



The AI Engineer Summit Expo has been announced, presented by AutoGPT (and future guest Toran Bruce-Richards!) Stay tuned for more updates on the Summit livestream and Latent Space University.
This post was on HN for 10 hours.
What comes after the Transformer? This is one of the Top 10 Open Challenges in LLM Research that has been the talk of the AI community this month. Jon Frankle (friend of the show!) has an ongoing bet with Sasha Rush on whether Attention is All You Need, and the most significant challenger to emerge this year has been RWKV - Receptance Weighted Key Value models, which revive the RNN1 for GPT-class LLMs, inspired by a 2021 paper on Attention Free Transformers from Apple (surprise!).

What this means practically is that RWKV models tend to scale in all directions (both in training and inference) much better than Transformers-based open source models:
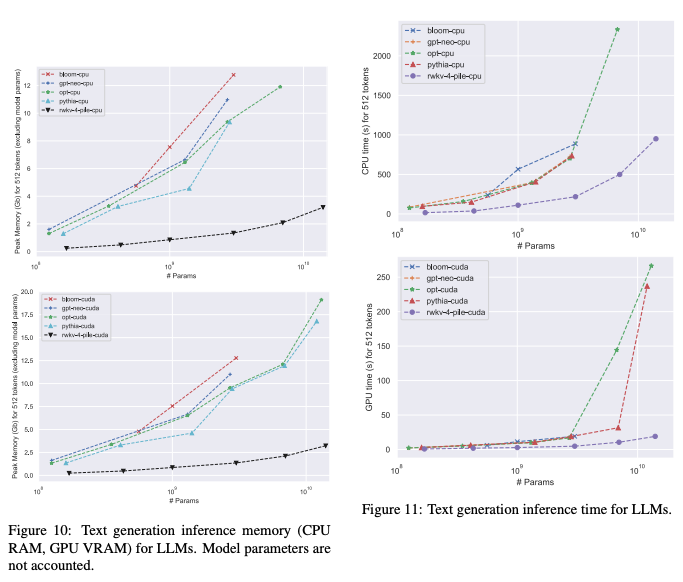
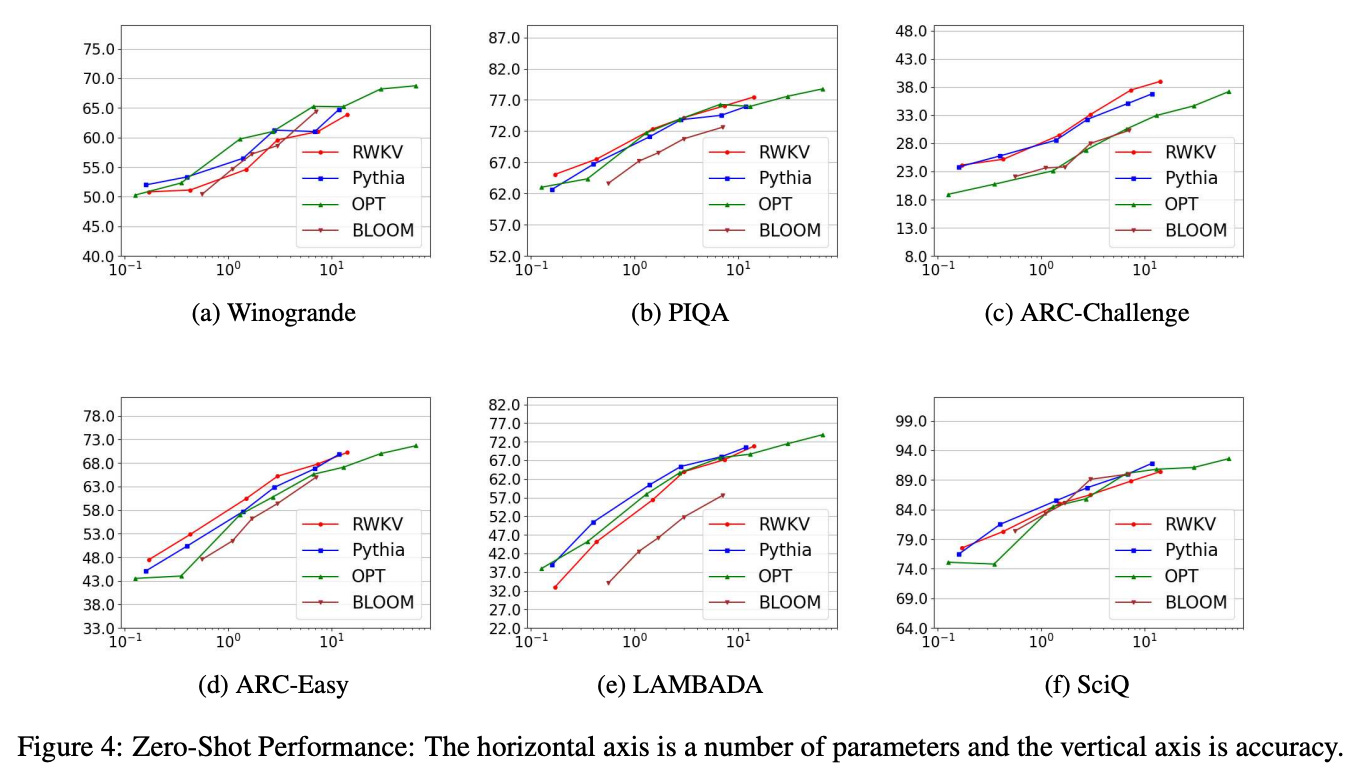
While remaining competitive on standard reasoning benchmarks:
swyx was recently in Singapore for meetings with AI government and industry folks2, and grabbed 2 hours with RWKV committee member Eugene Cheah for a deep dive, the full recording of which is now up on Latent Space TV:
Today we release both the 2hr video and an edited 1hr audio version, to cater to the different audiences and provide “ablation opportunities” on RWKV interest level.
The Eleuther Mafia?
The RWKV project is notable not merely because of the credible challenge to the Transformers dominance. It is also a distributed, international, mostly uncredentialed community reminiscent of early 2020s Eleuther AI:
Primarily Discord, pseudonymous, GPU-poor volunteer community somehow coordinating enough to train >10B, OPT/BLOOM-competitive models
Being driven by the needs of its community, it is extremely polyglot (e.g. English, Chinese, Japanese, Arabic) not because it needs to beat some benchmarks, but because its users want it to be for their own needs.
“Open Source” in both the good and the bad way - properly Apache 2.0 licensed (not “open but restricted”), yet trained on data taken from commercially compromised sources like the Pile (where Shawn Presser’s Books3 dataset has been recently taken down) and Alpaca (taking from Steven Tey’s ShareGPT which is technically against OpenAI TOS)
The threadboi class has loved tracking the diffusion of Transformers paper authors out into the industry:

