


This episode came together at ~4 hrs notice since Dylan had just landed in SF and we had to setup quickly; you might notice some small audio issues in some segments, we apologize. We’re currently building our own podcast studio for 2024! 🙏
We’re ramping up our presence on Twitter and YouTube if you’d like to support us.
Note: 17k people joined our emergency pod on Sam Altman’s ouster today.
If Charles Dickens was alive in 2024, A Tale of Two Cities might be the divide between the “GPU poor” and the “GPU rich”.
We mentioned these terms in some of our previous episodes; they were originally coined by Dylan Patel of SemiAnalysis in his “Gemini Eats the World” post, put on blast by Sam Altman. SemiAnalysis are one of the most in depth research and consulting firms in the semis world, and have a unique insight into the design, production, and supply chain of GPUs based on their ground presence in Asia.
In this episode we break down the State of Silicon: when are more GPUs coming? Are there real GPU alternatives on the way? Should Microsoft buy AMD chips just to scare Jensen? Is there a “GPU poor is beautiful” manifesto?

The supply wave is coming
. Each GPU in the wave should have a distinctive green color scheme and the iconic NVIDIA logo, designed in an exaggerated and playful manner. The GPUs are various models, with large, prominent fans and glowing lights, capturing the essence of NVIDIA's design. The wave is dynamic and full of movement, positioned to crash onto an empty sandy beach. Above, the sky is bright with a few stylized clouds, complementing the colorful scene.")
The GPU shortage is the talk of the town in the Bay Area, but next year looks a lot better in terms of AI accelerating capacity:
NVIDIA is forecasted to sell over 3 million GPUs next year, about 3x their 2023 sales of about 1 million H100s.
AMD is forecasting $2B of sales for their new MI300X datacenter GPU. They are also indirectly getting a boost from the work that companies like Modular and tiny are doing in making it easier to actually use these chips (will ROCm ever catch up?)
Google’s TPUv5 supply is going to increase rapidly going into 2024
Microsoft just announced Maia 100, a new AI accelerator built “with feedback” from OpenAI.
In the episode we dove deeper into what this means for each of these companies and the GPU consumers, but the TLDR (sadly) is that capacity increases but FLOPS requirements to train the next generation of models will eclipse the one of previous ones.
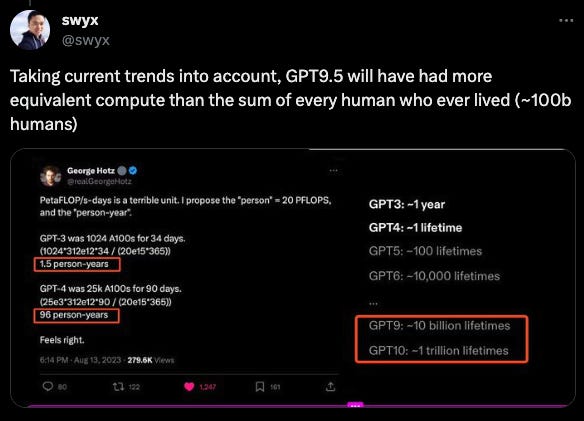
GPT-3 was 4,000x more FLOPS than GPT-2. Dylan estimates GPT-4 was trained on 20,000 A100s for ~$500M all-in; how much will OpenAI spend to train GPT-5? How many GPUs will need to go brrr? In the meantime, the amount of companies looking for GPUs has increased, with Meta rising as one of the de-facto top 3 AI labs in terms of capacity. The pressure to acquire more chips will not ease in 2024.
We also talked about some of the companies trying to displace traditional GPU architectures: MatX, Lemurian Labs, Cerebras, etc. The different variables they are fighting on are size of SRAM vs HBM, focusing on memory bandwidth vs memory size, different math representation for kernels, etc, and how the key to this market is whether or not the transformer architecture will still be the #1 in the future.
Surviving in the GPU Poor lane

A lot of the smaller companies (when compared to $1T+ giants, it’s all relative) are trying hard to fight against the GPU rich, but they can’t quite offer the same scale:
HuggingFace is trying to launch a training cluster as a service, but it seems to just be a software wrapper around NVIDIA’s GDX Cloud, as they don’t actually own that much GPU supply. The max option for GPUs to use is 1,000 in their form.
Databricks’ “GPU-enabled clusters” run on AWS, and the largest one listed there is only powered by 8 NVIDIA A10Gs. The Mosaic team is also doing research on running on AMD cards with some promising results, but they seem to be pushing up to just 128 cards, which isn’t much.
Together actually has 4,424 H100s live in production, which is quite sizable but still nothing compared to the 100,000 that Meta is putting online.
Take LLaMA2 as an example; the 70B model was trained on 2T tokens. Using the highest accelerator count on HuggingFace it’d take ~43 days to train the model from scratch and it’d cost ~$2M. That doesn’t include all the data and prep work. In the meantime, Zuck is probably burning tens of thousands of H100s to train LLaMA3, which will surely have much higher performance than whatever a GPU poor company can train in the same time span.
The good news, is that there’s a ton of opportunity for the GPU poors to shine, especially around fine-tuning. Most of the open source models coming out are one-size-fits-all, and there’s a ton of opportunity for startups to take them and tailor them to their customers, or to specific tasks or use cases to build vertical applications. The other area of improvement is data quality; Mistral showed how you can build a high quality small model with less FLOPs by feeding it better data. The key to differentiation won’t be GPUs, but tokens.
