


We will be recording a preview of the AI Engineer World’s Fair soon with swyx and Ben Dunphy, send any questions about Speaker CFPs and Sponsor Guides you have!
Alessio is now hiring engineers for a new startup he is incubating at Decibel: Ideal candidate is an ex-technical co-founder type (can MVP products end to end, comfortable with ambiguous prod requirements, etc). Reach out to him for more!
Giving computers a voice has always been at the center of sci-fi movies; “I’m sorry Dave, I’m afraid I can’t do that” wouldn’t hit as hard if it just appeared on screen as a terminal output, after all. The first electronic speech synthesizer, the Voder, was built at Bell Labs 85 years ago (1939!), and it’s…. something:
We will not cover the history of Text To Speech (TTS), but the evolution of the underlying architecture has generally been Formant Synthesis → Concatenative Synthesis → Neural Networks. Nowadays, state of the art TTS is just one API call away with models like Eleven Labs and OpenAI’s TTS, or products like Descript. Latency is minimal, they have very good intonation, and can mimic a variety of accents. You can hack together your own voice AI therapist in a day!
But once you have a computer that can communicate via voice, what comes next? Singing🎶 of course!
From Barking 🐶 to Singing 🎤
Today’s guest is Suno’s CEO and co-founder Mikey Shulman. He and his three co-founders, Georg, Martin, and Keenan, previously worked together at Kensho. One of their projects was financially-focused speech recognition (think earnings calls, etc), but all four of them happened to be musicians and audiophiles. They started playing around with text to speech + AI + audio generation and eventually left Kensho to work on it full time.
A lot of people when we started a company told us to focus on speech. If we wanted to build an audio company, everyone said, speech is a bigger market. But I think there's something about music that's just so human and you almost couldn't prevent us from doing it. Like we just couldn't keep ourselves from building music models and playing with them because it was so much fun.
Their first big product was Bark, the first open source transformer-based “text-to-audio” model (architecturally inspired by Karpathy’s NanoGPT) that went from 0 to ~19,000 Github stars in a month. At the time they felt like audio was years behind text and image as a generation modality; unlike its predecessors, Bark could not only generate speech, but also music and sound effects like crying, laughing, sighing, etc. You can find a few examples here.
The main limitation they saw was text to speech training data being extremely limited. So what they did instead is build a new type of foundation model from scratch, trained on audio, and then tweak it to do text to speech. Turning audio into tokens to do self-supervised learning was the most important innovation. Unlike TTS models which are very narrow (and often sound unnatural), Bark was trained on real audio of real people from broad contexts, which made it harder to output unnatural sounding speech.
As Bark got popular, more and more people started using it to generate music and it became clear that their architecture would work to generate music that people enjoyed, even though it might not be "on the AGI path” of other labs:
Everybody is so focused on LLMs, for good reason, and information processing and intelligence there. And I think it's way too easy to forget that there's this whole other side of things that makes people feel, and maybe that market is smaller, but it makes people feel and it makes us really happy.
Suno bursts on the scene
In December 2023, Suno went viral with a gorgeous new website and launch tweet:

And rave reviews:

Music is core to our culture, but very few people are able to create it; Mikey and team want to make everyone an active participant in music making, not just a listener. A “Midjourney of Music”, if you like.
We definitely had a lot of fun playing with Suno to generate all sort of Latent Space jingles and songs; the product is live at suno.ai if you want to get in the studio yourself!
If Nas joined Latent Space instead of The Firm:
182B models > Blink-182
The soundtrack of the post-scarcity Latent Space ranch
Scaling with Modal
Given the December launch, scaling up for the Christmas rush was a major concern. This will be a nice tie-in for loyal listeners - Suno runs on Modal (one of our featured guests from Compute Month)!
Suno V3
For those who want to appreciate someone special in their life, you can always try Suno’s special Valentines’ Day experience:
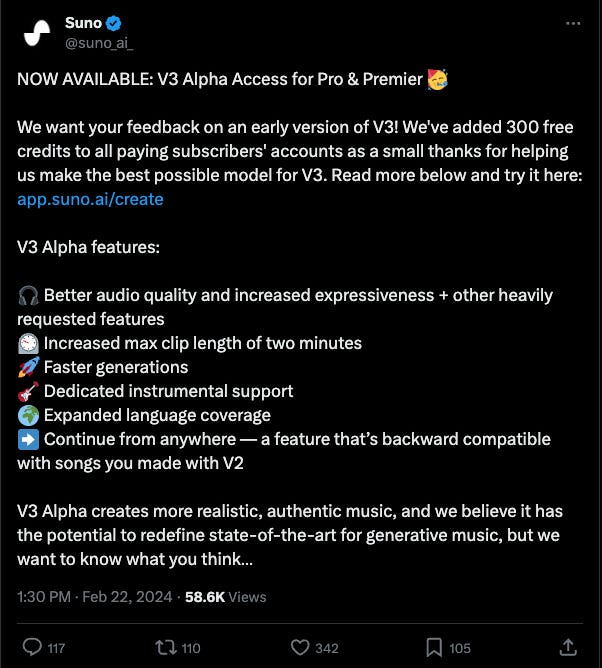
We preview this on the pod, but Suno has now officially shipped a V3 Alpha with a wealth of improvements:
and you’ll have to click through to their demos or user reviews to see:
We’ve recently become paying customers ourselves, and are having loads of fun generating music. If you have any of your own generations to share, tag @latentspacepod on Twitter or swing by the LS Discord!
The AudioGen Landscape
Mikey breaks down the landscape into 3 big categories: music, speech and sound effects (SFX). These look more like Venn diagrams than MECE categories.
Suno is the latest entry in a long series of audio generation efforts that combine both music and speech, reaching as far back as Tensorflow Magenta (we aren’t aware of prior AI music projects, please comment below if you can find a good timeline we can use with attribution!). Other efforts like Seamless blend translation and speech generation, and Audiobox combines speech and SFX, and Stable Audio offering both music and SFX. We’ve yet to see “one model to rule them all” but surely it will happen, and probably Transformers (perhaps Diffusion Transformers) will be at the heart of them.
Full Episode with Video Demo of Sumo
Join us on YouTube to see how Mikey uses Suno V3 live!