But perhaps the underdog version of this is tracking the emerging Eleuther AI mafia:

It will be fascinating to see how both Eleuther and Eleuther alums fare as they build out the future of both LLMs and open source AI.
Audio Version Timestamps
assisted by smol-podcaster. Different timestamps vs the 2hr YouTube
[00:05:35] Eugene's path into AI at UIlicious
[00:07:33] Tokenizer penalty and data efficiency of Transformers
[00:08:02] Using Salesforce CodeGen
[00:10:17] The limitations of Transformers for handling large context sizes
[00:13:17] RWKV compute costs compared to Transformers
[00:16:06] How Eugene found RWKV early
[00:18:52] RWKV's focus on supporting many languages, not just English
[00:21:24] Using the RWKV model for fine-tuning for specific languages
[00:24:45] What is RWKV?
[00:33:46] Overview of the different RWKV models like World, Raven, Novel
[00:41:34] Background of Blink, the creator of RWKV
[00:49:55] The linear vs quadratic scaling of RWKV vs Transformers
[00:53:29] RWKV matching Transformer performance on reasoning tasks
[00:54:31] The community's lack of marketing for RWKV
[00:57:00] The English-language bias in AI models
[01:00:33] Plans to improve RWKV's memory and context handling
[01:03:10] Advice for AI engineers wanting to get more technical knowledge
Show Notes
Companies/Organizations:
RWKV - HF blog, paper, docs, GitHub, Huggingface
EleutherAI - Decentralized open source AI research group
Stability AI - Creators of Stable Diffusion
Conjecture - Spun off from EleutherAI
People:
Eugene Chia - CTO of UIlicious, member of RWKV committee (GitHub, Twitter)
Blink/Bo Peng - Creator of RWKV architecture
Quentin Anthony - our Latent Space pod on Eleuther, coauthor on RWKV
Sharif Shameem - our Latent Space pod on being early to Stable Diffusion
Tri Dao - our Latent Space pod on FlashAttention making Attention subquadratic
Linus Lee - our Latent Space pod in NYC
Jonathan Frankle - our Latent Space pod about Transformers longevity
Chris Re - Genius at Stanford working on state-space models
Andrej Karpathy - Zero to Hero series
Justine Tunney ("Justine.lol") - mmap trick
Models/Papers:
Retentive Network: A Successor to Transformer for Large Language Models
GPT-NeoX - Open source replica of GPT-3 by EleutherAI
Monarch Mixer - Revisiting BERT, Without Attention or MLPs
Misc Notes
RWKV is not without known weaknesses - Transformers do well in reasoning because they are expressive in the forward pass, yet the RWKV docs already note that it is sensitive to prompt formatting and poor at lookback tasks. We also asked pointed questions about RWKV’s challenges in the full podcast.
The Unreasonably Effective architecture strikes back!
Let us know if a dedicated essay/podcast on AI industrial policy would be ideal, and who you’d like to hear on the topic. We don’t have policy experience, but as citizens of smaller countries we do care about offering any help we can.
