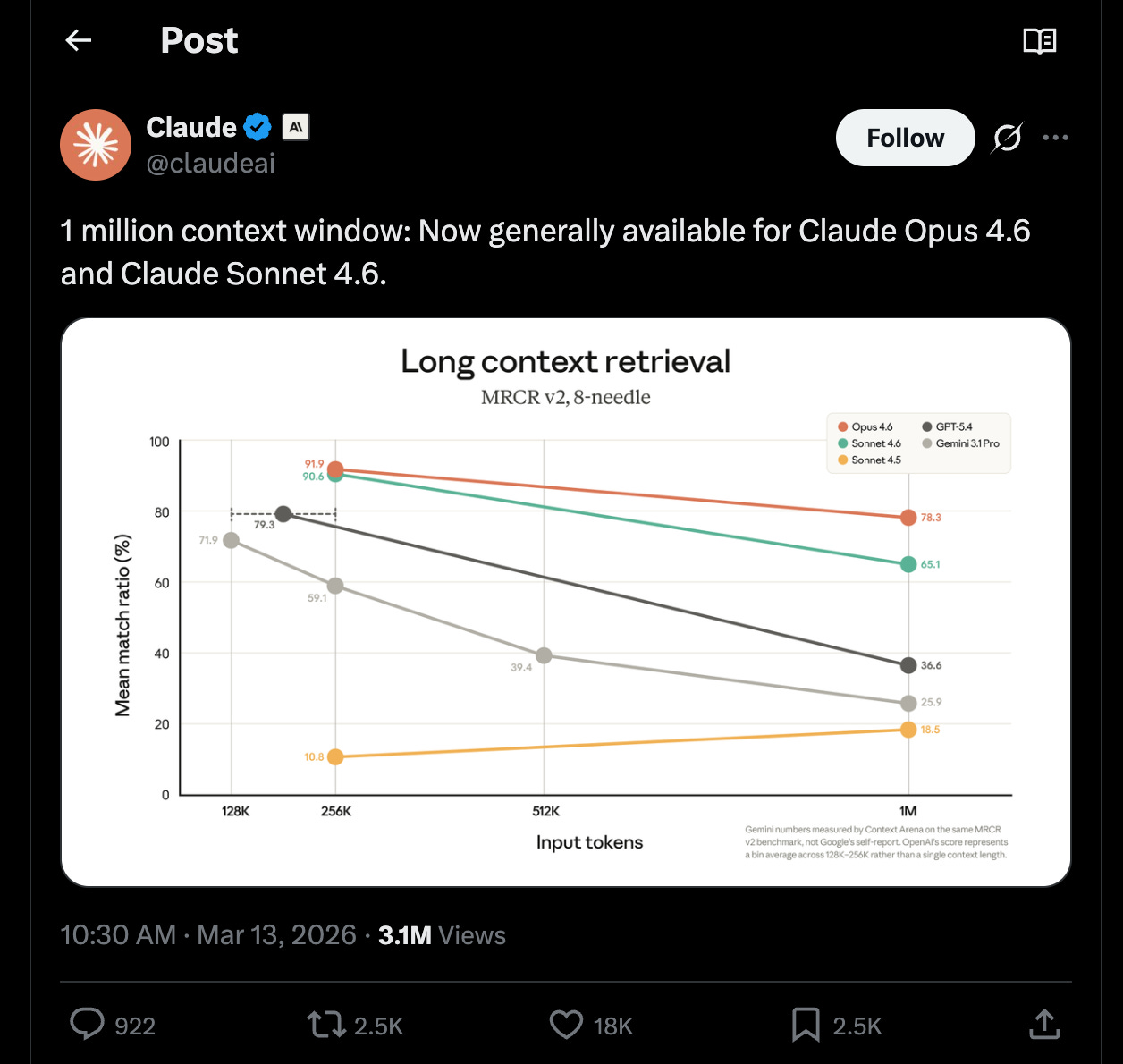
Very useful and any default model that pushes back the compaction dumb zone for longer is welcome, but we are still remembering that the 1M context window was GA in March 2024, after Gemini did it in Feb 2024, and GAing after OpenAI GA’ed theirs last week.
It’s been 2 whole years since 1M context windows were theoretically possible, which means just under 1 order of magnitude growth in 2 years in context windows, which is much slower growth than all other dimensions (cost/speed/quality) of LLMs. We’re thinking back to Sam Altman’s Town Hall where he said context windows would get 100x longer… and we would take the under on that.
The issue lies in the global memory shortage - there’s just no HBM, or even DRAM, to take in all of this context at the inference site. Our podcast with Doug O’Laughlin covers this in greater detail:
swyx: One thing I, I do tell people about is everyone, including Sam by the way, is like predicting longer context windows. We’ve been effectively stuck at a million for two years now. I’ve actually been thinking about that a lot. And like, this is not gonna go to a hundred million context windows. It’s not gonna go to trillion. Like, we’re this is it? Yeah. This is it for like five years, 10 years pretty much.
