

[AINews] Is Harness Engineering real?
a quiet day lets us reflect on a central debate in AI engineering
A common debate in my finance days was about the value of the human vs the value of the seat: if a trader made $3m in profits, how much of it was because of her skills, and how much was because of the position/institution/brand she is in, and any generally competent human could have made the same results?
The same debate is currently raging in “Harness Engineering”, the systems subset of Agent Engineering, and the main job of Agent Labs. The central tension is between Big Model and Big Harness. [An AI framework founder you all know] once confided in me at an OpenAI event: “I’m not even sure these guys want me to exist.”
Aside: let’s define Harness — “In every engineering discipline, a harness is the same thing: the layer that connects, protects, and orchestrates components — without doing the work itself.“
And, talking with the Big Model guys, you really see it:
Every podcast with Boris Cherny and Cat Wu emphasizes how minimal the harness of Claude Code is, meaning their job is mostly letting the model express its full power in the way that only the model maker knows best:
Boris: “I would say like there’s nothing that secret in the source. And obviously it’s all JavaScript, so you can just decompile it. Compilation’s out there. It’s very interesting. Yeah. And generally our approach is, you know, all the secret sauce, it’s all in the model. And this is the thinnest possible wrapper over the model. We literally could not build anything more minimal. This is the most minimal thing.
Cat [01:09:21]: It is very much the simplest thing I think by design.
