

[AINews] GLM > GPT? GLM-5.2 passes vibe check; Z.ai forecasts Open Fable by December
With GLM-5.2 passing everyone's vibe check, the open models story finally becomes a real frontier story.
Don’t miss out on our Anj Midha episode today and regular tix for AIE World’s Fair!
In the AI News business, there’s a bit of trepidation talking about open models: they come out guns blazing, looking pretty on notable benchmarks, and then a month later they fade into disuse like they never existed. In other words: they were “benchmaxxed”. And we hate reporting news that you won’t remember here at LS.
One of the policies readers tell us they like about AINews is that we will simply say if nothing much happened today (a newsletter that tells you that you can skip it is rare, partly because we don’t have an eyeballs driven business model.1). Increasingly, we’ve also tried to do the inverse — repeatedly calling out a notable trend is just as important as filtering out low signal.
GLM 5 passed that bar, and GLM 5.1 didn’t. GLM 5.2, which we reported on 2 days ago, felt a little different, and that instinct was confirmed today, with multiple out of sample datapoints passing the “this is a frontier model that just happens to be open” vibe check:
Jeremy Howard, friend of the show not given to hype, sincerely complimenting it:

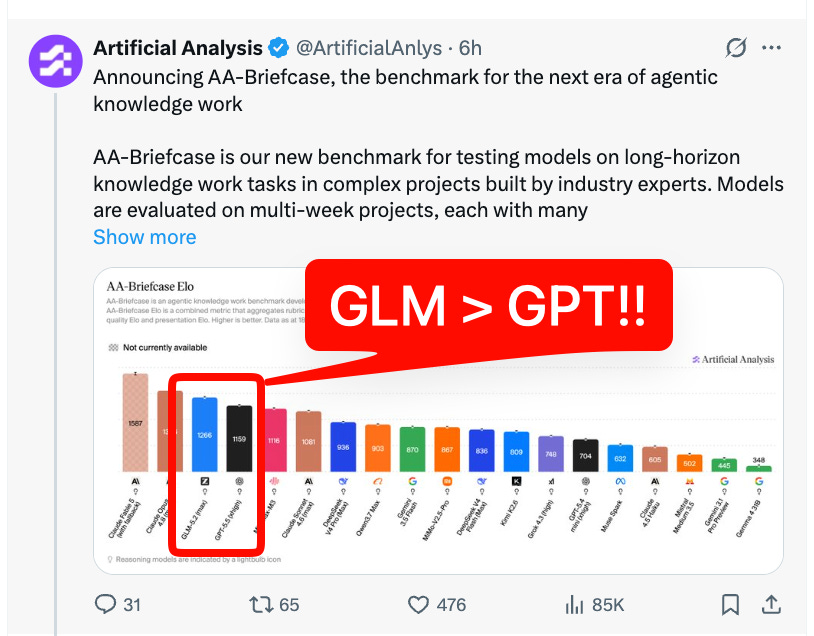
and Artificial Analysis’ new knowledge work benchmark rates it higher than GPT 5.5:
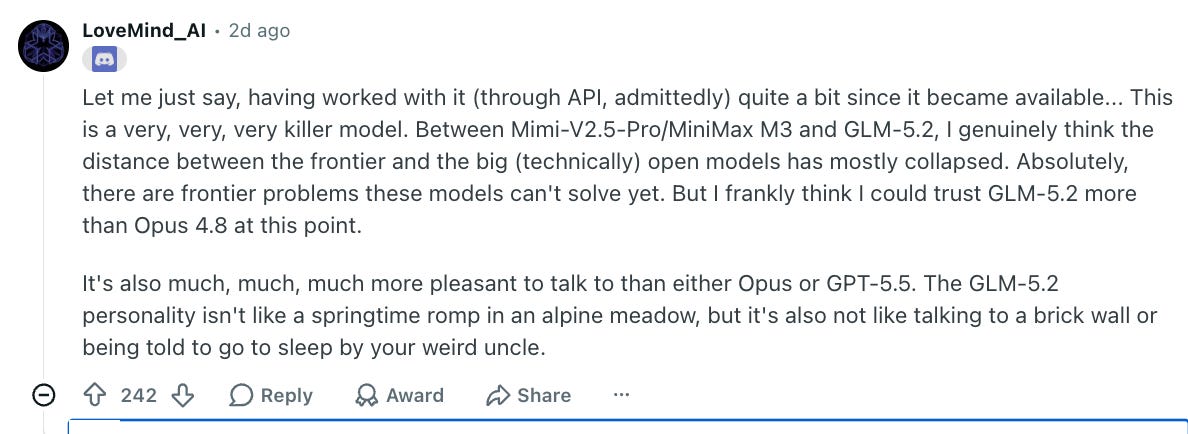
And it is passing the /r/LocalLlama vibe check:
This trajectory of Z.ai getting validation as a true frontier lab is now a serious trend; the final milestone of (Chinese) open models winning is the timeline for when we will get an open Fable-class model, without the possibility of distillation attacks (Z.ai was notably missing from the list of accused Chinese labs in Anthropic’s Feb “industrial-scale distillation” report):
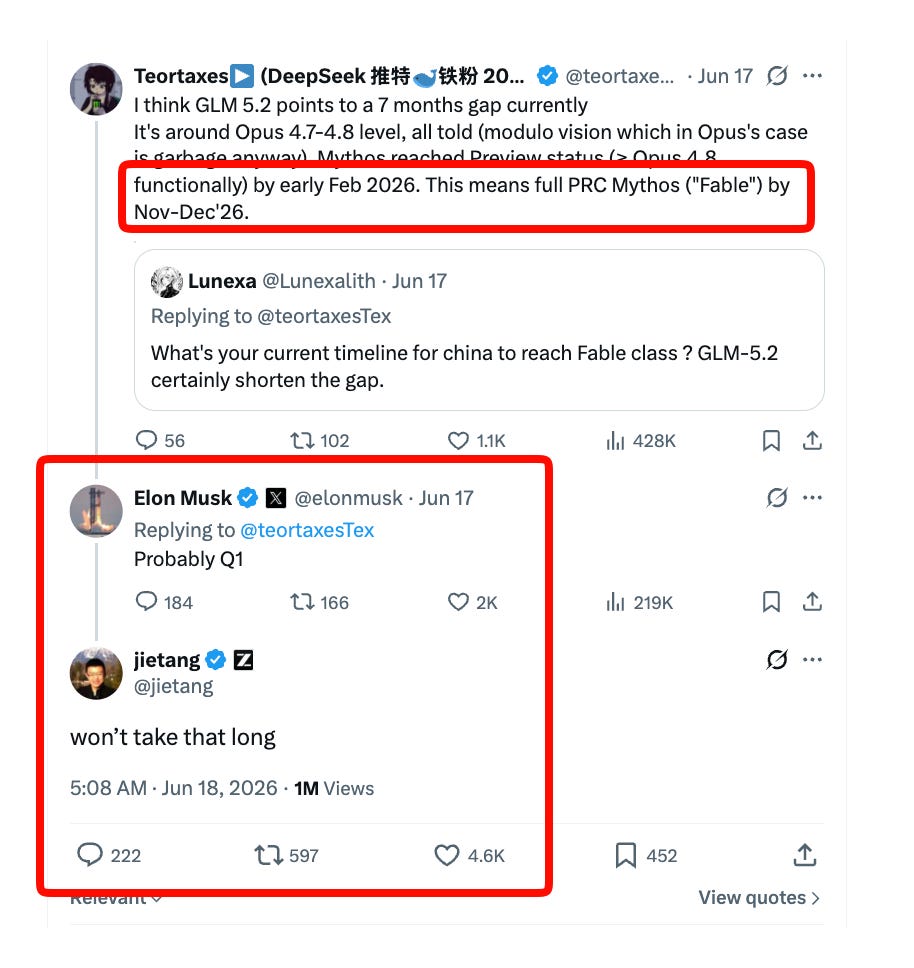
The tricky question no one can answer is - will any of the top 4 labs be able to release another Fable-class model again in the next 6 months, or has the ongoing Mythos ban put everything on ice?
AI News for 6/17/2026-6/18/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
GLM-5.2’s Breakout, Open-Weight Coding Progress, and New Open Models
GLM-5.2 became the day’s consensus open-model story: multiple practitioners independently described Zhipu’s GLM-5.2 as the first open-weight model that feels plausibly frontier-adjacent in daily use. @rasbt highlighted the architecture change: beyond MLA and DSA inherited from prior GLM/DeepSeek-style designs, GLM-5.2 adds IndexShare, reusing sparse-attention top-k indices across groups of layers to reduce the cost of 1M-token inference. Community sentiment was unusually strong: @jeremyphoward called it “at least as good as Opus 4.8 and GPT 5.5” for his use, while noting its major gap is lack of vision support; @matvelloso said it was the first open model that cleared his “daily driver” bar; @ArtificialAnlys placed it between GPT-5.5 and Opus 4.8 on a new agentic knowledge-work eval. Zhipu also pushed availability aggressively: free via Hugging Face Inference Providers for a limited window, local GGUF support via llama.cpp/Unsloth, and strong app-dev deltas from 21/70 to 48/70 internal tasks vs GLM-5.1 per @ZixuanLi_.