[01:45:48] Doug: Yeah, probably actually. Will capitalism work? Will there be a way for supply to show up? Probably. But on top of that, you have to make a curve of the context windows. Like does free context windows go to like 1000? Hey, you can use chatGPT free now, but your context window is like a thousand tokens or something like that. And then you can just like somehow do a tiny parcel for that just so that you can then charge 100x more for 1 million. The 1 million context window is like a mansion, you know?
[01:46:27] swyx: Oh my God. The word just context rationing just came to me. I’m like, fuck. Like we’re gonna have like vouchers for like, okay, you can have this amount of context today.
I think for me, what matters is you represent the physical constraints that us, the software side can never surmount.
[01:47:43] Because it’s a physical constraint and Well, I mean, it just, it just like, physically we cannot double, we can’t even, we can’t even double and much unless says 10x.
[01:47:53] Doug: Context rationing. It’s pretty good. Context frugality or budget or something. I feel like everyone’s gonna be like, whoa, you’re running outta context window today. Maybe that’s what happens next year.
Mark our words, people. Willing to bet that context windows do not meaningfully go higher than 1M in the next 2 years, which is a big bet to make in AI time.
AI News for 3/12/2026-3/13/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Agent Infrastructure, MCP Friction, and Persistent Memory
The MCP backlash is mostly about ergonomics, not demand: A good slice of the feed was engineers arguing over whether MCP is “dead” or simply over-exposed. @pamelafox joked that “MCP was pronounced dead on Twitter, after mass exposure to curl,” while @tadasayy countered that usage is still booming. The more substantive take came from @llama_index: MCP tools are strong when you need deterministic, centrally maintained APIs and rapidly changing ground truth; skills are lighter-weight local natural-language procedures but more failure-prone. Relatedly, @bromann pointed to new web MCP support in Chrome v146, showing a LangChain Deep Agent that continuously browses X and compiles a daily summary.
Memory is becoming the differentiator for agents: The most technically interesting agent thread was around persistent memory and self-improvement. @dair_ai highlighted IBM work on extracting reusable strategy/recovery/optimization tips from agent trajectories, improving AppWorld task completion from 69.6% to 73.2% and scenario goals from 50.0% to 64.3%, with the biggest gains on hard tasks. In parallel, @omarsar0 summarized a paper reframing multi-agent memory as a computer architecture problem, with cache/memory hierarchy, coherence, and access-control issues rather than “just more context.” This maps directly onto product work like Hermes Agent, which multiple tweets described as a self-hostable agent that retains skills and user-specific memory over time (overview via @abxxai, demo via @Teknium).
Agent UX is moving to always-on, cross-device operation: Several launches pushed agents closer to “personal computer as orchestrator.” Perplexity Computer rolled out to iOS with cross-device synchronization, letting users start or manage a browser-computer task from phone or desktop (announcement, Arav follow-up). @bcherny showed the analogous flow for Claude Code, starting sessions on a laptop from a phone. Genspark’s Claw was framed similarly as an “AI employee” with a persistent cloud computer (summary by @kimmonismus). The common pattern: persistent session state, remote execution, and orchestration across many models/tools.
Inference, Long Context, and Systems Performance
Anthropic quietly shipped one of the bigger infra-relevant updates of the week: Opus 4.6 1M context became the default for Max/Team/Enterprise users (via @_catwu), and Anthropic removed the API’s extra charge for long context while also dropping the beta header requirement and expanding media limits to 600 images/PDF pages per request (details from @alexalbert__). The most notable metric attached was 78.3% on MRCR v2 at 1M tokens, called out by multiple observers as a new frontier long-context high watermark (e.g. @kimmonismus).
Sparse attention optimization is still yielding meaningful wins: A standout systems thread from @realYushiBai introduced IndexCache, which reuses sparse-attention index information across layers in DeepSeek Sparse Attention. Reported gains: roughly 1.2× end-to-end speedup on GLM-5 (744B) with matching quality, and on a 30B-scale experimental model at 200K context, 1.82× prefill and 1.48× decode after removing 75% of indexers. This was notable because it targets a production-scale sparse-attention stack with “minimal code change,” which is exactly the kind of practical optimization labs care about now.
KV/cache and serving optimizations are broadening beyond autoregressive LLMs: @RisingSayak highlighted Black Forest Labs’ Klein KV, which injects cached reference-image KVs into later DiT denoising steps for multi-reference editing, claiming up to 2.5× speedups. On the infra side, @satyanadella said Microsoft is the first cloud validating an NVIDIA Vera Rubin NVL72 system, while @LambdaAPI pushed the “bare metal over hypervisor” angle for Rubin-era clusters. @tinygrad added a more radical endpoint: an “exabox” exposed as a single giant Python-driven GPU in 2027.