Boris [01:09:25]: So it’s got simpler. It got simpler. It doesn’t go more complex. We’ve rewritten it from scratch probably every three weeks, four weeks or something. And it just like all the, it’s like a ship of Theseus, right? Like every piece keeps getting swapped out and just cause quad is so good at writing its own code.”
OpenAI’s own piece on Harness Engineering (with upcoming guest Ryan Lopopolo on the Codex team) emphasizes how simple it is to start. Of course, with the “execuhire” of OpenClaw, OpenAI are now big investors of the world’s most successful open source harness.
Noam Brown: “before the reasoning models emerged, there was like all of this work that went into engineering agentic systems that like made a lot of calls to GPT-4o or like these non-reasoning models to get reasoning behavior. And then it turns out we just created reasoning models and they, you don’t need this complex behavior. In fact, in many ways, it makes it worse. Like you just give the reasoning model the same question without any sort of scaffolding and it just does it. And so people are building scaffolding on top of the reasoning models right now. But I think in many ways, those scaffolds will also just be replaced by the reasoning models and models in general becoming more capable. And similarly, I think things like model routers, we’ve said pretty openly that we want to move to a world where there is a single unified model. And in that world, you shouldn’t need a router on top of the model.”
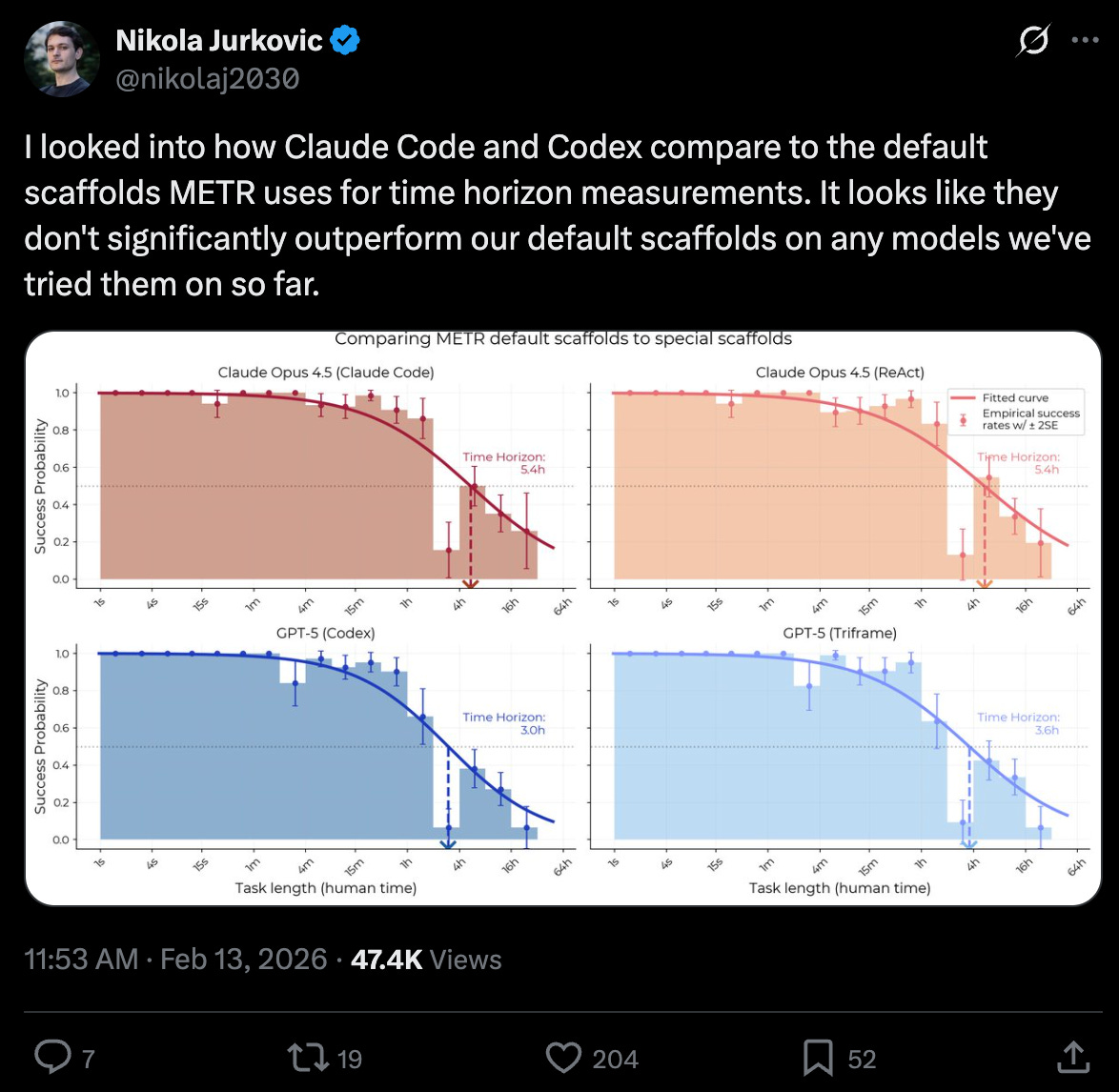
METR saying Claude Code and Codex don’t beat a basic scaffold:
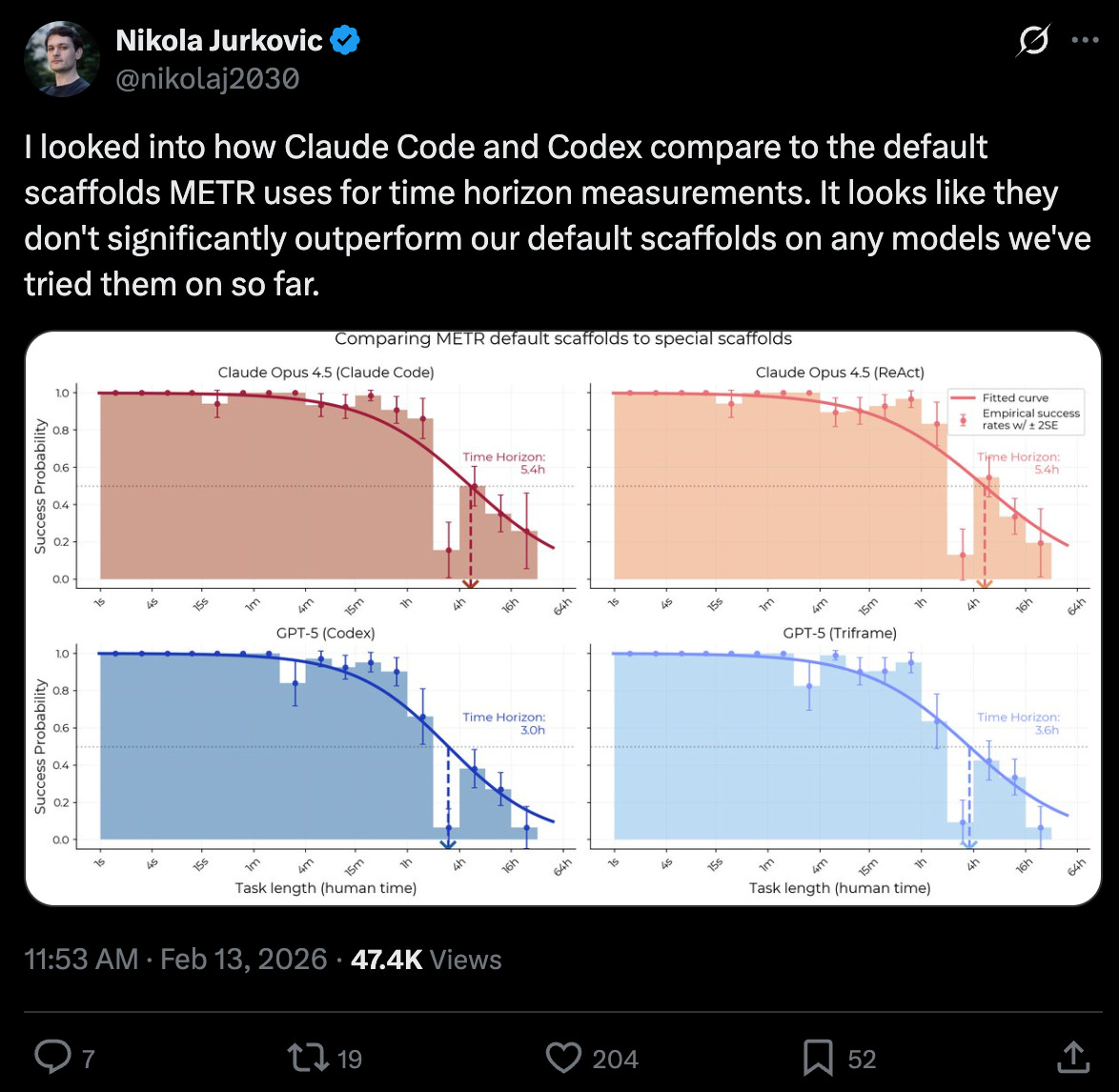