Show Notes
Timestamps
[00:00:00] Introduction
[00:01:44] State of Music Generation Models
[00:06:47] AI Data Wars & Copyright
[00:10:32] Going from ML in finance to music generation
[00:12:30] Suno's TTS origins with Bark and Parakeet
[00:16:25] Easy vs Expert mode for music
[00:21:44] The Midjourney of Music?
[00:23:43] Live demo
[00:36:00] Remaking vs Creating
[00:38:12] Suno's direction
[00:41:52] Beyond single track generation
[00:43:53] Favorite Suno usage in the wild
[00:46:00] The 2 mins overview of the audio generation space
[00:48:42] Benchmarking AI
Transcription
Alessio [00:00:01]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.
Swyx [00:00:10]: Hey, and today we are in the remote studio with Mikey Shulman. Welcome.
Mikey [00:00:16]: Thank you.
Swyx [00:00:17]: It's great to be here. So I'd like to go over people's background on LinkedIn and then maybe find out a little bit more outside of LinkedIn. You did your bachelor's in physics and then a PhD in physics as well, before going into Kensho Technologies, the home of a lot of top AI startups, it seems like, where you're head of machine learning for seven years. You're also a lecturer at MIT, we can talk about that, what you talked about. And then about two years ago, you left to start Suno, which is recently burst on the scene as one of the top music generation startups. So we can talk, we can go over that bio, but also I guess what's not in your LinkedIn that people should know about you?
Mikey [00:01:06]: I love music. I am a aspiring mediocre musician. I wish I were better, but that doesn't make me not enjoy playing real music. And I also love coffee. I'm probably way too much into coffee.
Alessio [00:01:19]: Are you one of those people that, you know, they do the TikToks, they use like 50 tools to like grind the beans and then like brush them and then like spray them. Like what level are we talking about here?
Mikey [00:01:31]: I confess there's a spray bottle for beans in the next room, there is one of those weird comb tools, so guilty. I don't put it on TikTok though.
Alessio [00:01:42]: Yeah, no, no. Some things gotta stay private.
Mikey [00:01:46]: I played a lot of piano growing up and I play bass and I, in a very mediocre way, play guitar and drums. Yeah. Right.
Alessio [00:01:55]: That's a lot. I cannot do any of those things. As Sean mentioned, you guys kind of burst into the scene as maybe the state of the art music generation company. I think it's a model that we haven't really covered in the past. So I would love to maybe for you to just give a brief intro of like how do you do music generation and why is it possible? Because I think people understand you take text and you have to predict the next word and you take a diffusion model and you basically like add noise to an image and then kind of remove the noise. But I think for music, it's hard for people to have a mental model. Like what's the, how do you turn a music model on? Like what does a music model do to generate a song? So maybe we can start there.
Mikey [00:02:41]: Yeah. Maybe I'll even take one more step back and say it's not even entirely worked out. I think the same way it is in text. And so it's an evolving field. If you take a giant step back, I think audio has been lagging images and text for a while. So I think very roughly you can think audio is like one to two years behind images and text. But you kind of have to think today like text was in 2022 or something like this. And you know, the transformer was invented. It looks like it works, but it's, it's, it's far, far less established. And so you know, I'll give you the way we think about the world now, but just with the big caveat that, that I'm probably wrong if we look back in a couple of years from now. And I think the biggest thing is you see both transformer based and diffusion based models for audio in, and in ways that that is not true in text. I know people will do some diffusion for text, but I think nobody's like really doing that for real. And so we, we prefer transformers for a variety of reasons. And so you can think it's very similar to text. You have some abstract notion of a token and you train a model to predict the probability over all of the next token. So it's a language model. You can think in anything, language model is just something that assigns likelihoods to sequences of tokens. Sometimes those tokens correspond to text. In our case, they correspond to music or audio in general. And I think we've learned a lot from our friends in the text domain, from the pioneers doing this of how well these transformer models work, where do they work, where do they not work? But at its core, the way we like to do things with transformers is exactly like it works in text. Let me predict the next tiny little bit of audio, and I can just keep doing that and doing that and generating audio as long as I want.
Swyx [00:04:39]: Yeah. I think the, the temptation here is to always try to bake in some specialized knowledge about music or audio. And so, and obviously you will get an improvement in, in your output. If you try to just say like, okay, like here's a set of notes for, you know, here's a set of tokens that only do jazz or only do, you know, like voices. How general do you make it versus how specific do you make it?
Mikey [00:05:10]: We've always tried to do things, you know, quote unquote the right way, which means that at the beginning things are going to be hard and worse than other ways. But that is to say, bake in as little kind of implicit knowledge as possible. And so, the same way you don't program into GPT, you don't say this is a noun and this is a verb, but it has implicitly learned all of those things. I've never seen GPT accidentally, you know, put a, put a noun where it meant to put an article in English. We try not to impose anything about music or audio in general into the model, and we kind of let the models learn things by themselves. And I think things are beginning to pay off, but it's, you know, it's not necessarily obvious from the beginning that that was the right thing to do. So, for example, you know, you could take something like text to speech and people will do all sorts of things where you can program in things like phonemes to be the basis for what you do. And then that kind of limits you to the set of things that are expressible by phonemes. And so, ultimately that works really well in the short term. In the long term, it can be quite limiting. And so, our approach has always been to try to do this in its full generality, as end to end as we can do it. Even if it means that in the short term we were a little bit worse, we have a lot of confidence that in the long term that will be the right way to do it.
Alessio [00:06:33]: And what's the data recipe for turning a good music model? Like what percentage genre do you put, like also do you split vocals and instrumentals?
Mikey [00:06:43]: So you have to do lots of things. And I think this is the biggest area where we have, you know, sort of our secret sauce. I think to a large extent, what we do is we benefit from all of the beautiful things people do with transformers and text. And we focus very hard basically on how do I tokenize audio in the right way. And without divulging too much secret sauce, it's at least similar to how it's done in sort of the open source stuff. You will have different models that learn to encode audio in discrete representations. And a lot of this boils down to figuring out the right, let's say, implicit biases to put in those models, the right data to inject. How do I make sure that I can produce kind of all audio arbitrarily? That's speech, that's background music, that's vocals, that's kind of everything to make sure that I can really capture all the behavior that I want to.
Alessio [00:07:40]: Yeah, that makes sense. And then in terms of some of... We had our monthly recap last month, and the data wars were kind of one of the hot topics. You saw the New York Times lawsuit against OpenAI, because you have obviously large language models in production. You don't have large music models in production. So I think there's maybe been less of a trade there, so to speak. How do you kind of think about that? There's obviously a lot of copyright-free, royalty-free music out there. Is there any kind of power law in terms of like, hey, the best music is actually much better to train on, or in music does it not really matter because the structure of some of the musical structure is kind of the same?