Post-Training, RL Alternatives, and Evaluation Research
A provocative post-training result: random Gaussian search can rival RL fine-tuning: The most-discussed research claim was RandOpt / Neural Thickets from MIT-adjacent authors, shared by @yule_gan and @phillip_isola. The claim: by adding Gaussian noise to pretrained model weights and ensembling, one can reach performance comparable to or better than GRPO/PPO on reasoning, coding, writing, chemistry, and VLM tasks. Their explanation is that large pretrained models live in local neighborhoods dense with useful task specialists—“neural thickets”—making post-training much easier than standard optimization intuitions suggest.
Generic-data replay and pre-pre-training are getting renewed attention: @TheTuringPost summarized Stanford work on generic data replay, reporting 1.87× improvement during fine-tuning and 2.06× during mid-training, with concrete downstream gains like +4.5% on agentic web navigation and +2% on Basque QA. Separate chatter around “pre-pre-training” suggested the community is revisiting staging/mixture design earlier in the training pipeline, not just post-training tricks (commentary from @teortaxesTex).
Evaluation remains a bottleneck, especially for truthfulness and search strategy: @i shared BrokenArXiv, where even GPT-5.4 rejected only 40% of perturbed false mathematical statements from recent papers. @paul_cal argued this gives GPT-5.4 an edge over Claude on proof-verification-style “bullshit detection,” even if other truthfulness benchmarks disagree. For retrieval/search, MADQA found agents near human answer accuracy by using brute-force search rather than strategic navigation over documents, leaving about a 20% gap to oracle performance (via @HuggingPapers).
Open Source Releases, Datasets, and Reproducibility
OpenFold3’s new preview is unusually complete by frontier biology standards: @MoAlQuraishi announced OpenFold3 preview 2, saying it closes much of the gap to AlphaFold3 across modalities while releasing not just weights but also training sets and configs, making it “the only current AF3-based model that is functionally trainable & reproducible from scratch.” That reproducibility claim is the key point: many “open” biology releases still stop well short of end-to-end re-trainability.
Speech data for underrepresented languages got a meaningful boost: @osanseviero announced WAXAL, an open multilingual speech dataset covering 17 African languages for TTS and 19 for ASR, later described by @GoogleResearch as 2,400+ hours spanning 27 Sub-Saharan languages and 100M+ speakers. The exact language/task counts differed between posts, but both positioned WAXAL as a rare, community-rooted resource for African voice AI.
Open-source sentiment around training data is hardening in favor of permissive reuse: The strongest statement came from @ID_AA_Carmack, who argued that open-source code is a gift whose value is magnified by AI training, not undermined by it. @giffmana and @perrymetzger echoed that view. The most nuanced counterpoint was @wightmanr, who argued that coding agents may bypass attribution and licensing expectations in ways that could demotivate maintainers, suggesting a protocol for agent compliance could become important.
Developer Tooling, Coding Agents, and Research Automation
Coding-agent workflows are getting more autonomous and more opinionated: There were many examples of engineers moving from “copilot” to multi-agent software factories. @matvelloso described a setup with 5 agents doing code review/test/security/perf work and 2 more merging PRs and running regression checks. @swyx compressed the trend to “Your Code is your Infra,” while @gokulr and @matanSF pointed to FactoryAI as an increasingly common “software factory” layer.
Autonomous research is becoming a product category, but not a new idea: Karpathy’s autoresearch and related hackathons drew significant attention, but several tweets noted the conceptual overlap with older systems like DSPy, GEPA, and Bayesian optimization pipelines. The most practical pointer was @dbreunig recommending optimize_anything for people interested in this style of iterative self-improvement. Together AI also shipped Open Deep Research v2, open-sourcing its app, eval dataset, code, and blog (launch).
Top tweets (by engagement)
xAI recruiting reset: @elonmusk said xAI is reviewing historical interview pipelines and re-contacting promising candidates previously rejected, after acknowledging many strong people were missed.
Claude’s chart UI: @crystalsssup posted a highly engaged reaction to Claude’s new interactive chart UX.
Perplexity Computer on mobile: @perplexity_ai launched cross-device Computer access on iOS, one of the clearest productizations of remote agent execution this week.
Microsoft validates Rubin NVL72: @satyanadella announced Azure as the first cloud validating NVIDIA Vera Rubin NVL72.
Nous / Hermes momentum: Hermes Agent and its memory-centric framing generated wide discussion via @Teknium and others, reflecting strong interest in self-hosted, improving agent harnesses.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.