Scale AI’s SWE-Atlas is finds that Opus 4.6 does 2.5 points better in Claude Code than in the generic SWE-Agent, but the reverse for GPT 5.2, making the harness you choose essentially noise within the margin of error:


And yet. The Big Harness guys disagree:
Every production agent converges on this core loop:
while (model returns tool calls):
execute tool → capture result → append to context → call model againThat is it. The entire architecture of Claude Code, Cursor’s agent, and Manus fits inside that loop.
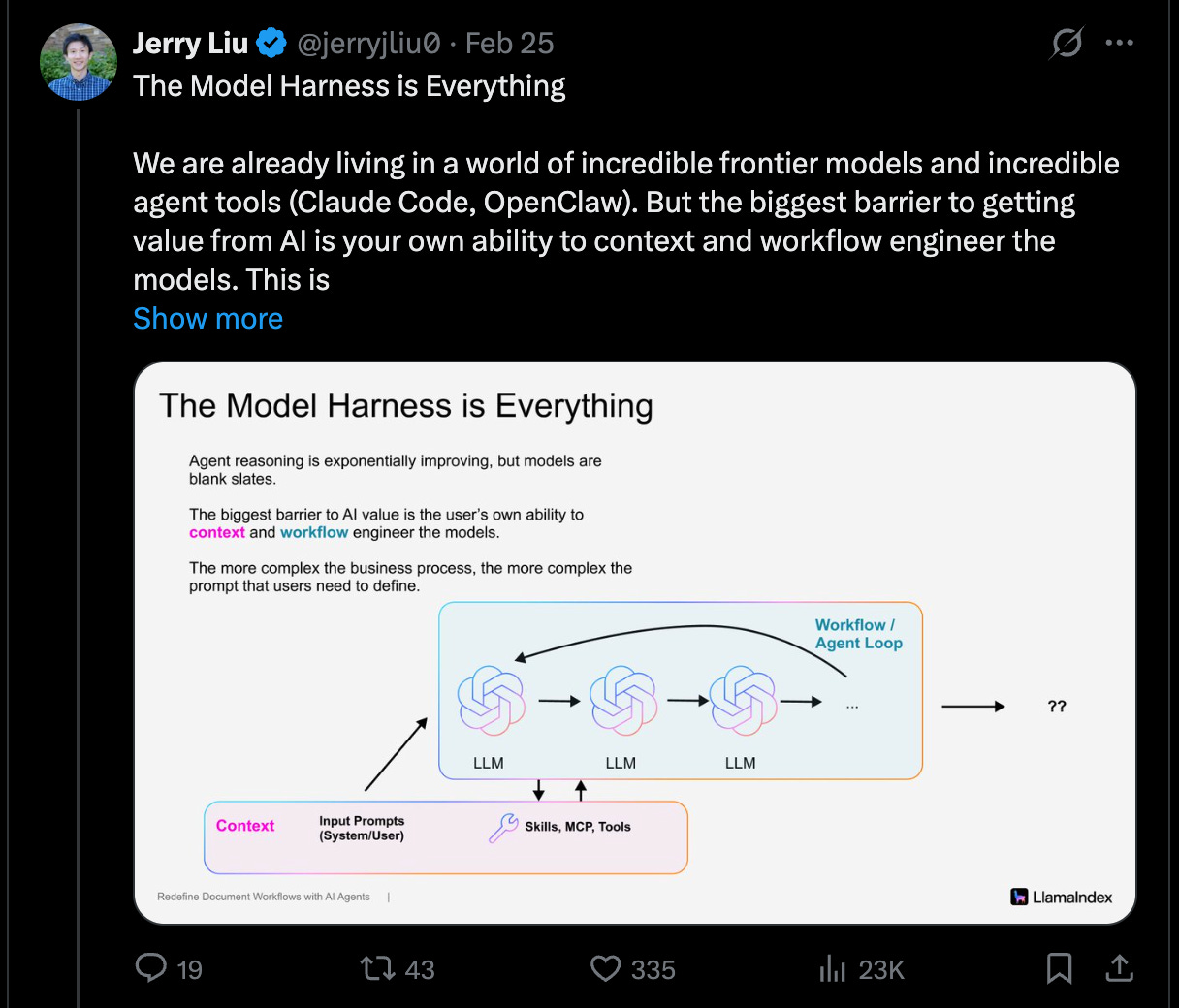
Jerry Liu: “The Model Harness is Everything — the biggest barrier to getting value from AI is your own ability to context and workflow engineer the models. This is *especially* true the more horizontal the tool that you’re using.”

Improving 15 LLMs at Coding in One Afternoon. Only the Harness Changed shows dramatic improvements in every model when you optimize the harness (Pi)
Obviously Big Harness guys are trying to sell you their Harness, Big Model guys are trying to sell you their Model. The ML/AI industry has always had some form of milquetoast “compound AI” debate that tells you both are valuable. But perhaps the times are changing.
On Latent Space we’ve been very, very respectful of the Bitter Lesson, but increasingly as the Agent Labs thesis has played out (with Cursor now valued at $50B), we are acknowledging that “Harness Engineering” has real value. AIE Europe now has the world’s first Harness Engineering track, and if you are keen on this debate, you should join.
AI News for 3/3/2026-3/4/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (264 channels, and 14242 messages) for you. Estimated reading time saved (at 200wpm): 1397 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Frontier model shipping: Gemini 3.1 Flash-Lite, GPT-5.4 rumors, and “agent-first” product positioning