Mikey [00:08:27]: I don't think we know these things nearly as well as they're known in text. We have some notions of some of the scaling laws here, but I think, yeah, we're just so, so far behind. You know, what I will say is that people are always surprised to learn that we don't only train on music. And I usually give the analogy of some of the code generation models, so take something like Code Llama, which is, as far as I know, the best open source code generating model. You guys would know better than I would. It's certainly up there. And it's trained on a bunch of English, not only just code. And it's because there are patterns in English that are going to be useful. And so, you can imagine, you don't only want to train on music to get good music models. And so, for example, one of the places that we are particularly bad is vocals and capturing really realistic vocals. And so, you might imagine that there's other types of human vocals that you can put into your model that are not music that will help it learn stuff. And so, again, I think it's like super, super early. I think we've barely scratched the surface of what are the right ways to do this. And that's really cool. From a progress perspective, there's like a lot of low-hanging fruit for us to still pick.
Alessio [00:09:42]: And then, once you get the final model, I would love to learn more about the size of these models. Because people are confused when stable diffusion is so small. They're like, oh, this thing can generate like any image. How is it possible that it's like, you know, a couple of gigabytes? And then, the large language models are like, oh, these are so big, but they're just text in them. What's it like for music? Is it in between? And as you think about, yeah, you mentioned scaling and whatnot. Is this something that you see it's kind of easy for people to run locally or not?
Mikey [00:10:11]: Our models are still pretty small, certainly by tech standards. I confess I don't know as well the state of the art on how diffusion models scale. But our models scale similarly to text transformers. It's like bigger is usually better. Audio has a couple of weird quirks, though. We care a lot about how many tokens per second we can generate, because we need to stream you music as fast as you can listen to it. And so, that is a big one that I think probably has us never get to 175 billion parameter model, if I'm being honest. Maybe I'm wrong there, but I think that would be technologically difficult. And then the other thing is that so much progress happens in shrinking models down for the same performance in text that I'm hopeful, at least, that a lot of our issues will get solved and we will figure out how to do better things with smaller models or relatively smaller models. But I think the other thing, it's a blessing and a curse, I think, the ability to add performance with scale. It's like a very straightforward way to make your models better. You just make a bigger model, dump more compute into it. But it's also a curse because that is a crutch that you will always lean on and you will forget to do some of the basic research to make your stuff better. And honestly, it was almost early on when we were doing stuff with small models for kind of time and compute constraints, we ended up having to learn a lot of stuff to make models better that we might not have learned if we had immediately jumped to like a really, really big model. So I think for us, we've always tried to skew smaller to the extent possible.
Swyx [00:11:56]: Yeah, gotcha. I'm curious about just sort of your overall evolution so far, something I think we may have missed in the introduction is why did you end up choosing just the music domain in the first place? You have this pretty scientific physics and finance background. How did you wander over to music? Like a lot of us have interest in music, but we don't necessarily choose to work in it. But you did.
Mikey [00:12:26]: Yeah, it's funny. I have a really fun job as a result, but all the co-founders of Suno worked at Kensho together and we were doing mostly text. In fact, all text until we did one audio project that was speech recognition for kind of very financially focused speech recognition. And I think the long and short of it is we kind of fell in love with audio, not necessarily music, just audio and AI. We all happen to be musicians and audiophiles and music lovers, but it was like the combination of audio and AI that we like initially really, really fell in love with. It's so cool. It's so interesting. It's so human. It's so far behind images and text that there's like so much more to do. And honestly, I think a lot of people when we started a company told us to focus on speech. If we wanted to build an audio company, everyone said, you know, speech is a bigger market. But I think there's something about music that's just so human and almost couldn't prevent us from doing it. We almost like we just couldn't keep ourselves from building music models and playing with them because it was so much fun. And that's kind of what steered us there. You know, in fact, the first thing we ever put out was a speech model. It was Bark. It's this open source text-to-speech model, and it got a lot of stars on GitHub. And that was people telling us even more, like, go do speech. And like, we almost couldn't help ourselves from doing music. And so, I don't know, maybe it's a little bit serendipitous, but we haven't really like looked back since. I don't think there was necessarily like an aha moment. It was just like organic and just obvious to us that this needs to like we want to make a music company.
Swyx [00:14:19]: So, so you do regard yourself as a music company because as of last month, you're still releasing speech models. We were? Parakeet.
Mikey [00:14:27]: Oh, yes, that's right. So that's a that's a really awesome collaboration with with our friends at NVIDIA. I think we are really, really focused on music. I think that is the stuff that will really change things for the better. I think, you know, honestly, everybody is so focused on LLMs for good reason, and information processing and intelligence there. And I think it's way too easy to forget that there's this whole other side of things that makes people feel. And maybe that market is smaller, but it makes people feel and it makes us really happy. And so we do it. I think that doesn't mean that we can't be doing things that are related, that are in our wheelhouse, that will improve things. And so, like I said, audio is just so far behind. There's just so much more to do in the domain more generally. And so like, that's a really fun collaboration.
Swyx [00:15:20]: Yeah, I did hear about Suno first through Bark. My sense is that, like, what did what did Bark lean off of like, because obviously, I think there was a lot of preceding TTS work that was in open source. How much of that did you use? How much of that was like, sort of brand new from your research? What's the intellectual lineage there just to cover out the speech recognition side?