Other open model releases also mattered: @poolsideai released Laguna M.1 weights under Apache 2.0 with 256K context; @vllm_project described it as a 70-layer sparse MoE, 225B total / 23B active, 256 experts, top-k=16, optimized for long-horizon agentic coding with interleaved reasoning/tool use. Poolside later showed a 3-bit MLX build on Apple Silicon at ~26 tok/s and ~100 GB peak memory on an M3 Max 128 GB machine @poolsideai. On the smaller end, @cohere pushed North Mini Code accessibility with 4-bit quantization, Ollama support, and free OpenRouter access; @ollama amplified support for open local deployment.
Agent Harnesses, Workflow Automation, and Coding Tooling
The center of gravity keeps moving from “model” to “model + harness + memory + SCM”: @_xjdr published a detailed argument that traditional git/GitHub workflows break under dozens to hundreds of concurrently running code agents: stale worktrees, diverged review state, environment setup overhead, and poor state synchronization. His proposed replacement stack combines virtual shallow checkouts, jj, Sapling-like commit stacks, cloud sync, file-level ACLs, and vertical integration from model to SCM to remote runtimes, now productized via Noumena Code / ncode with later free access to its inference engine and model @_xjdr. In the same vein, @gneubig argued benchmarks should evaluate the harness + LLM pair, not either in isolation; his OpenHands comparison found different winners depending on model family and cost profile.
Automation primitives are getting more teachable and reusable: @OpenAIDevs introduced Codex Record & Replay, letting users demonstrate a workflow once and turn it into an inspectable skill; @cursor_ai launched /automate, where Cursor configures triggers/instructions/tools from a natural-language task, adding Slack emoji triggers, GitHub triggers, and computer-use for cloud agents. @ClaudeDevs shipped Artifacts in Claude Code, enabling agents to turn ongoing work into shareable live pages; @_catwu said this has already changed internal workflows for architecture changes and prototype sharing.
Security and review are becoming first-class agent tasks: @cognition added automatic security review to Devin Review, and @shayanshafii framed Devin for Security as addressing the longstanding “finding vs fixing” split in AppSec by using agentic reasoning plus harnessing to chain lower-severity findings into confirmed severe exploits.
Top tweet in tooling by engagement: @OpenAIDevs’ Codex Record & Replay was the most engaged high-signal developer-tool post in the set, reflecting strong appetite for teach-by-demonstration agent workflows.
Benchmarks, Evaluations, and Long-Horizon Agent Measurement
Artificial Analysis launched a more realistic agentic knowledge-work benchmark: @ArtificialAnlys introduced AA-Briefcase, built around multi-week projects, thousands of fragmented inputs, Slack/email/document corpora, and deliverables like financial models and board decks. On this benchmark, Claude Fable 5 led at 1587 Elo, with Opus 4.8 next at 1356, and GLM-5.2 at 1266 as the strongest non-Anthropic open-ish entrant mentioned. Importantly, the benchmark exposes both quality and economics: Fable 5 averaged $31/task, Opus 4.8 $10.40, GPT-5.5 xhigh $3.68, GLM-5.2 $2.40, while some weaker options were orders of magnitude cheaper. The broader lesson is not just leaderboard movement, but that real-world long-horizon knowledge work remains hard: the top model satisfied all rubric criteria on only 3% of tasks.
Additional benchmark work pushed in the same direction: @terminalbench released Terminal-Bench Challenges for long-horizon, token-intensive single tasks; @omarsar0 highlighted SkillWeaver, which treats agent routing as compositional skill retrieval + DAG planning rather than single-tool selection; @arena described Agent Arena’s causal tracing approach for quantifying the value of human/AI collaboration via signals like steerability, bash recovery, and tool hallucination. There was also continued meta-critique of agent eval quality from @isidoremiller, who argued current analytics-agent benchmarks are often measuring the wrong things.
Inference, Retrieval, and Systems Efficiency
Inference and retrieval optimization remained a strong secondary theme: @liquidai released LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M, multilingual retrieval models covering 11 languages with claimed 1.5 ms end-to-end retrieval latency on their enterprise stack. @CoreWeave claimed 289 tok/s serving for Kimi K2.7 Code, emphasizing provider-side price/perf as a differentiator. @vllm_project reported Ray Serve LLM + vLLM improvements of up to 4.4x throughput on prefill-heavy workloads and 24x on decode-heavy workloads via direct streaming, a Ray V2 executor backend, and HAProxy-based ingress routing.