Show Notes
@sama: incredible google got that semianalysis guy to publish their internal marketing/recruiting chart lol
For SRAM / HBM, see our FlashAttention episode
Suggested readings:
Chapters
Introduction [00:00:00]
Importance of infrastructure for tech companies [00:01:11]
Training costs are irrelevant [00:03:06]
Worldview of GPU-poor vs GPU-rich [00:04:01]
Google's TPU infrastructure [00:08:12]
Alternative hardware like Cerebras and Graphcore [00:17:37]
Partnerships between labs and hardware companies [00:37:15]
Apple's potential in AI [00:40:56]
Concerns over China and Taiwan [00:41:02]
Feasibility of rebuilding the semiconductor supply chain in the US [00:43:22]
Foundational semiconductor readings [00:46:09]
NVIDIA's pivot to AI [00:47:40]
Dylan's writing process [00:48:17]
Using multiple data centers for distributed AI training [00:52:36]
Transcript
Alessio: Hey, everyone. Welcome to the Latent Space Podcast. This is Alessio, partner and CTO of Residence at Decibel Partners. I'm joined by my co-host Swyx, founder of Smol AI. [00:00:16]
Swyx: And today we have Dylan Patel and welcome. So you are the author of the extremely popular Semi-Analysis blog. We have both had a little bit of claim to fame in breaking details of GPT-4. George Hotz came on our pod and talked about the mixture of experts thing and then you had a lot more detail. [00:00:29]
Dylan: To be clear, I talked about mixture of experts in January, it's just people didn't really notice it. Yeah. I guess. [00:00:35]
Swyx: I don't know. You went into a lot more detail and I'd love to dig into some of that. [00:00:38]
Dylan: Yeah. Thank you so much. I've been doing consulting in the industry, semiconductor industry since 17. 2021 got bored and in November I started writing a blog and then like 2022 I was good and started hiring folks for my firm. And then all of a sudden 2023 happens and it's like the perfect intersection. I used to do data science, but not like AI, not really like multivariable progression is not AI. Right. But also I've been involved in the semiconductor industry for a long, long time, posting about it online since I was 12. Right. You know, all of a sudden this all kind of came to fruition. So it's cool to have the blog sort of blow up in that way. [00:01:11]
Swyx: I used to cover semis at Belyasny as well. And it was for a long time, it was just the mobile cycle. And then a little bit of PCs, but like not that much. And then maybe some cloud stuff, you know, like public cloud, you know, semiconductor stuff. But it really wasn't anything until this wave. And I was actually listening to you on one of the previous podcasts that you've done. And it was surprising that high-performance computing also kind of didn't really take off. Like AI is just the first form of high-performance computing that worked. [00:01:37]
Dylan: One of the theses I've had for a long time that I think people haven't really caught on, but it's coming to fruition now is that the largest tech companies in the world, their software is important, but actually having and operating a very efficient infrastructure is incredibly important. And so, you know, people talk about, you know, hey, Amazon is great, AWS is great because yes, it is easy to use and they've built all these things. But behind the scenes, they've done a lot on the infrastructure that is super custom that Microsoft, Azure and Google Cloud just don't even match in terms of efficiency. If you think about the cost to rent out SSD space, so the cost to rent, you know, offer database service on top of that, obviously, a cost to rent out a certain level of CPU performance. Amazon has a massive advantage there. And likewise, like Google spent all this time doing that in AI, right, with their TPUs and infrastructure there and an optical switches and all this sort of stuff. And so in the past, it wasn't immediately obvious. I think with AI, especially like how scaling laws are going, it's like incredibly important for infrastructure is like so much more important. And then like when you just think about software cost, right, like the cost structure of it, there was always a bigger component of R&D and like SAS businesses, you know, all over SF, all these SAS businesses did crazy good because, you know, they just start as they grow and then all of a sudden they're so freaking profitable for each incremental new customer. And AI software looks like it's going to be very different, in my opinion, right? Like the R&D cost is much lower in terms of people, but the cost of goods sold in terms of actually operating the service, I think will be much higher. And so in that same sense, infrastructure matters a ton. [00:03:02]
Swyx: And I think you wrote once that training costs effectively don't matter. [00:03:06]
Dylan: Yeah. In my opinion, I think that's a little bit spicy, but yeah, it's like training costs are irrelevant, right? Like GPT-4, right, like 20,000 A100s, that's, that's like, I know it sounds like a lot of money. The supercomputer, it's, it's, oh, it's slightly more, but yeah, I think the 500 million is a fair enough number. I mean, if you think about just the pre-training, right, three months, 20,000 A100s at, you know, a dollar an hour is like, that is way less than 500 million, right? But of course there's data and all this sort of stuff. [00:03:33]
Alessio: So people that are watching this on YouTube, they can see a GPU-poor and a GPU-rich hat on the table, which is inspired by your, yeah, your Google Gemini, it's the world blog post. So Sam, did you know that this thing was going to blow up so much? Sam Altman even tweeted about it, he said, incredible Google got the semi-analysis guide to publish their internal marketing recruiting chart. And yeah, tell people who are the GPU-poors, who are the GPU-rich, like what's this framework that they should think about? [00:04:01]
Dylan: So it's, it's, you know, some of this work we've been doing for a while is just on infrastructure and like, hey, like when something happens, I think it's like a sort of competitive advantage of our firm, right, myself and my colleagues is we go from software all the way through to like low-level manufacturing, and it's like, who, you know, oh, Google's actually ramping up TPU production massively, right? And like, I think people in AI would be like, well, duh, but like, okay, like who, who has the capability of figuring out the number? Well, one, you could just get Google to tell you, but they don't, they won't tell you, right? That's like a very closely guarded secret. And most people that work at Google DeepMind don't even know that number, right? Two, you go through the supply chain and see what they've placed in order. Three is sort of like, well, who's actually winning from this? Hey, oh, Celestica's building these boxes. Wow. Oh, interesting. Oh, Google's involved in testing for them. Oh, okay. Oh, this company's providing design IP to them. Okay. That's very valuable in a monetary sense, but you know, you have to understand the whole technology stack. But on the flip side, right, is, well, why is Google building all these? What could they do with it? And what does that mean for the world? Especially in SF, right? Like, I'm sure you folks have been to parties. If we just brag about how many TPUs they have, like, it's happened to me multiple times where someone's just like, I'm just witnessing a conversation where somebody from Meta is bragging about how many TPUs they have versus someone from another firm that it's like, or like a startup person's like, dude, can you believe we just acquired, we have 512 H100s coming online in August. And it's like, oh, cool. Like, you know, going through the supply chain, it's like, dude, you realize there's 400,000 manufactured last quarter and like 530,000 this quarter being sold of H100s. And it's like, oh crap, that's a lot. That's a lot of GPUs. But then like, oh, how does that compare to Google? And like, there's one way to look at the world, which is just like, hey, scale is all you need. Like obviously data matters. Obviously all this stuff matters. I think any data set, a larger model will just do better. I think it's going to be more expensive, but it's going to do better. Okay, there's all these GPUs going into production. NVIDIA is going to sell well over 3 million total GPUs next year, over a million H100s this year alone. There's a lot of GPU capacity coming online. It's an incredible amount. And well, what are people doing? What are people working on? I think it's very important to like, just think about what are people working on, right? What actually are you building that's going to advance? What is monetizable? But what also makes sense? And so like, a lot of people were doing things that I felt counterproductive, right? In a world where in less than a year, there's going to be more than 4 million high-end GPUs out there. I mean, we can talk about the concentration of those GPUs, but if you're doing really valuable work as a good person, right, like you're contributing in some way, should you be focused on like, well, I don't have access to any of those 4 million GPUs, right? I actually only have access to gaming GPUs. Should I focus on like being able to fine tune a model on that, right? Like, no, it's not really that important. Or like, should I be focused on batch one inference on a cloud GPU? Like, no, that's like pointless. Like, why would you do batch size one inference on an H100? That's just like ridiculously dumb. There's a lot of counterproductive work. And at the same time, there's a lot of things that people should be doing. I mean, obviously, most people don't have resources, right? And I love the open source