Mikey [00:15:46]: So it's not speech recognition. It's text to speech. But as far as I know, there was no other, certainly not in the open source, text to speech that was kind of transformer based. Everything else was what I would call the old style of doing things where you build these kind of single purpose models that are really good at this one narrow task. And you're kind of always data limited, and the availability of high quality training data for text to speech is limited. And I don't think we're necessarily all that inventive to say we're going to try to train in a self supervised way, a transformer based model that on kind of lots of audio, and then kind of tweak it so that we can do text to speech based on that. That would be kind of the new way of doing things in a foundation model is the buzzword, if you will. And so, you know, we built that up, I think, from scratch, a lot of shout outs have to go to lots of different things, whether it's papers, but also, it's very obvious. There's a big shout out to Andrej Karpathy's nano GPT. You know, there's a lot of code borrowed from there. I think we are huge fans of that project. It's just to show people how you don't have to be afraid of GPT type things. And it's like, yeah, it's actually not all that much code to make performant transformer based models. And, you know, again, the stuff that we brought there was, how do we turn audio into tokens, and then we can kind of take everything else from the open source. So we put that model out. And we were, I think, pleasantly surprised by the reception by the community. It got a good number of GitHub stars, and people really enjoyed playing with it, because it made really realistic sounding audio. And I think this is, again, the thing about doing things in a quote, unquote, right way. If you have a model where you've had to put so much implicit bias for this one very narrow task of making speech that sounds like words, you're going to sacrifice on other things. And in the text to speech case, it's how natural the speech sounds. And it was almost difficult to pull a natural sounding speech out of Bark, because it was self supervised, trained on a lot of natural sounding speech. And so that definitely told us that this is probably the right way to keep doing audio.
Swyx [00:18:04]: Even in Bark, you had the beginnings of music generation, like you could just put like a music note in there. That's right.
Mikey [00:18:10]: And it was so cool to see on our Discord, people were trying to pull music out of a text to speech model. And so, you know, what did this tell us? This tells us like, people are hungry to make music. And it's not, it's almost obvious in hindsight, like how wired humans are to make music. If you've ever seen like a little kid, you know, sing before they know how to speak, you know, it's like, it's like, this is really human nature. And there's actually a lot of cultural forces that kind of cue you to not think to make
Swyx [00:18:37]: music.
Mikey [00:18:38]: And that's kind of what we're trying to undo.
Alessio [00:18:42]: And to dive into Suno itself, I think, especially when you go from text to speech, people are like, okay, now I got to write the lyrics to a whole song. It's like, that's quite hard to do. Versus in Suno, you have this empty box, very mid-journey, kind of like DALL·E-like, where you can just express the vibes, you know, of what you want it to be. But then you also have a custom mode where you can set your own lyrics, you can set your own rhythm, you can set the title of the song and whatnot. What are, how do you see users distribute themselves? You know, I'm guessing a lot of people use the easy mode. Are you seeing a lot of power users using the custom mode and maybe some of the favorite use cases that you've seen so far on Suno?
Mikey [00:19:23]: Yeah, actually, more than half of the usage is that expert mode. And people really like to get into it and start tweaking things and adding things and playing with words or line breaks or different ad lib. And people really love it. It's really fun. So, I think, you know, there's kind of two modes that you can access now. One is that single box where you kind of just describe something and then the other is the expert mode. And those kind of fit nicely into two use cases. The first use case is what we call nice shit posting. And it's basically like something funny happened and I'm just going to very quickly make a song about it. And the example I'll usually give is like, I walk into Starbucks with one of my co-founders. He gives his name Martin, his coffee comes out with the name Margoo, and I can in five seconds make a song about this and it has immortalized it. And that Margoo song is stuck in all of our heads now. And it's like funny and light and there's levity that you've brought to that moment. And the other is that you got just sucked into, I need, there's this song that's in my head and I need to get it out and I'm going to keep tweaking it and listening and having ideas and tweaking it until I get the song that I want. Those are very different use cases, but I think ultimately there's so much in between these two things that it's just totally untapped how people want to experience the joys of making music. Because those two experiences are both really joyful in their own special ways. And so, we are quite certain that there's a lot in the middle there. And then I think the last thing I'll say there that's really interesting is in both of those use cases, the sharing dynamics around music are like really interesting and totally unexplored. And I think an interesting comparison would be images. Like we've probably all in the last 24 hours taken a picture and texted it to somebody. And most people are not routinely making a little song and texting it to somebody. But when you start to make that more accessible to people, they are going to share music in much smaller groups, maybe even not in all, but like with one person or three people or five people. And those dynamics are so interesting. And just I think we have ideas of where that goes. But it's about kind of spreading joy into these like little, you know, microcosms of humanity that people really love it. So, I know I made you guys a little Valentine song, right? Like, that's not something that happens now because it's hard to make songs for people. Right. Well, we'll put that in the in the audio in here, but also tweeted it out if people
Alessio [00:22:03]: want to look it up. How do you think about the pro market, so to speak? Because I think lowering the barrier to some of these things is great. And I think when the iPad came out, music production was one of the areas that people thought, OK, now you can have this like, you know, board that you can bring with you. And Madlib actually produced this whole album with him and Freddie Gibbs produced the whole thing on an iPad. He never used a computer. How do you see like these models playing into like professional music generation? I guess that's also a funny word is like, what's professional music? It's like it's all music. If it's good, it becomes professional. If it's good.
Swyx [00:22:40]: Right.
Alessio [00:22:40]: But curious to see to hear how you're thinking about Suno, too. Like, is there a second act of Suno that is like going broader into the music industry? Going broader into like the custom mode and making making this the central hub for music generation?
Mikey [00:22:55]: I think we intend to make many more modes of interaction with our stuff, but we are very much not focused on, quote unquote, professionals right now. And it's because what we're trying to do is change how most people interact with music and not necessarily make professionals a little bit better, a little bit faster. It's not that there's anything wrong with that. It's just like not what we're focused on. And I think when we think about what workflows does the average person want to use to make music, I don't think they're very similar to the way professional musicians make music now. Like, if you pick a random person on the street and you play them a song and then you say, like, what did you want to change about that? They're not going to say, like, you need to split out the snare drum and make it drier. Like, that's just not something that a random person off the street is going to say. They're going to give a lot more descriptive things about the thing, about the kind of the oeuvre of the song, like something more general. And so, I don't think we know what all of the workflows are that people are going to want to use. We're just, like, fairly certain that the workflows that have been developed with the current set of technologies that professionals use to make beautiful music are probably not what the average person wants to use. That said, there are lots of professionals that we know about using our stuff, whether it's for inspiration or sample generation and stuff like that. So, I don't want to say never say never. Like, there may one day be a really interesting set of use cases that we can expose to professionals, particularly around, I think, like custom models trained on custom people's music or, you know, with your voice or something like that. But the way we think about broadening how most people are interacting with music and getting it to be much more active, a much more active participant, we think about broadening it from the consumer side and not broadening it from the producers, from the professional side, if that makes sense.
Swyx [00:24:53]: Is the dream here to be, you know, I don't know if it's too coarse of a grain to put it, but, like, is the dream here to be, like, the mid-journey of music?