Gemini 3.1 Flash-Lite positioning (speed/$): Demis Hassabis teased Gemini 3.1 Flash-Lite as “incredibly fast and cost-efficient” for its performance—clearly framing the model line around latency and cost per capability rather than raw frontier scores (tweet). Related product chatter highlights NotebookLM as a “favorite AI tool” (tweet) and a major new NotebookLM Studio feature: Cinematic Video Overviews that generate bespoke, immersive videos from user sources for Ultra users (tweet).
GPT-5.4 leak narrative (The Information): Multiple tweets amplify a report that GPT-5.4 is coming with a ~1M token context window and a new “extreme reasoning mode” that can “think for hours,” targeting long-horizon agentic workflows and lower complex-task error rates (tweet, tweet, tweet). There’s also speculation that OpenAI is shifting to more frequent (monthly) model updates (tweet). Separately, one arena watcher claims “GPT-5.4 landed in the arena,” implying an imminent release window (tweet). Treat all of this as unconfirmed unless corroborated by OpenAI.
Claude as “agent behavior” leader, not just coding: Nat Lambert argues the discussion should shift from Anthropic “going all-in on code” to their lead on general agent behavior, implying coding capability will commoditize but agent robustness will not (tweet). MathArena evaluation adds a datapoint: Claude Opus 4.6 is strong overall but weak on visual mathematics, and costly to evaluate (claimed ~$8k) (tweet).
Keep reading with a 7-day free trial
Subscribe to Latent.Space to keep reading this post and get 7 days of free access to the full post archives.