and I want the open source to win. And I hate the people who want to like, no, we're X lab and we think this is the only way you should do it. And if people don't do it this way, they should be regulated against it and all this kind of stuff. So I want the open source to win, right? Like companies like Mistral and like what Meta are doing, you know, Mosaic and all these folks together. All these people doing, you know, huge stuff with open source, you know, want them to succeed. But it's like, there's certain things that are, you know, like hyper focusing on leaderboards and hugging face. No, like truthful QA is a garbage benchmark. Some of the models that are very high on there, if you use it for five seconds, you're like, this is garbage. There was things I wanted to say. Also, you know, we're in a world where compute matters a lot. Google is going to have more compute than any other company in the world, period. By like a large, large factor. It's just like framing it into that like mindset of like, Hey, like, what are the counterproductive things? What do I think personally? Or what have people told me that are involved in this should they focus on the pace of acceleration from 2020 to 2022 is less than 2022 to 2024, you know, GP two to four, two to four is like 2020 to 2022, right? Is less than I think from GPT four in 2022, which is when it was trained, right? What open AI and Google and, and Anthropic do in 2025, right? Like I think the pace of acceleration is increasing and it's just good to like, think about, you know, that sort of stuff. [00:08:12]
Alessio: That makes sense. And the chart that Sam mentioned is about, yeah, Google TPU B fives completely overtaking open AI by orders of magnitude. Let's talk about the TPU a bit. We had Tris Landner on the show, which I know, you know, he used to work on TensorFlow and Google. And he did mention that the goal of Google is like make TPUs go fast with TensorFlow, but then he also had a post about PyTorch dealing the thunder. How do you see that changing? If like, now that a lot of the compute will be TPU based and Google wants to offer some of that to the public to Google internally. [00:08:44]
Dylan: And I think, you know, as obviously on JAX and XLA and all that kind of stuff externally, like they've done a really good job. Wouldn't say like TPUs through PyTorch XLA is amazing, but it's, it's not bad, right? Like some of the numbers they've shown, some of the, you know, code they've shown for TPU V5E, which is not the TPU V5 that I was referring to, which is in the sort of the post, the TPU poor post is referring to, but TPU V5E is like the new one, but it's mostly, mostly an inference chip. It's a small chip. It's, it's about half the size of a TPU V5. That chip, you know, you can get very good performance on of LLAMA 70B inference. Very, very good performance when you're using PyTorch and XLA. Now of course you're going to get better if you go JAX XLA, but I think Google is doing a really good job after the restructuring of focusing on external customers too. Probably won't focus too much on TPU V5 for everyone externally, but V5E, we're also building a million of those, right? Hey, a lot of companies are using them, right? Or will be using them because it's going to be an incredibly cheap form of compute. I think the world of frameworks and all that, right? Like that's obviously something a researcher should talk about, not myself, but you know, the stats are clear that PyTorch is way, way dominating everything. But JAX is like doing well. Like there's external users of JAX. The forever shouldn't be that the person doing PyTorch level code, right? That high should also be writing custom CUDA kernels, right? There should be, you know, different layers of abstraction where people hyper optimize and make it much easier for everyone to innovate on separate stacks, right? And then every once in a while, someone comes through and pierces through the layers of abstraction and innovates across multiple or a group of people. But I think frameworks are important. Compilers are important, right? Chris Lattner's, what he's doing is really cool. I don't know if it'll work, but it's super cool and it certainly works on CPUs. We'll see about accelerators. Likewise, there's OpenAI's Triton, like what they're trying to do there. And you know, everyone's really coalescing around Triton, third-party hardware vendors. There's Palace. I don't want to mischaracterize it, but you can write in Palace and it'll go through, you can lower level code and it'll work to TPUs and GPUs, kind of like Triton, but it's like there's a backend for Triton. I don't know exactly everything about it, but I think there's a lot of innovation happening on make things go faster, right? How do you go burr? Is every single person working in ML, it would be a travesty if they had to write like custom CUDA kernels always, right? Like that would just slow down productivity, but at the same time, you kind of have to. [00:10:53]
Swyx: By the way, I like to quantify things when you say make things go burr. Is there a target range of MFU that you typically talk about? [00:10:59]
Dylan: Yeah, there's sort of two metrics that I like to think about a lot, right? So in training, everyone just talks about MFU, right? But then on inference, right, which I think is one LLM inference will be bigger than training or multimodal, whatever, bubble inference will be bigger than training, probably next year, in fact, at least in terms of GPUs deployed. And the other thing is like, you know, what's the bottleneck when you're running these models? The simple, stupid way to look at it is training is, you know, there's six flops floating point operations you have to do for every byte you read in, right? Every parameter you read in. So if it's FP8, then it's a byte, if it's FP16, it's two bytes, whatever, right? On training, but on inference side, the ratio is completely different. It's two to one, right? There's two flops per parameter that you read in and parameters, maybe one byte, right? But then when you look at the GPUs, the GPUs are very, very different ratio. The H100 has 3.35 terabytes a second of memory bandwidth, and it has a thousand teraflops of FP16, BFLIP16, right? So that ratio is like, I'm sorry, I'm going to butcher the math here and people are going to think I'm dumb, but 256 to one, right, call it 256 to one if you're doing FP16. And same applies to FP8, right, because anyways, per parameter read to number of floating point operations, right? If you quantize further, but you also get double the performance on that lower quantization. That does not fit the hardware at all. So if you're just doing LLM inference at batch one, then you're always going to be under utilizing the flops. You're only paying for memory bandwidth. And the way hardware is developing, that ratio is actually only going to get worse. H200 will come out soon enough, which will help the ratio a little bit, improve memory bandwidth more than improves flops, just like the A180 gig did versus the A140 gig. But then when the B100 comes out, the flops are going to increase more than memory bandwidth. And when future generations come out and the same with AMD side, right, MI300 versus 400, as you move on generations, just due to fundamental like semiconductor scaling, DRAM memory is not scaling as fast as logic has been. And you can do a lot of interesting things on the architecture. So you're going to have this problem get worse and worse and worse. And so on training, it's very, you know, who cares, right? Because my flops are still my bottleneck most of the time. I mean, memory bandwidth is obviously a bottleneck, but like, well, you know, batch sizes are freaking crazy, right? Like people train like 2 million batch sizes, it's trivial, right? Like that's what Lama, I think did, Lama 70B was 2 million batch size. Unlike you talk to someone at one of the frontier labs and they're like, just 2 million, 2 million token batch size, right? That's crazy, or sequence, sorry. But when you go to inference side, well, it's impossible to do one, to do 2 million batch size. Also your latency would be horrendous if you tried to do something that crazy. So you kind of have this like differing problem where on training, everyone just kept talking MFU, model flop utilization, right? How many flops, six times the number of parameters, basically, more or less. And then what's the quoted number, right? So if I have 312 teraflops out of my A100 and I was able to achieve 200, that's really good, right? You know, some people are achieving higher, right? Some people are achieving lower. That's a very important like metric to think about. Now you have like people thinking MFU is like a security risk, but on inference, MFU is not nearly as important, right? It's memory bandwidth utilization. You know, batch one is, you know, what memory bandwidth can I achieve, right? Because as I increase batch from batch size one to four to eight to even 256, right, it's sort of where the crossover happens on an H100 inference wise, where it's flops limiting you more and more. But like you should have very high memory bandwidth utilization. So when people talk about A100s, like 60% MFU is decent. On H100s, it's more like 40, 45% because the flops increased more than the memory bandwidth. But people over time will probably get above 50% on H100, on MFU, on training. But on inference, it's not being talked about much, but MBU, model bandwidth utilization is the important factor, right? Above my 3.35 terabytes a second memory bandwidth on my H100, can I get two? Can I get three? Right? That's the important thing. And right now, if you look