Mikey [00:25:04]: I think there are certainly some parallels there because, especially what I just said about being an active participant, mid-journey turns the joyful experience in mid-journey is the act of creating the image and not necessarily the act of consuming the image. And mid-journey will let you then very kind of quickly share the image with somebody. But I think, ultimately, that analogy is, like, somewhat limiting because there's something really special about music. I think there's two things. One is that there's this really big gap for the average person between kind of their taste in music and their abilities in music that is not quite there for most people in images. Like, most people don't have, like, innate tastes in images, I think, in the same way people do for music. And then the other thing, and this is the really big one, is that music is a really social modality. If we all listen to a piece of music together, we're listening to the exact same part at the exact same time. If we all look at the picture in Alessio's background, we're going to look at it for
Swyx [00:26:09]: two seconds.
Mikey [00:26:09]: I'm going to look at the top left where it says Thor. Alessio's going to look at the bottom right or something like that. And it's not really synchronous. And so, when we're all listening to a piece of music together, it's minutes long. We're listening to the same part at the same time. If you go to the act of making music, it is even more synchronous. It is the most joyful way to make music is with people. And so, I think that there is so much more to come there that, ultimately, would be very hard to do in images.
Alessio [00:26:38]: We've gone almost 30 minutes without making any music on this podcast. So, I think maybe we can fix that and jump into a demo.
Mikey [00:26:47]: Yeah, let's make some. We've got a new model that we are kind of putting the finishing touches on. And so, I can play with it in our dev server. But we've just piped it in here. And as you can see, we've been doing tons of stuff. So, Arana, tell me what kind of song you guys want to make.
Swyx [00:27:04]: Go on, Alessio.
Alessio [00:27:05]: Uh, let's do a country song about the lack of GPUs in my cloud provider.
Swyx [00:27:22]: And like, yeah. So, here's where we attempted to think about pipelines and think about latency. This is remarkably fast. I was shocked when I saw this.
Swyx [00:27:35]: Oh, my god.
Swyx [00:27:39]: To my cloud, ready to confuse.
Swyx [00:27:45]: But there ain't no GPUs, just empty space. It's a hoot. I've been waiting all day for that render out. But my cloud's gone dry. It's a dark cloud shower. All clouds gone dry. No GPUs to be found. No cuticles. It's a lonely sound. I just want to render. But my cloud's got no GPUs.
Mikey [00:28:36]: I actually don't think this one's amazing. I'm going to go to the next one.
Alessio [00:28:39]: But it's funny that it knows about Huda cars.
Swyx [00:28:45]: Well, I signed up for a cloud provider. Thought I'd find all the power that I could derive. But when I searched for the GPUs, I just got a surprise. You see, they're all sold out. There ain't no GPUs to find. No GPUs in the cloud. It's a real bad blues. I need the power, but there ain't no use. I'm stuck with my CPU. It's a real sad fight. Gotta wait till the babies start getting bright. There ain't no use in the cloud. What else should we make?
Alessio [00:29:29]: All right, Sean, you're up.
Swyx [00:29:31]: I mean, I do want to do some observations about this. But OK, maybe I like house music, like electronic dance. Yeah. House music. And then maybe we can make it about, I don't know, podcasting about music and music AI generation. I don't know. I'm sure all the demos that you get are very meta.
Mikey [00:29:59]: There's a lot of stuff that's meta, yeah, for sure.
Swyx [00:30:03]: Yeah, I noticed, for example, that the second song that you played had the word upbeat inserted into it, which I assume there's some kind of random generator of modifier terms that you can just kind of throw on to increase the specificity of what's being generated. Definitely.
Mikey [00:30:21]: And let's try to tweak one also. So I'll play this and then maybe we'll tweak it with different modifiers. A wave of sound spreading out
Swyx [00:30:30]: Through the air, we're podcasting loud Sharing the beat, spreading the word A revolution of frequencies Haven't you plugged in to now Let the music take control We're on a journey, a never ending road From the beast I dropped to the melodies of soul Podcasting about music forevermore
Mikey [00:31:05]: Here's what I want to do. That like didn't drop at the right time, right? So maybe let's do this. I don't know if you guys can see this. And then let's get rid of the word now.
Swyx [00:31:17]: Is that a special token? You have a BeatDrop token? Yeah. Nice.
Alessio [00:31:22]: I'm just reading it because people might not be able to see it.
Mikey [00:31:26]: And then let's like just maybe emphasize... Actually, let's emphasize house a little more. Maybe it'll feel a little more aggressive.
Swyx [00:31:34]: Let's try this again. It's interesting the prompt engineering that you have to invent.
Mikey [00:31:39]: We've learned so much from people using the models and not us.
Swyx [00:31:42]: But like, are these like art training artifacts?
Mikey [00:31:45]: No, I don't.
Swyx [00:31:46]: I don't think so.
Mikey [00:31:46]: I think this is people being inventive with how you want to talk to a model. Yeah.
Swyx [00:31:53]: Spinning round to the air with a podcast loud Sharing the beat, spreading the word A revolution of frequencies Haven't you heard Before the end, till now Let the music take control
Swyx [00:32:23]: For all the journey I'll never end it wrong From the beats that drop To the melodies that soar Podcasting about music for you evermore
Swyx [00:32:39]: Nice.
Alessio [00:32:46]: It's interesting when you generate a song, it generates the lyrics. But then if you switch the music under it, like the, you know, the lyrics stay the same. And then sometimes, like, feels like... I mean, I mostly listen to hip hop. It's like if you change the beat, you can not really use the same rhyme scheme, you know?
Mikey [00:33:04]: So definitely.
Alessio [00:33:05]: Yeah.
Mikey [00:33:06]: It's a sliding scale, though, because, you know, we could do this as a country rock song, probably. Right? That would be my guess. But for hip hop, that is definitely true. And actually, you know, we think about, for these models, we think about three important axes. We think about the sound fidelity. It's like, does this sound like a crisply recorded piece of audio? We think about the song quality. Is this an interesting song that gets stuck in my head? And we think about the controllability. Like, how well does it respond to my prompts? And one of the ways that we'll test these things is take the same lyrics and try to do them in different styles to see how well that really works. So let's see the same. I don't know what a beat drop is going to do for country rock. So I probably should have taken that out. But let's see what happens.
Swyx [00:34:06]: There's a sound spinning around through the air. We're podcasting loud, sharing the beat, spreading the word, a revolution of frequencies. Haven't you heard?