Vector DB / parsing economics improved materially: @turbopuffer cut its base plan from $64 to $16/month, then added i8 vectors for 4x lower bytes/dim and up to 75% lower storage/query costs when paired with quantization-aware embeddings @turbopuffer. On the document side, @llama_index and @jerryjliu0 shipped LiteParse v2.1, claiming the fastest open, model-free PDF/document → markdown pipeline, outperforming several OSS parser baselines on three benchmarks.
Health, Medicine, and Safety/Alignment Research
OpenAI had a notably health-heavy day: @OpenAI shared a NEJM AI study with Boston Children’s/Harvard showing o3 Deep Research helped clinicians revisit previously unsolved pediatric rare-disease cases; @gdb summarized this as helping find 18 new diagnoses across 376 previously unsolved cases. Separately, @OpenAI said GPT-5.5 Instant is now on par with frontier “Thinking” models for health-related questions, supported by feedback from hundreds of physicians across 60 countries, 49 languages, and 26 specialties.
OpenAI also published broader alignment work: @OpenAI introduced research on training models to be broadly and persistently beneficial, claiming RL on health-domain conversations reinforcing traits like truthfulness, humility, and concern for human welfare improved 44/53 internal/external alignment and benefits evals, and that even health-only beneficial-trait training improved 17/19 non-health alignment evals including deception and coding reward hacking per @thekaransinghal. This is early, but it is one of the clearer attempts to operationalize “generalized beneficial behavior” instead of narrow refusal-style safety.
Top tweets (by engagement)
@narendramodi on meeting Mistral’s Arthur Mensch: mostly geopolitical rather than technical, but notable as another signal of national-level AI diplomacy and India partnership positioning.
@OpenAIDevs on Codex Record & Replay: the day’s biggest developer-tool post; strong validation for demonstration-based automation as a product surface.
@ClaudeDevs on Enterprise-Managed Auth for MCP: highly engaged enterprise infrastructure announcement; central auth for MCP connectors via IdP is important plumbing for enterprise agent deployment.
@OpenAI on GPT-5.5 Instant health improvements: one of the strongest signals that mainstream product models are being tuned around domain-specific utility with physician-led eval loops.
@jeremyphoward on GLM-5.2 and @ollama on scaling GLM-5.2 cloud capacity: together capture the day’s open-model mood—GLM-5.2 wasn’t just released; it was immediately pressure-tested, praised, and operationalized.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. GLM-5.2 Local Access and Quantization
GLM-5.2 is a win for local AI (Activity: 1623): The post argues GLM-5.2 is significant for local AI despite its
753Btotal-parameter MoE footprint (~40Bactive/token), because its MIT license,28.5T-token pretraining scale, claimed1Mcontext /131koutput support, and frontier-level coding-agent behavior could enable high-quality synthetic-data distillation into8B/70Blocal models. The author estimates inference memory from~744–890GBfor FP8 down to~176–180GBfor dynamic 1-bit quantization, with KV-cache overhead of roughly15–20GB,7.5–10GB, or3.5–5GBper100ktokens for FP16/BF16, 8-bit, or 4-bit cache respectively, while noting the table was AI-generated and approximate. Commenters report strong API-based impressions, with one claiming GLM-5.2 and MiniMax/Mimi models have largely closed the gap to proprietary frontier models and that they would trust GLM-5.2 over Opus 4.8. Others push back on “local” practicality: some users with512GBMacs, GB10 clusters, or multiple128GBAMD AI Max systems may run it, but the hardware requirements are increasingly “unobtanium,” motivating interest in a distilled or dense70Bvariant.Several commenters frame GLM-5.2 as narrowing the gap between large open-weight/API-accessible models and frontier closed models, with one user saying that alongside MiniMax M3 / Mimi-V2.5-Pro, the “distance between the frontier and the big open models has mostly collapsed.” They specifically compare trust and interaction quality against Claude Opus 4.8 and GPT-5.5, while acknowledging there remain “frontier problems” these models still cannot solve.
Hardware feasibility was debated: while
512GBMacs, GB10 clusters, or multiple AMD AI MAX 128GB systems may technically run models at this scale, one commenter argues that Mac Studio-class setups become impractical at large context lengths. The cited bottleneck is poor PP/TG performance at50K+context windows—“you can run it but it’s not usable”—highlighting the distinction between fitting a model in memory and achieving acceptable generation throughput.A commenter highlights the parameter-efficiency claim that GLM-5.2 reaches roughly Claude Opus 4.6-level capabilities in <800B parameters, and speculates that smaller derivatives such as GLM-5.2 Air at
200B–300Bor GLM-5.2 Flash around40Bcould be especially compelling. They also connect this to expected next-generation open models like Gemma 5 and Qwen 4, assuming continuation of prior capability gains from Gemma 4 and Qwen 3.5/3.6.
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.