at everyone's inference stuff, I dogged on this in the GPU poor thing, right? But it's like hugging faces libraries are actually very inefficient, like incredibly inefficient for inference. You get like 15% MBU on some configurations, like eight A100s and LLAMA 70B, you get like 15%, which is just like horrendous. Because at the end of the day, your latency is derived from what memory bandwidth you can effectively get, right? So if you're doing LLAMA 70 billion, 70 billion parameters, if you're doing it int8, okay, that's 70 gigabytes a second, gigabytes you need to read for every single inference, every single forward pass, plus the attention, but again, we're simplifying it. 70 gigabytes you need to read for every forward pass, what is an acceptable latency for a user to have? I would argue 30 milliseconds per token. Some people would argue lower, right? But at the very least, you need to achieve human reading level speeds and probably a little bit faster, because we like their skin, to have a usable model for chatbot style applications. Now there's other applications, of course, but chatbot style applications, you want it to be human reading speed. So 30 tokens per second, 30 tokens per second is 33, or 30 tokens, milliseconds per token is 33 tokens per second, times 70 is, let's say three times seven is 21, and then add two zeros to 2,100 gigabytes a second, right? To achieve human reading speed on LLAMA 70B, right? So one, you can never achieve LLAMA 70B human reading speed on, even if you had enough memory capacity on a model, on an A100, right? Even an H100 to achieve human reading speed, right? Of course, you couldn't fit it because it's 80 gigabytes versus 70 billion parameters, so you're kind of butting up against the limits already, 70 billion parameters being 70 gigabytes at int8 or fp8. You end up with one, how do I achieve human reading level speeds, right? So if I go with two H100s, then now I have, you know, call it six terabytes a second of memory bandwidth, if I achieve just 30 milliseconds per token, then I'm, you know, which is 33 tokens per second, which is 30, you know, is three terabytes a second, was it three, three times, 21, 2.1 terabytes a second of memory bandwidth, then I'm only at like 30% bandwidth utilization. So I'm not using all my flops on batch one anyways, right? Because 70, you know, the flops that you're using there is tremendously low relative to inference, and I'm not actually using a ton of the tokens on inference. So with two H100s, I only get 30 milliseconds a token, that's a really bad result. You should be striving to get, you know, so upwards of 60%, and that's like 60% is kind of low too, right? Like, I've heard people getting 70, 80% model bandwidth utilization. And then, you know, obviously you can increase your batch size from there and your model bandwidth utilization will start to fall as your flops utilization increases, but, you know, you have to pick the sweet spot for where you want to hit on the latency curve for your user. Obviously, as you increase batch size, you get more throughput per GPU, so that's more cost effective. There's a lot of like things to think about there, but I think those are sort of the two main things that people want to think about, and there's obviously a ton with regards to like networking and inner GPU connection, because most of the useful models don't run on a single GPU. They can't run on a single GPU. [00:17:37]
Swyx: Is there a TPU equivalent of Mellanox? [00:17:39]
Dylan: The Google TPU is like super interesting because Google has been working with Broadcom, who's the number one networking company in the world, right? So Mellanox was nowhere close to number one. They had a niche that they were very good at, which was the network card, the card that you actually put in the server, but they didn't do much. They didn't have, they weren't doing successfully in the switches, right? Which is, you know, you connect all the networks cards to switches, and then the switches to all the servers. So Mellanox was not that great. I mean, it was good. They were doing good, and NVIDIA bought them, you know, in 19, I believe, or 18, but Broadcom has been number one in networking for a decade plus, and Google partnered with them on making the TPU, right? So Google does a lot of the design, especially on the ML hardware side, on how you pass stuff around internally on the chip, but Broadcom does a lot on the network side, right? They specifically, how to get really high connection speed between two chips, right? They've done a ton there, and obviously Google works a ton there too, but this is sort of Google's like less discussed partnership that's truly critical for them, and Google's tried to get away from them many times. Their latest target to get away from Broadcom is 2027, right? But like, you know, that's four years from now. Chip design cycle's four years, so they already tried to get away in 2025, and that failed. They have this equivalent of very high speed networking. It works very differently than the way GPU networking does, and that's important for people who code on a lower level. [00:18:52]
Swyx: I've seen this described as the ultimate rate limit on how big models can go. It's not flops, it's not memory, it's networking. Like it has the lowest scaling laws, the lowest Moore's laws, and I don't know what to do about that because no one else has any solutions. [00:19:06]
Dylan: Yeah, yeah, so I think what you're referring to is that like network speed is increased Much slower than the other two. Than flops, yeah, and bandwidth, yeah, yeah. And yeah, that's a tremendous problem in the industry, right? That's why NVIDIA bought a networking company, that's why Broadcom is working on Google's chip right now, but of course on Meta's internal AI chip, which they're on the second generation of, working on that, and what's the main thing that Meta's doing interesting is networking stuff, right? Multiplying tensors is kind of, there's a lot of people who've made good matrix multiply units, right? But it's about like getting good utilization out of those and interfacing with the memory and interfacing with other chips really efficiently makes designing these chips very hard. Most of the startups obviously have not done that really well. [00:19:46]
Alessio: I think the startup's point is the most interesting, right? You mentioned companies that are GPU poor, they raise a lot of money, and there's a lot of startups out there that are GPU poor and did not raise a lot of money. What should they do? How do you see like the space dividing? Are we just supposed to wait for like the big labs to do a lot of this work with a lot of the GPUs? What's like the GPU poor's beautiful version of the article? [00:20:12]
Dylan: Open AI, who everyone would be like, oh yeah, they have more GPUs than anyone else, right? But they have a lot less flops than Google, right? That was the point of the thing, but not just them, it's like, okay, it's like a relative totem pole, right? And of course, Google doesn't use GPUs as much for training and inference, they do use some, but mostly TPUs. So kind of like, the whole point is that everyone is GPU poor because we're going to continue to scale faster and faster and faster and faster, and compute will always be a bottleneck, just like data will always be a bottleneck. You can have the best data set in the world and you can always have a better one. And same with, you have the biggest compute system in the world, but you'll always want a better one. And so it's like, there's things that like Mistral, they trained a fricking awesome model on relatively fewer GPUs, right? And now they're scaling up higher and higher and higher, right? There's a lot that the GPU poor can do though, right? We all have phones, we all have laptops, right? There is a world for running GPUs or models on device. The replet folks are trying to do stuff like that. Their models, they can't follow scaling laws, right? Why? Because there's a fundamental limit to how much memory bandwidth and capacity you can get on a laptop or a phone. You know, I mentioned the ratio of flops to bandwidth on a GPU is actually really good compared to like a MacBook or like a phone. To run Llama 70 billion requires two terabytes a second of memory bandwidth, 2.1 at human reading speed. Yeah, but my phone has like 50 gigabytes a second. Your laptop, even if you have an M1 Ultra has what, like, I don't remember, like a couple hundred gigabytes a second of memory bandwidth. You can't run Llama 70B just by doing the classical thing. So there's like, there's stuff like speculative decoding, you know, together did something really cool. And they put it in the open source, of course, Medusa, right? Like things like that, that are, you know, they work on batch size one, they don't work on batch size, you know, high. And so there's like the world of like cloud inference. And so in the cloud, it's all about what memory bandwidth and MFU I can achieve. Whereas on the edge, I don't think Google is going to deploy a model that I can run on my laptop to help me with code or help me with, you know, X, Y, Z, they're always going to want to run it in a cloud for control. Or maybe they let it run on the device, but it's like only their pixel phone, you know, it's kind of like a walled garden thing. There's obviously a lot of reasons to do other things for security, for openness, to not be at the whims of a trillion dollar plus company who wants my data, right? You know, there's a lot of stuff to be done there. And I think folks like Repl.it, they open source their model, right? Things like together, I just mentioned, right, that developing Medusa, that didn't take much GPU at all, right? That's very, well, they do have quite a few GPUs, they made a big announcement about having 4,000 H100s, that's still relatively poor, right, when we're talking about hundreds of thousands of like the big labs, like OpenAI, and so on and so forth, or millions of TPUs like Google, but still, they were able to develop Medusa with probably just one server, one server with eight GPUs in it. And its usefulness of something like Medusa, something like speculative decoding is, is on device, right? And that's what like a lot of people can focus on, you know, people can focus on all sorts of things like that. I don't know, right? Like a new model architecture, right? Like, are we only going to use transformers? I'm pretty told to think like transformers are it, right? My hardware brain can only know something that loves hardware, right? People should continue to try and innovate on that, right? Like, you know, asynchronous training, right? Like that kind of stuff is like, super, super interesting. I think it's Tim Demeters. He had like the- Demeers? [00:23:09]