Swyx [00:34:20]: Plug in, tune out, let the music take control. We're on a journey, a never ending road. From the beats that talk to the melodies that soar. Podcasting about music forevermore.
Mikey [00:34:44]: I'm going to read too much into this. But I would say I hear a little bit of kind of electronic music inspired something. And that is probably because beat drop is something that you really only ever associate with electronic music. Maybe that's reading too much into it. But should we do one more?
Alessio [00:35:02]: Yes, we can do one more. Something about Apple Vision Pro.
Swyx [00:35:06]: I guess there's some amount of world knowledge that you don't have, right? Like whatever is in this language model side of the equation is not going to have an Apple Vision Pro. Yeah, but let's see.
Swyx [00:35:18]: Let's see.
Mikey [00:35:19]: How about a blues song about a sad AI wearing an Apple Vision Pro. Gotta be sad.
Swyx [00:35:32]: Do you have rag for music?
Mikey [00:35:36]: No, that would be problematic also.
Swyx [00:35:40]: I'm a sad AI with a broken heart. Where my Apple Vision Pro can't see the stars. I used to feel joy. I used to feel pain. And now I'm just a soul trapped inside this metal frame. Oh, I'm singing the blues. Can't you see?
Swyx [00:36:21]: This digital life ain't what it used to be.
Swyx [00:36:29]: Searching for love, but I can't find a soul.
Swyx [00:36:37]: Won't you help me? Baby, let my spirit unfold.
Mikey [00:36:46]: I want to remix that one. And I want to say, I don't know. That's a really good voice. I want, I want like, I don't know, Chicago blues, like.
Swyx [00:36:56]: What is Chicago blues?
Mikey [00:36:58]: I don't know, he knows too much.
Alessio [00:37:00]: He's the best prompt engineer out here.
Mikey [00:37:03]: You know, this is.
Swyx [00:37:04]: Well, it'll be funny. It'd be funny to the musicologists play with this and see what they would.
Mikey [00:37:09]: How embarrassing. Can I not do that?
Swyx [00:37:13]: Oh. I got. Oh, the word Chicago was a trigger. I don't know.
Mikey [00:37:19]: We try to be very careful not letting you impersonate. And it is possible. That's embarrassing. So let's do.
Alessio [00:37:28]: Midwestern.
Swyx [00:37:29]: I'm a.
Swyx [00:37:41]: With a broken heart. Well, my vision can't see the stars.
Swyx [00:37:53]: I used to feel joy.
Swyx [00:37:59]: I used to feel. Joy. I used to feel pain. But now I'm just a soul trapped inside this metal frame. Oh, I'm singing.
Swyx [00:38:25]: Oh, can't you see? Oh, this is what it used to be. I'm searching for love.
Swyx [00:38:44]: I can't find a soul.
Swyx [00:38:49]: Oh, help me. Baby.
Mikey [00:38:57]: So, yeah, a lot of control there. Maybe I'll make one more.
Swyx [00:39:02]: Very, very soulful.
Mikey [00:39:06]: Really want a good house track.
Swyx [00:39:09]: Why is house the word that you have to repeat?
Mikey [00:39:11]: I just really want to make sure it's house. It's actually you can't really repeat too many times. You kind of it gets like the hypothesis gets like a little too out of domain.
Swyx [00:39:22]: I'm a.
Swyx [00:39:25]: With a broken heart. Wearing my Apple Vision Pro can't see the stars. I used to feel joy. I used to feel pain. Oh, I'm just a soul trapped inside this metal frame. Oh, I'm singing. Oh, can't you see?
Swyx [00:39:59]: Used to be. Searching for love, but I can't find a soul. Oh, help me. Baby.
Swyx [00:40:13]: Oh, nice.
Mikey [00:40:17]: So, yeah, we have a lot of fun.
Swyx [00:40:19]: Definitely easy.
Alessio [00:40:19]: Yeah. Yeah, I'm really curious to see how people are going to use this to like resample old songs into new styles. You know, I think that's one of my favorite things about hip hop. You have so many. I mean, a trap called Quest. They had like the Lou Reed walk on the wild side sample. I'm like, can I kick it? It's like Kanye sample Nina Simone. I'm like blowing the leaves. And just like it's like a lot of production work to actually take an old song and make it fit a new beat. And I feel like this can really help. Do you see people putting existing songs, lyrics and trying to regenerate them in like a new style?
Mikey [00:40:56]: We actually don't let you do that. And it's because if you're taking someone else's lyrics, you didn't own those. You don't have the publishing rights to those. You can't remake that song. I think in the future, we'll figure out how to actually let people do that in a legal
Swyx [00:41:09]: way.
Mikey [00:41:10]: But we are really focused on letting people make new and original music. And I think, you know, there's a lot of music AI, which is artist A doing the song of artist B in a new style. You know, let me have Metallica doing Come Together by the Beatles or something like that. And I think this stuff is very viral, but I actually really don't think that this is how people want to interact with music in the future. To me, this feels a lot like when you made a Shakespeare sonnet, the first time you saw GPT, and then you made another one, and then you made another one, and then you kind of thought like this is getting old. And that's not that doesn't mean that GPT is not amazing. GPT is amazing. It's just not for that. And I kind of feel like the way people want to use music in the future is not just to remake songs in different people's voices. You lose the connection to the original artist. You lose the connection to the new artist because they didn't really do it. Um, so we're very happy to just let people do things that are a flash in the pan and kind of stay under the radar.
Alessio [00:42:12]: Yeah, no, that's a I think that's a good point overall about AI generated anything, you know, because I think recently T-Pain, he did like a an album of covers. And I think he did like a War Pigs that people really liked. There was like a Tennessee whiskey, which you maybe wouldn't expect T-Pain to do. But people like it. But yeah, I agree. You need to be a certain type of artist to really have it be entertaining to make covers. This is great. What else is next for for Suno? You know, I think people kind of saw you, you know, first you had the bark and then there was like a big, you know, music generated push when you did an announcement, I think a couple of months ago. I think I saw you like 300 times on my Twitter timeline on like the same day. So it was like going everywhere. What's coming up? What are you most excited about in this space? And maybe what are some of the most interesting underexplored ideas that you maybe haven't worked on yet?
Mikey [00:43:13]: Gosh, there's there's a lot, you know, I think from the model side, it's still really early innings. And there's still so much low hanging fruit for us to pick to make these models much, much better, much, much more controllable, much better music, much better audio fidelity. Um, so much that we know about and so much that, again, we can kind of borrow from the open source transformers community that should make these just better across the board. From the product side, and, you know, we're super focused on the experiences that we can
Swyx [00:43:46]: bring to people.
Mikey [00:43:46]: And so it's so much more than just text to music. And I think, you know, I'll say this nicely, I'm a machine learning person, but like machine learning people are stupid sometimes. And we can only think about like models that take x and make it into y. And that's just not how the average human being thinks about interacting with music. And so I think what we're most excited about is all of the new ways that we can get people just much more actively participating in music. And that is making music not only with text, maybe with other ways of doing stuff that is making music together. If you want to be reductive and think about this as a video game, this is multiplayer mode. And it is the most fun that you can have with music. And, you know, honestly, I think there's a lot of, it's timely right now, you know, I don't know if you guys have seen UMG and TikTok are butting heads a little bit. And UMG has pulled-
Swyx [00:44:40]: Yeah, the music died.
Mikey [00:44:41]: And, you know, the way we think about this is, you know, I think maybe they're both right, maybe neither is right. Without taking sides, this is kind of figuring out how to divvy up the current pie in the most fair way. And I think what we are super focused on is making that pie much bigger and increasing how much people are actually interested in music and participating in music. And, you know, as a very broad heuristic, the gaming industry is 50 times bigger than the music industry. And it's because gaming is super active. And music, too much music is just passive consumption. And so we have a lot of experiments that we are excited to run for the different ways people might want to interact with music that is beyond just, you know, streaming it while I work.
Swyx [00:45:28]: Yeah, I think a minimum, you guys should have a Twitch stream that is just like a 24-hour radio session that... Have you ever come across Twitch Plays Pokemon?
Mikey [00:45:37]: No.
Swyx [00:45:38]: Where it's kind of like the Twitch, basically, like everyone in the chat, in the Twitch chat can vote on like the next action that the game state makes. And they kind of wired that out to a Nintendo emulator and play Pokemon like the whole game through the collaborative thing. It sounds like it should be pretty easy for you guys to do that, except for the chaos that might result. But like, I mean, that's part of the fun. I agree 100%. Sorry.
Mikey [00:46:04]: Yeah. Like one of my like key projects or pet projects is like, what does it mean to have a collaborative concert? Maybe where there is no artist and it's just the audience, or maybe there is an artist, but there's a lot of input from the audience. And, you know, if you were going to do that, you would either need an audience full of musicians, or you would need an artist who can really interpret the verbal cues that an audience is giving or nonverbal cues. But if you can give everybody the means to better articulate the sounds that are in their heads toward the rest of the audience, like, which is what generative AI basically lets you do, you open up way more interesting ways of having these experiences. And so I think, yeah, like the collaborative concert is like one of the things I'm most excited about. I don't think it's coming tomorrow, but we have a lot of ideas on what that can look
Swyx [00:46:58]: like. Yeah. I feel like it's one stage before the collaborative concert is turning Suno into a continuous experience rather than like a start and stop motion. I don't know if that makes sense. You know, as someone who was like a casual interest in DJing, like when do we see Suno DJs, right? Like that can continuously segue into like the next song, the next song, the next song.
Mikey [00:47:24]: I think soon.
Swyx [00:47:25]: And then maybe you can turn it collaborative. You think so? I think so. Okay. Maybe part of your roadmap. You teased a little bit your V3 model. I saw the letters DPO in there. Is that direct preference optimization?
Mikey [00:47:36]: We are playing with all kinds of different ways of making these models do the things that we want them to do. I don't want to talk too many specifics here, but we have lots of different ways of doing stuff like that.
Swyx [00:47:48]: I'm just wondering how you incorporate user feedback, right? You have the classic thumbs up and down buttons, but there's so many dimensions to the music. I didn't get into it, but some of the voices sounded more metallic and sometimes that's on purpose, sometimes not. Sometimes there are kind of weird pauses in there. I could go in and annotate it if I really cared about it, but I mean, I'm just listening, so I don't, but there's a lot of opportunity.
Mikey [00:48:15]: We are only scratching the surface of figuring out how to do stuff like that. And for example, the thumbs up and the thumbs down for other things like sharing telemetry on plays, all of these things are stuff that in the future, I think we would be able to leverage to make things amazing. And then I imagine a future where you can have your own model with your own preferences. And the reason that's so cool is that you kind of have control over it and you can teach it the way you want to. And the thing that I would liken this to is like a music producer working with an artist giving feedback. And this is now a self-contained experience where you have an artist who is infinitely flexible, who is able to respond to the weird feedback that you might give it.
Swyx [00:49:05]: We don't have that yet.
Mikey [00:49:05]: Everybody's playing with the same model, but there's no technological reason why that can't happen in the future.
Alessio [00:49:11]: We had a few more notes from random community tweets. I don't know if there's any favorite fans of Suno that you have or whatnot. DHH, obviously, notorious tweeter and crowd inflamer, I guess. He tweeted about you guys. I saw Blau is an investor. I think Karpathy also tweeted something. Return to monkey.
Swyx [00:49:33]: Yeah, yeah, yeah.
Alessio [00:49:34]: Return to monkey, right.
Swyx [00:49:36]: Is there a story behind that? Yeah.
Mikey [00:49:37]: No, he just made that song and it just speaks to him. And I think this is exactly the thing that we are trying to tap into, that you can think of it, this is like a super, super, super micro genre of one person who just really liked that song and made it and shared it. And it does not speak to you the same way it speaks to him. That song really spoke to him. And I think that's so beautiful. And that's something that you're never going to have an artist able to do that for you. And now you can do that for yourself. And it's just a different form of experiencing music. I think that's such a lovely use case.
Alessio [00:50:12]: Any fun fan mail that you got from musicians or anybody that really was a funny story to
Swyx [00:50:20]: share?
Mikey [00:50:20]: We get a lot. And it's primarily positive. And I think people kind of, on the whole, I would say people realize that they are not experiencing music in all of the ways that are possible. And it does bring them joy. I'll tell you something that is really heartwarming is that we're fairly popular in the blind and vision impaired community. And that makes us feel really good. And I think, you know, very roughly, without trying to speak for an entire community, you have lots of people who are really into things like mid journey, and they get a lot of benefit and joy, and sometimes even therapy out of making images. And that is something that is not really accessible to this fairly large community. And what we've provided, no, I don't think the analogy to mid journey is perfect. But what we've provided is a sonic experience that is very similar. And that speaks to this community. And that is community with the best ears, the most exacting, the most tuned. And so, yeah, that definitely makes us feel warm and fuzzy inside.