Swyx: The same guy as Kylo Ren. [00:23:10]
Dylan: Yes, he had the swarm paper and petal. That research is super cool. The universities will never have much compute, but like, hey, to prepare to do things to, you know, all these sorts of stuff, like they should try to build, you know, super large models. Like, you look at what Tsinghua University is doing in China, actually, they open sourced their model to I think the largest like by parameter count, at least open source models. I mean, of course, they didn't train it on much data, but it's like, you know, it's like you could do some cool stuff like that. I don't know. I think there's a lot that people can focus on. One, scaling out a service to many, many users. Distribution is very important. So figuring out distribution, right? Like figuring out useful fine tunes, right? Like doing LLMs that OpenAI will never make, sorry for the crassness, a porn DALL-E 3, right? Open source is doing crazy stuff with stable diffusion, right? Right? Like, I don't know. Yeah, but it's like, it's like, and there's a legitimate market. I think there's a couple of companies who make tens of millions of dollars of revenue from LLMs or diffusion models for porn, right? Or, or, you know, that kind of stuff. Like, I mean, there's a lot of stuff that people can work on that will be successful businesses or doesn't even have to be a business, but can advance humanity tremendously. That doesn't require crazy scale. [00:24:10]
Alessio: How do you think about the depreciation of like the hardware versus the models? If you buy a H100, sure, the next year's is going to be better, but like at least the hardware is good. If you're spending a lot of money on like training a smaller model, it might be like super obsolete in like three months. And you've got now all this compute coming online. I'm just curious if like companies should actually spend the time to like, you know, fine tune them and like work on them where like the next generation is going to be out of the box so much better. [00:24:37]
Dylan: Unless you're fine tuning for on-device use, I think fine tuning current existing models, especially the smaller ones is a useless waste of time because the cost of inference is actually much cheaper than you think once you achieve good MBU and you batch at a decent size, which any successful business in the cloud is going to achieve, you know, and then two, fine tuning like people like, oh, you know, this 7 billion parameter model, if you fine tune it on a data set is almost as good as 3.5, right? Why don't you fine tune 3.5 and look at your performance, right? And like, there's nothing open source that is anywhere close to 3.5 yet. There will be. People also don't quite grasp. Falcon was supposed to be, Falcon 140B. It's less parameters than 3.5. And also, I don't know about the exact token count, but I believe it. Do we know the parameters of 3.5? It's not 175 billion. People keep saying this. [00:25:25]
Swyx: No. Because we know 3, but we don't know 3.5. [00:25:27]
Dylan: 3.5. [00:25:28]
Swyx: It's definitely smaller. [00:25:29]
Dylan: No, it's bigger than 175. I think it's sparse. MOE. I'm pretty sure. And yeah, you can, you can do some like gating around the size of it by looking at their inference latency. Well, what's the theoretical bandwidth if they're running it on this hardware and doing tensor parallel in this way? So they have this much memory bandwidth and maybe they get, maybe they're awesome and they get 90% memory bandwidth utilization. I don't know. That's an upper bound and you can see the latency that 3.5 gives you, especially at like off peak hours or if you do fine tuning and you have your, if you have a private enclave, they'll like my Azure will quote you latency. So you can, you can figure out how many parameters per forward pass, which I think is somewhere in the like 50 to 40 billion range, but I could be very wrong. That's just like my guess based on that sort of stuff. You know, 50 ish. And actually I think open source will have models of that quality. I mean, I assume Mosaic or like Meadow will open source and Mistral will be able to open source models of that quality. And furthermore, right? Like if you just look at the amount of compute, obviously data is very important and the ability, all these tricks and dials that you turn to be able to get good MFU and good MBO, right? Like depending on inference or training is, there's a ton of tricks. But at the end of the day, there's like 10 companies that have enough compute in one single data center to be able to beat GPT-4, right? Like straight up, like if not today, within the next six months, right? 4,000 H100s is, I think you need about 7,000 maybe. And with some algorithmic improvements that have happened since GPT-4 and some data quality improvements probably, like you could probably get to even like less than 7,000 H100s running for three months to beat GPT-4. Of course, that's going to take a really awesome team, but there's quite a few companies that are going to have that many, right? Open source will match GPT-4, but then it's like, what about GPT-4 Vision? Or what about, you know, 5 and 6 and all these kinds of stuff and like interact tool use and Dolly and like, that's the other thing is like, there's a lot of stuff on tool use that the open source could also do, that the GPT-4 could do. I think there are some folks that are doing that kind of stuff, agents and all that kind of stuff. I don't know. That's way over my head, the agent stuff. [00:27:24]
Swyx: Yeah, it's over everyone's head. One more question on this sort of Gemini GPU rich essay. We've had a very wide ranging conversation already, so it's hard to categorize, but I tried to look for the Meena Eats the World document. Oh, it's not public. [00:27:36]
Dylan: No, no, no, no, no, no. You've read it. Yeah, I read it. So Noam Shazir is like, I don't know, I think he's like- The GOAT. The GOAT. Yeah, I think he's the GOAT. [00:27:46]
Swyx: In one year, he published like switch transformers, like some attention is all you need, obviously, but he also did the speculative decoding stuff. [00:27:53]
Dylan: Yeah, exactly. It's like, it's like all this stuff that we were talking about today was like, you know, and obviously there's other people that are awesome that were, you know, helping and all that sort of stuff. Meena Eats the World was basically, he wrote an internal document around the time where Google had Meena, right? But it was like, he wrote it and he was like, basically predicting everything that's happening now, which is that like large language models are going to eat the world, right? In terms of, you know, compute and he's like the total amount of deployed flops within Google data centers will be dominated by large language models. Back then, a lot of people thought he was like silly for that, right? Like internally at Google. But you know, now if you look at it, it's like, oh wait, millions of TPUs. You're right. You're right. You're right. Okay. We're totally getting dominated by like both, you know, Gemini training and inference, right? Like, you know, total flops being dominated by LLMs is completely right. [00:28:36]
Swyx: So my question was, he had a bunch of predictions in there. Do you think there were any like underrated predictions that may not have yet have come true? Was he wrong on anything? [00:28:44]
Dylan: Meena sucked, right? If you'd look at the total flops, right? You know, parameters times tokens times six, it's like tiny, tiny fraction of GPT-2, which came out just a few months later, which was like, okay, so he was right about everything, but like, maybe he knew about GPT-2. I have no clue. OpenAI clearly was like way ahead of Google on LLM scaling. Even then, people didn't really recognize it back in GPT-2 days, maybe. The number of people that recognized it was maybe hundreds, tens. [00:29:10]
Alessio: So we talked about transformer alternatives. The other thing is GPU alternatives. The CPU is obviously one, but there's Cerebras, there's Graphcore, there's MAD-X, Lemurian Labs, there's a lot of them. Thoughts on what's real, who's alive, who's kind of like a zombie company walking. [00:29:27]
Dylan: You know, I mentioned like transformers were the architecture that won out, but I think, you know, the number of people who recognized that in 2020 was, you know, as you mentioned, probably hundreds, right? For natural language processing, maybe in 2019 at least, right? You think about a chip design cycle, it's like years, right? So it's kind of hard to bet your architecture on the type of model that develops. But what's interesting about all the first wave AI hardware startups, you know, there's a ratio of memory, capacity, compute, and memory bandwidth, right? Everyone kind of made the same bet, which is, I have a lot of memory on my chip, which is A, really dumb, because the models have grew way past that, right? Even Cerebras, right? You know, like I'm talking about like Graphcore, it's called SRAM, which is the memory on chip, much lower density, but much higher speeds versus, you know, DRAM, memory off chip. And so everyone was betting on more memory on chip and less memory off chip, right? And to be clear, right, for image networks and models that are small enough to just fit on your chip, that works. That is a superior architecture, but scale, right, scale, scale, scale, scale. NVIDIA was the only company that bet on the other side of more memory bandwidth and more memory capacity external, also the right ratio of memory bandwidth versus capacity. A lot of people like Graphcore specifically, right, that ton of memory on chip, and then they had a lot more memory off chip, but that memory off chip was a much lower bandwidth. Same applies to Samanova, same applies to Cerebras. They had no memory off chip, but they thought, hey, I'm going to make a chip the size of a wafer, right? Like, you know, those guys, they're silly, right? Hundreds of megabytes, we have 40 gigabytes. There's no, you know, and then, oh, crap, models are way bigger than 40 gigabytes, right? The ones that people deploy. Everyone bet on sort of the left side of this curve, right? The interesting thing is that there's new age startups like Lumerium, like MedEx, I won't get into what they're doing, but they're making much more rational bets. I don't know, you know, it's hard to say with a startup, like, it's going to work out, right? Obviously there's tons of risk embedded, but those folks, you know, Jay Duane of Lumerium and like Mike and Rainier, they understand models, they understand how they work. And if transformers continue to reign supreme, whatever innovations those folks are doing on hardware are going to need to be fitted for that. Or you have to predict what the model architecture is going to look like in a few years, right? You know, and hit that spot correctly. So that's kind of a background on those. But like now you look today, hey, Intel bought Nirvana, which was Naveen Rao's Mosaic ML. He started Mosaic ML and sold it to Databricks recently, obviously leading LLMs and stuff there, AI there. Intel bought that company from him and then shut it down and bought this other AI company. And now that company is kind of, you know, got new chips. They're going to release a better chip than the H100 within the next quarter or so. AMD, they have a GPU, MI300, that will be better than the H100 in a quarter or so. Now that says nothing about how hard it is to program it, but at least hardware-wise on paper, it's better. Why? Because it's, you know, a year and a half later, right, than in the H100 or a year later than the H100, of course, and, you know, a little bit more time and all that sort of stuff. But they're at least making similar bets on memory bandwidth versus flops versus capacity. Following NVIDIA's lead, the questions are like, what is the correct bet for three years from now? How do you engineer that? And will those alternatives make sense? The other thing is, if you look at total manufacturing capacity, right, for this sort of bet, right, you need high bandwidth memory, you need HBM, and you need large five nanometer dies, you know, soon three nanometer, whatever, right? You need both of those components and you need the whole supply chain to go through that. We've written a lot about it, but, you know, to simplify it, NVIDIA has a little bit more than half and Google has like 30%, right, through Broadcom. So it's like the total capacity for everyone else, much lower, and they're all sharing it, right? Amazon's training and inferentia, Microsoft's in-house chip, and, you know, you go down the list and it's like Meta's in-house chip, and also AMD, and also, so all of these companies are sharing like a much smaller slice. Their chips are not as good, or if they are, even though, you know, I mentioned Intel and AMD's chips are better, that's only because they're throwing more money at the problem kind of, right? You know, NVIDIA charges crazy prices, I think everyone knows that. Their gross margins are insane. AMD and Intel and others will charge more reasonable margins, and so they're able to give you more HBM and et cetera for a similar price, and so that ends up letting them beat NVIDIA, if you will, but their manufacturing costs are twice that in some cases, right? In the case of AMD, their manufacturing costs are MI300 or more than twice that of H100, and it only beats H100 by a little bit from, you know, performance stuff I've seen. So it's like, you know, it's tough for anyone to like bet the farm on a alternative hardware supplier, right? Like, in my opinion, like, you should either just like be like, you know, a lot of like ex-Google startups are just using TPUs, right? And hey, that's Google Cloud, you know, after moving the TPU team into the cloud team, infrastructure team, sort of, they're much more aggressive on external selling, and so you companies like, even see companies like Apple using TPUs for training LLMs, as well as TPUs, but either bet heavily on TPUs, because that's where the capacity is, bet heavily on GPUs, of course, and stop worrying about it, and leverage all this amazing open source code that is optimized for NVIDIA. If you do bet on AMD or Intel or any of these startups, then you better make damn sure you're really good at low-level programming, and damn sure you also have a compelling business case, and that the hardware supplier is giving you such a good deal that it's worth it. And also, by the way, NVIDIA's releasing a new chip in, you know, they're going to announce it in March, and they're going to release it and ship it Q2, Q3 next year anyways, right? And that chip will probably be three or four times as good, right? And maybe it'll cost twice as much, or 50% more. I hear it's 3x the performance on an LLM, and 50% more expensive, is what I hear. So it's like, okay, yeah, nothing is going to compete with that, even if it is 50% more expensive, right? And then you're like, okay, well, that kicks the can down further, and then NVIDIA's moving to a yearly release cycle, so it's like very hard for anyone to catch up to NVIDIA, really, right? So, you know, investing all this in other hardware, like, if you're Microsoft, obviously, who cares if I spend $500 million a year on my internal chip? Who cares if I spend $500 million a year on AMD chips, right? Like, if it lets me knock the price of NVIDIA GPUs down a little bit, puts the fear of God within Jensen Huang, right, like, you know, then it is what it is, right? And likewise, you know, with Amazon, and so on and so forth, you know, of course, their hope is that their chips succeed, or that they can actually have an alternative that is much cheaper than NVIDIA. To throw a couple hundred million dollars at a company, you know, as product is completely reasonable. And in the case of AMD, I think it'll be more than a couple hundred million dollars, right? But yeah, I think alternative hardware is like, it really does hit like sort of a peak hype cycle, kind of end of this year, early next year, because all NVIDIA has is H100, and then H200, which is just better, more memory bandwidth, higher memory capacity, H100, right? But that doesn't beat what, you know, AMD are doing, it doesn't beat what, you know, Intel's Gaudi 3 does, but then very quickly after, NVIDIA will crush them. And then those other companies are gonna take two years to get to their next generation. You know, it's just a really tough place. And no one besides, you know, the main thing about hardware is like, hey, that bet I talked about earlier is like, you know, that's very oversimplified, right? Just memory bandwidth flops and memory capacity. There's a whole lot more bets. There's 100 different bets that you have to make and guess correctly to get good hardware, not even have better hardware than NVIDIA get close to them. And that takes understanding models really, really well. That takes understanding so many different aspects, whether it's power delivery or cooling or design, layout, all this sort of stuff. And it's like, how many companies can do everything here, right? It's like, I'd argue Google probably understands models better than NVIDIA, I don't think people would disagree. I'm an NVIDIA understands hardware better than Google. And so you end up with like, Google's hardware is competitive, but like, does Amazon understand models better than NVIDIA? I don't think so. And does Amazon better understand hardware better than NVIDIA? No. I also have the opinion that the labs are useful partners, they're convenient partners. They're not going to buddy up as close as people think, right? I don't even think like, I expect in the next few years that the OpenAI Microsoft probably falls apart too. I mean, they'll still continue to use GPUs and stuff there. But like, I think that the level of closeness you see today is probably the closest they get. [00:37:15]
Swyx: At some point, they become competitive if OpenAI becomes its own cloud. [00:37:18]