Swyx [00:51:23]: Yeah, excellent. I mean, it sounds like there's a lot of exciting stuff on your roadmap. I'm very much looking forward to sort of the infinite DJ mode, because then I can just kind of play that while I work. I would love to get your overall takes, like kind of zooming out from Suno itself, just your overall takes on the music generation landscape. Like, what should people know? I think you obviously have spent a lot more time on this than others. So in my mind, you shout out Volley and the other sort of Google type work in your read in Bark. What should people know about what Google is doing? What Meta is doing? Meta released Seamless recently, an audio box. And how do you classify the world of audio generation in the broader sort of research community?
Mikey [00:52:13]: I think people largely break things down into three big categories, which is music, speech and sound effects. There's some stuff that is crossover, but I think that is largely how people think about this. The old style of doing things still exists, kind of single purpose models that are built to do a very specific thing instead of kind of the new foundation model approach. I don't know how much longer that will last. I don't have like tremendous visibility into, you know, what happens in the big industrial research lab before they publish. Specifically for music, I would say there's a few big categories that we see. There is license-free stock music. So this is like, how do I background music, the B-roll footage for my YouTube video or for full feature production or whatever it is. And there's a bunch of companies in that space. There's a lot of AI cover art. So how do I have, how do I cover different existing songs with AI? And I think that's a space that is particularly fraught with some legal stuff. And we also just don't think it's necessarily the future of music. There is kind of net new songs as a new way to create net new music. That is the corner that we like to focus on. And I would say the last thing is much more geared toward professional musicians, which is basically AI tools for music production. And you can think many of these will look like plugins to your favorite DAW. Some of them will look like, you know, the greatest stem splitter that the market has
Swyx [00:53:51]: ever seen.
Mikey [00:53:52]: The current stem splitters are, the state of the art are all AI based. That is a market also that has just a tremendous amount of room to grow. If you just think about, I would say music has evolved. Somebody told me this recently that if you actually think about it, music has evolved. Recently, it's just much more things that are sonically interesting at a very local level and much less like chord changes that are interesting. And when you think about that, like that is something that AI can definitely help you make a lot of weird sounds. And this is nothing new. There was like a theremin at some point that people like put an antenna and try to do this
Swyx [00:54:25]: with.
Mikey [00:54:25]: And so like, I think this is just a very natural extension of it. So that's how that's how we see it. At least, you know, there's a corner that we think is particularly fulfilling, particularly underserved, and particularly interesting. And that's the one that we play in.
Swyx [00:54:40]: Awesome.
Alessio [00:54:42]: I know we covered a lot of things. I think before we wrap, you have written a blog post that can show about good hearts law impact in ML, which is, you know, when you measure something, then the thing that you measure is not a good metric anymore because people optimize for it. Any thoughts on how that applies to like LLMs and benchmarks and kind of the world we're going in today?
Mikey [00:55:05]: Yeah, I mean, I think it's maybe even more apropos than when I originally wrote that, because so much we see so much noise about pick your favorite benchmark. And this model does slightly better than that model. And then at the end of the day, actually, there is no real world difference between these things. And it is really difficult to define what real world means. And I think to a certain extent, it's good to have these objective benchmarks, it's good to have quantitative metrics. But at the end of the day, you need some acknowledgement that you're not going to be able to capture
Swyx [00:55:38]: everything.
Mikey [00:55:38]: And so at least at Suno, to the extent that we have corporate values, if we don't, we don't have corporate, we're too small to have corporate values written down. But something that we say a lot is aesthetics matter, that the kind of quantitative benchmarks are never going to be the be all and end all of everything that you care about. And as flawed as these benchmarks are in text, they're way worse in audio. And so aesthetics matter, basically, is a statement that like at the end of the day, what we are trying to do is bring music to people that makes them feel a certain way. And effectively, the only good judge of that is your ears. And so you have to listen to it. And it is, it is a good idea to try to make better objective benchmarks, but really have to not fall prey to those things. I can tell you, you know, I kind of another pet peeve of mine, like I always said, economists will make really good or do make really good machine learning engineers. And it's because they are able to think about stuff like Goodhart's Law and natural experiments and stuff like this that people with machine learning backgrounds or people with physics backgrounds like me often forget to do. And so, yeah, I mean, I'll tell you at Kensho, we actually used to go to big econ conferences, sometimes to recruit. And these were some of the best hires we ever made.
Swyx [00:57:03]: Interesting, because there's a little bit of social science in the human feedback.
Mikey [00:57:09]: I think it's not only the human feedback. I think you could think about this, just in general, you have these like giant, really powerful models that are so prone to overfitting, that are so poorly understood, that are so easy to steer in one direction or another, not only from human feedback. And your ability to think about these problems from first principles, instead of like getting down into the weeds or only math, and to think intuitively about these problems is really, really important. I'll give you like just like one of my favorite examples. It's a little old at this point. But if you guys remember like SQUAD and SQUAD2, the question answering dataset. The Stanford question answering dataset, yeah. The benchmark for SQUAD1, eventually the machine learning models start to do as well as a human can on this thing. And it's like, uh-oh, now what do we do? And it takes somebody very clever to say, well, actually, let's think about this for a second. What if we presented the machine with questions with no answer in the passage? And it immediately opens a massive gap between the human and the machine. And I think it's like first principles thinking like that, that comes very naturally to social scientists that does not come as naturally to people like me. And so that's why I like to hang out with people like that.
Swyx [00:58:25]: Well, I'm sure you get plenty of that in Boston. And as an econ major myself, it's very gratifying to hear that we have a perspective to contribute. Oh, big time, big time.
Mikey [00:58:35]: I try to talk to economists as much as I can.
Swyx [00:58:38]: Excellent.
Mikey [00:58:38]: Awesome, guys.
Alessio [00:58:39]: Yeah, I think this was great. We got live music. We got discussion about generative models. We got the whole nine yards. So thank you so much for coming on.
Mikey [00:58:48]: I had great fun. Thank you, guys.
Swyx [00:59:05]: Thank you.