Dylan: The level of value that they deliver to the world, if you talk to anyone there, they truly believe it'll be tens of trillions, if not hundreds of trillions of dollars, right? In which case, obviously, you know, I know weird corporate structure aside, you know, this is the same playing field as companies like Microsoft and Google. Google wants to also deliver hundreds of trillions of dollars of value. And it's like, obviously you're competing and Microsoft wants to do the same and you're going to compete. In general, right, like these lab partnerships are going to be nice, but they're probably incentivized to, you know, hey, NVIDIA, you should, you know, can you design the hardware in this way? It doesn't work like that. It works like this. And they're like, oh, so this is the best compromise. Right? Like, I think OpenAI would be stupid not to do that with NVIDIA, but also with AMD. But also, hey, like how much time, and Microsoft's internal silicon, but it's like, how much time do I actually have? Right? Like, you know, should I do that? Should I spend all my, you know, super, super smart people's time and limited, you know, this caliber of person's time doing that? Or should they focus on like, hey, can we get like asynchronous training to work? Or like, you know, figure out this next multimodal thing? Or I don't know. I don't know. Right? Right? Or should I eke out 5% more MFU and work on designing the next supercomputer? Right? Like, these kind of things, how much more valuable is that? Right? So it's like, you know, it's tough to see, you know, even OpenAI helping Microsoft enough to get their knowledge of models. So, so, so good. Right? Like, Microsoft's going to announce their chip soon. It's worse performance than the H100, but the cost effectiveness of it is better for Microsoft internally, just because they don't have to pay the NVIDIA tax. But again, like by the time they ramp it and all these sorts of things, and oh, hey, that only works on a certain size of models. Once you exceed that, then it's actually, you know, again, better for NVIDIA. So it's like, it's really tough for OpenAI to be like, yeah, we want to bet on, on Microsoft. Right? Like, and hey, we have, you know, I don't know, what's their number of people they have now? Like 700 people, you know, of which how many do low level code? Do I want to have separate code bases for this and this and this and this? And, you know, it's like, it's just like a big headache to, I don't know, I think it'd be very difficult to see anyone truly pivoting to anything besides a GPU and a TPU, especially if you have, if you need that scale. And that scale that the lab, at least the labs, right, require is absurd. Google says millions, right, of TPUs. OpenAI will say millions of GPUs, right? Like I truly do believe they think that that number of next generation GPUs, right? Like the numbers that we're going to get to are like, I bet you, I mean, I don't know, but I bet Sam Alton would say, yeah, we're going to build a hundred billion dollar supercomputer in three years or two years, right? And like after GPT-5 releases, if he goes to the market and says like, hey, I want to raise a hundred billion dollars at $500 billion valuation, I'm sure the market would give it to him, right? Like, and then they build that supercomputer, right? Like, I mean, like, I think that's like truly the path we're on. And so it's hard to, hard to imagine. Yeah. I don't know. [00:40:00]
Swyx: One point that you didn't touch on and Taiwan companies are famously very chatty about the fruit company. Should we take Apple seriously at all in this game or they're just in a different world altogether? [00:40:10]
Dylan: I respect their products, but like, I don't think Apple will ever release a model that you can get to say really bad things. There's all these jailbreaks, but also like as soon as they happen, like, you know, it gets fed back into OpenAI's like platform and it gets them, it's like being public and open is accelerating their like ability to make a better and better model, right? Like the RLHF and all this kind of stuff. I don't see how Apple can do that structurally, like as a company, like the fruit company ships perfect products or like, or else, right? That's why everyone loves iPhones, right? And all these like open source firms and like all these folks are doing exactly that, right? Building a bigger and better model every, you know, every few months. And I don't know how Apple gets on that train, but you know, at the same time, there's no company that has more powerful distribution, right? [00:40:56]
Swyx: Are people in Taiwan concerned that it will come to a point where China will just claim Taiwan? [00:41:02]
Dylan: I think, I think that a lot of people there are not super concerned, but there's some people that are super concerned. I think, I think especially after like, you know, instability across the world and in Europe and in the Middle East and even Africa, if you look at any of the stuff they're building up, it seems very clear. And if you talk to a lot of people, they think China will invade Taiwan in 27 or 26 in April or in September, sort of the best timeframes, right? Like a lot of people believe that's what will happen, right? [00:41:29]
Swyx: Maybe the semi-analysis analyst point of view is, is it feasible to build this capacity up in the US? No. [00:41:35]
Dylan: No, right? Like people don't understand how fragmented the semiconductor supply chain really is and how many monopolies there are. The US could absolutely shut down the Chinese semiconductor supply chain. They won't. But, and China could absolutely shut down the US one actually, by the way. But more, more relevantly, right, is like, you know, Austria has two companies, like the country of Austria and Europe has two companies that have super high market share and very specific technologies that are required for every single like, like chip period, right? There is no chip that is less than seven nanometer that doesn't get touched by this one Austrian company's tool, right? And there is no alternative. And there's another Austrian, you know, and I, it's, it's, and there's another Austrian company. Likewise, everything two nanometer and beyond will be touched by their tool. And it's like, but both of these companies are like doing well, less than a billion dollars of revenue, right? So it's like, you think it's so inconsequential. No, there's actually like three or four Japanese chemical companies, same, same idea, right? It's like the supply chain is so fragmented, right? Like people only ever talk about where the fabs were, where they actually get produced, but it's like, I mean, TSMC in Arizona, right? TSMC is building a fab in Arizona. It's, it's quite a bit smaller than the fabs in, in, in Taiwan. But even ignoring that, those fabs don't have to ship everything to Taiwan back anyways. And also they have to get what's called a mask from Taiwan and get sent to, get sent to Arizona. And by the way, there's these Japanese companies that make these chemicals that need to ship to, you know, like TOK and Shinetsu and, you know, it's like, and, and hey, it needs this tool from Austria no matter what it's like, oh wow, wait, actually like the entire supply chain is just way too fragmented. You can't like re-engineer and rebuild it on a snap, right? It's just like that. It's just complex to do that. Semiconductors are more complex than any other thing that humans do, without a doubt. There's more people working in that supply chain with XYZ backgrounds and more money invested every year and R&D plus CapEx, you know, it's like, it's just by far the most complex supply chain that humanity has. And to think that we could rebuild it in a few years is absurd. [00:43:22]
Swyx: In an alternate universe, the US kept Morris Chang. I mean, people, right? Like it was just one guy. Yeah. [00:43:29]
Dylan: In an alternative universe, Texas Instruments communicated to Morris Chang that he would become CEO. And so he never goes to Taiwan and you know, blah, blah, blah. Right. Yeah. No. But I, you know, that's just also, I think, I think the world would probably be further behind in terms of technology development if that didn't happen, right? Like technology proliferation is how you accelerate the pace of innovation, right? So the, you know, the dissemination to, oh, wow, hey, it's not just a bunch of people in Oregon at Intel that are leading everything, right? Or, you know, hey, a bunch of people in Samsung Korea, right? Or Shinshu, Taiwan, right? It's actually all three of those plus all these tool companies across the country and the Netherlands and in Japan and the US and, you know, it's millions of people innovating on a disseminated technology that's led us to get here, right? I don't even think, you know, if Morris Chang didn't go to Taiwan, would we even be at 5 nanometer? Would we be at 7 nanometer? Probably not, right? So there's a lot of things that, you know, happened because of that, right? [00:44:22]
Alessio: Let's get a quick lightning round on semi-analysis branded one. So the first one is what are like foundational readings that people that are listening today should read to get up to speed on like semis? [00:44:34]
Dylan: I think the easiest one is the PyTorch 2.0 and Triton one that I did. You know, there's the advanced packaging series. There's the Google infrastructure supremacy piece. I think that one's really critical because it explains Google's infrastructure quite a bit from networking through chips, through all that sort of history of the TPU a little bit. Maybe like AMD's MI300 piece, it talks a lot about the one that we did on that are very good. And then obviously like, you know, like, I don't know, probably like Chip Wars by Chris Miller who doesn't recommend that book, right? It's a really good book, right? I mean, like I would say Gordon Moore's book is freaking awesome because you got to think about right, like, you know, LLM scaling laws are like Moore's law on crack, right? Kind of like, you know, in a different sense, like, you know, if you think about all of human productivity gains since the 70s is probably just off of the base of semiconductors and technology, right? Of course, of course, people across the world are getting, you know, access to oil and gas and all this sort of stuff. But like, at least in the Western world, since the 70s, everything has just been mostly innovated because of technology, right? Oh, we're able to build better cars because semiconductors enable us to do that. Or be able to build better software because we're able to connect everyone because semiconductors enabled that, right? That is like, I think that's why it's the most important industry in the world. But like seeing the frame of mind of what Gordon Moore has written, you know, he's got a couple, you know, papers, books, et cetera, right? Only the paranoid survive, right? Like I think, I think like that philosophy and thought process really translates to the now modern times, except maybe, you know, humanity has been an exponential S-curve and this is like another exponential S-curve on top of that. So I think that's probably a good, good readings to do. [00:46:09]
Swyx: Has there been an equivalent pivot? So Gordon, like that classic tale was more of like the pivot to memory. [00:46:16]
Dylan: From memory to logic. Yeah. [00:46:18]
Swyx: Yeah. And then was there, has there been an equivalent pivot in Semi's history of that magnitude? [00:46:24]
Dylan: I mean, like, you know, some people would argue that like, you know, Jensen, you know, he basically didn't care about, he only cared about, you know, like gaming and 3D professional visualization and like rendering and things like that until like he started to learn about AI. And then all of a sudden he's going to like universities, like you want some GPUs, here you go. Right. Like, I think there's even stories of like, you know, not so long ago, NeurIPS, when it used to have the more unfortunate name, he would go there and just give away GPUs to people. Right. Like there's like stuff like that. Like, you know, very grassroots, like pivoting the company. Now like you, you look on gaming forums and it's like, everybody's like, oh, NVIDIA doesn't even care about us. They only care about AI and it's like, yes, you're right. They only care. They mostly only care about AI and the gaming innovations are only because of like, they're putting more AI into it. Right. It's like, but also like, hey, they're doing a lot of ship design stuff with AI. And, you know, I think, I think that's like, not, I don't know if it's equivalent pivot quite yet, but, you know, because the digital, you know, logic is a pretty big innovation, but I think that's a big one. And, you know, likewise, it's like, you know, what did, what did OpenAI do? Right. What did they pivot? How did they pivot? They left the, like, a lot of, most people left the culture of like Google brain and deep mind and decided to build this like company. That's crazy cool. Right. Like it does things in a very different way and like is innovating in a very different way. So you consider that a pivot, even though it's not inside Google. [00:47:40]
Swyx: They were on a very different path with like the Dota games and all that before they eventually found like GPTs as the, as the thing. So it was a full, like started in 2015 and then like really pivoted in 2019 to be like, all right, we're the GPT company. Yeah. Yeah. If I could classify them, I don't, I'm sure there's OpenAI people who are yelling at me right now. Okay. So just a general question about, you know, I'm a fellow writer on, on Substack. You are obviously managing your consulting business while you're also publishing these amazing posts. How do you, what's your writing process? How do you source info? Like when do you sit down and go like, here's the theme for the week. Do you, do you have a pipeline going out? Just anything you can describe. [00:48:17]
Dylan: I'm thankful for my, you know, my teammates cause they are actually awesome. Like, and they're much more, um, you know, directed focused to working on one thing, you know, or not one thing, but a number of things, right. Like, you know, someone who's this expert on X and Y and Z and the semiconductor supply chain. So that really helps with the, the, that side of the business. I most of the times only write when I'm very excited or, you know, it's like, Hey, like we should work on this and we should write about this. So like, you know, one of the most recent posts as we did was we explained the manufacturing process for 3D NAND, you know, flash storage, uh, gate all around transistors and 3D DRAM and all this sort of stuff. Cause there's a company in Japan that's going public, Kokusai Electric, right. It was like, okay, well we should do a post about this and we should explain this. But like, it's like, okay, we, you know, and so Myron, he did all that work, Myron and she, and most of the work and awesome. But like, usually it's like, there's a few, like very long in-depth back burner type things, right? Like that took a long time, took, you know, over a month of research and Myron knows this stuff already really well, right? Like there's stuff like that that we do and that like builds up a body of work for our consulting and some of the reports that we sell that aren't, you know, newsletter posts. But a lot of times the process is also just like, well, like Meena Eats the World is the culmination of reading that, having done a lot of work on the supply chain around the TPU ramp and co-osts and HBM capacities and all this sort of stuff to be able to, you know, figure out how many units and that Google's ordering all sorts of stuff. And then like, also like looking at like open sources, like all just that, all that culminated in like, I wrote that in four hours, right? I sent it to a couple of people and they were like, no, change this, this, this, oh, you know, add this. Cause that's really going to piss off, you know, the open source community. I'm like, okay, sure. And then posted it, right? So it's like, there's no like specific process. Unfortunately, like the most viral posts, especially in the AI community are just like those kinds of pieces rather than the, like the really deep, deep, like, you know, obviously like what was in the Gemini Eats the World post, you know, the obvious, Hey, like we, we do deep work and there's a lot more like factual, not leaks, you know, it's just factual research. Hey, we crossed the team. We go to 40 plus conferences a year, right. All the way from like a photo resist conference to a photo mask conference, to a lithography conference all the way up to like AI conferences and you know, all everything in between networking conferences and piecing everything across the supply chain. So it's like, that's like the true, like work and like, yeah, I don't know. It is sometimes bad to like have the infamousness of, you know, only people caring about this or the GPT-4 leak or the Google has no moat leak. Right. It's like, but like, you know, that's just like stuff that comes along. Right. You know, it's really focused on like understanding the supply chain and how it's pivoting and who's the winners, who's the losers, what technologies are inflecting, things like that. Where's the best place to invest resources, you know, sort of like stuff like that and in accelerating or capturing value, et cetera. [00:50:54]
Alessio: Awesome. And to wrap, if you had a magic genie that could answer any question that would change your worldview, what question would you ask? [00:51:03]
Dylan: That's a tough one. [00:51:04]
Swyx: Like you, you operate based on a set of facts about the world right now, then there's maybe some unknowns where you're like, man, if I really knew the answer to this one, I would do so many things differently, or I would think about things very differently. [00:51:18]
Dylan: So I'm of the view, at least everything that we've seen so far is that large scale training has to happen in an individual data center with very high speed networking. Now, everything doesn't need to be all to all connected, but you need very high speed networking between all of your, your chips, right? I would love to know, you know, hey, magic genie, how can we build artificial intelligence in a way that it can use multiple data centers of resources where there is a significantly lower bandwidth between pools of resources, right? Because that would instantly, like one of the big bottlenecks is how much power and how many chips you can get into a single data center. So like, A, Google and OpenAI and Anthropic are working on this, and I don't know if they've solved it yet, but if they haven't solved it yet, then what is the solution? Because that will like accelerate the scaling that can be done by not just like a factor of 10, but like orders of magnitude, because there's so many different data centers, right? Like if you, you know, across the world and, you know, oh, if I could pick up, you know, if I could effectively use 256 GPUs in this little data center here, and then with this big cluster here, you know, how can you make an algorithm that can do that? Like I think that would be like the number one thing I'd be curious to know if, how, what, because that changes the world significantly in terms of how we continue to scale this amazing technology that people have invented over the last, you know, five years. Awesome. [00:52:36]
Alessio: Well, thank you so much for coming on, Dylan. [00:52:38]
Dylan: Thank you. Thank you. [00:52:46]
Alessio: Thank you. [00:52:46]